DataDirectとBig Data Frameworksで実現できること
オムニチャネルのデータ接続とHadoop、Sparkへのデータ取得
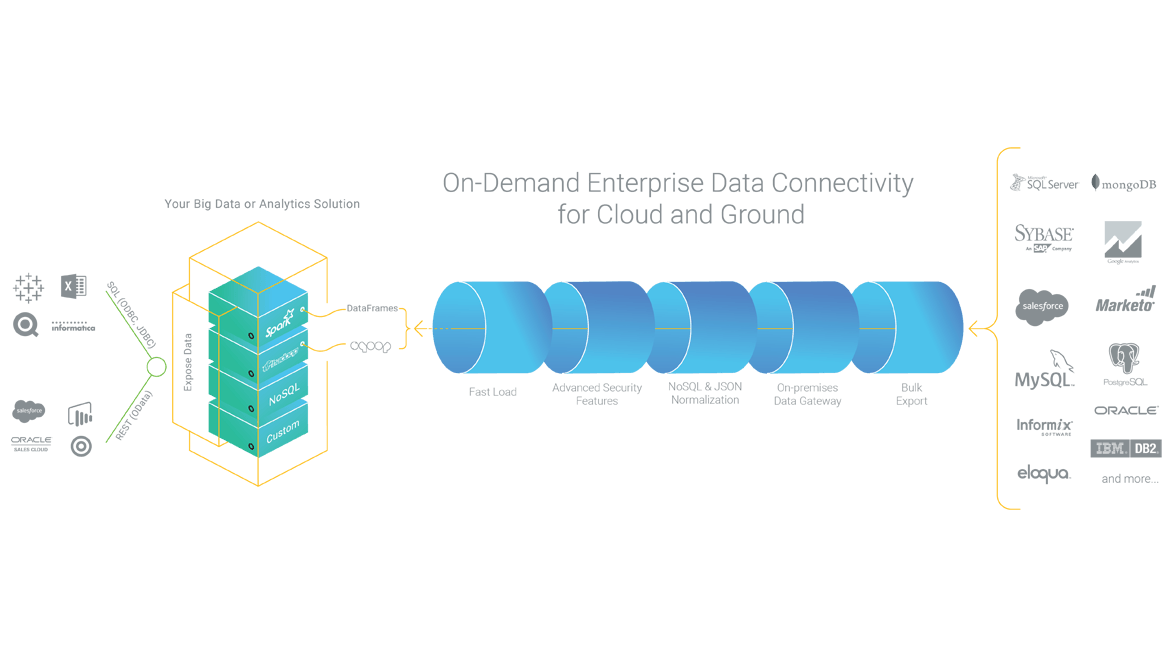
あらゆるプラットフォーム間でのビッグデータ接続を可能にするODBC・JDBCのフルスイート
すべてのHadoop Hive、Spark SQLディストリビューションに対応します。HiveやSpark SQLの新バージョンにも完全対応しています。
バルクデータ取得とApache Sqoopへのエクスポート
リレーショナルデータベースからクラウドアプリケーションなど主要なデータソースのデータをSqoop製JDBCコネクターから取得します。また、DataDirect Bulk Load with Sqoopによって、データのバルクエクスポートも可能です。"EnableBulkLoad"のプロパティ値を0から1に変更するだけでJDBC接続を切り替え、主要なデータソースにエクスポートできます。
Apache Sqoopのロード/エクスポートに対応する主要なデータソース:
Apache Sqoopでクラウドデータレイクを構築
(すぐ利用可能な)SaaSのデータソースからデータをApache Sqoopに取り込み、ビジネスの中心であるカスタマーエクスペリエンスやマーケティングオートメーションシステムの分析に役立てます。詳細はApache Sqoop Connector Guideを参照ください。
Apache Sqoopにデータロードできる主要なクラウドサービス/SaaS:
Apache Sparkからオンデマンドで業務データに接続
JDBCコネクタで意思決定を加速化します。Apache Spark 1.3にJDBCデータソースAPIを導入しておけば、強力なJDBCドライバがリレーショナルデータベース、クラウド、SaaS、NoSQLなどあらゆるデータソースのデータを一元化します。
Apache Sparkに対応する主要データソース:
Odataによるハイブリッドな接続でビッグデータが一般的に
企業ファイアウォールを越えるデータベースドライバや技術がなくても、すぐに接続できるOdataによってビッグデータを企業内においたままで可視化します。Odataエコシステムには、Salesforce、oracle service Cloudなどの主要なクラウドアプリケーションと、TableauやMicrosoft PowerBIなどの分析ツールが含まれます。
Video

- Sparkとのデータ連携
- Spark環境と接続する、JDBC Apache Sqoop、ODBC SparkSQL、Salesforce Spark Dataframesの3つのパターンのデモをご覧いただけます。
Blog
Webinar
お客様事例

- 全世界で企業向けソフトウェア・プラットフォームを提供するリーディング・カンパニーのMicroStrategy社では、セールスフォースやApache Hiveといった新種のデータソースにダイレクトアクセスしたいという顧客要望に応え、市場のリーダシップを維持する必要があった。
- 全ての事例を見る
データ接続ソリューション
160カ国以上、10,000を超える企業がDataDirectを使用しています。
これには、Fortune 100の96社と世界中の350を超えるISVが含まれます。
特集