
















- Oracle Database
【Oracle Database】FAQで安定運用に貢献!サポートセンターのナレッジ公開の取り組み
アシストオラクルサポートセンターが公開しているFAQは、仕様に関するQAやエラー発生時の対処方法などはもちろん、不具合情報や障害発生時の情報取得方法といった安定運用に役立つ内容も扱っています。そのFAQをどのように作成しているのか、サポートセンターの取り組みをご紹介します。
![]()






|
|
StatspackはOracle Database 8iから提供されているデータベース性能診断ツールです。追加費用なし、かつエディションの制限なしに利用可能なため、だれでも使用できます。リリースから10年以上が経過していることもあり、一般サイトやメーカー公開情報でもStatspackレポートの一般的な見方や読み解くポイントなどの情報が数多く紹介されています。今回はそうした情報ではあまり触れられないワンランク上の活用方法や運用上の注意点をご紹介します。
Statspackはデータベースの稼働統計をレポーティングするツールです。デフォルトではインストールされていないため、使用に当たってはまずインストール作業が必要です。インストール手順はOracle Database構築済み環境の$ORACLE_HOME/rdbms/admin配下に配置されているspdoc.txtに記載されています。このドキュメントを参照してインストールを行ってください。
Statspackでレポーティングするためには、前段階としてSnapshot(スナップショット)と呼ばれる情報を取得・保存しておく必要があります。Snapshotは、取得時点でのデータベースの稼働情報です。レポートでは、任意の2つの時点のSnapshotを指定し、それらの差分から該当時間帯のデータベースの稼働統計を出力します。30分~1時間程度の定期的な間隔でSnapshotを取得・保存しておき、確認したい時間帯のレポートを出力して稼働状況を確認したり、パフォーマンス問題の調査に用いるといった運用が一般的です。
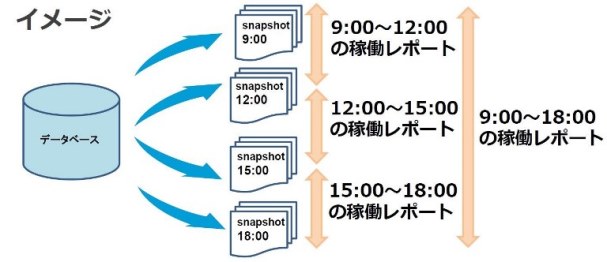
図1はStatspackレポートの取得イメージです。9:00~18:00の間で3時間置きにSnapshotを取得した場合の例です。この場合9:00~12:00、12:00~15:00といった単体のSnapshot間でのレポート出力も可能ですが、9:00~18:00の範囲のように複数のSnapshotを跨いだレポート出力も可能です。
|
図1:Statspackレポートの取得イメージ |
Statspackレポートの出力方法は以下の通りです。
|
|
Statspackレポートの一般的な見方についてはインターネット上にも多数情報が公開されていますので、詳細はそちらに譲るとして、今回はStatspackのさらなる活用方法や実運用上の注意点を紹介します。
※以下の記事でStatspackとV$ビューを組み合わせたトラブル調査方法も紹介していますので、併せてご参照ください。
「Oracle Databaseのパフォーマンスダウン発生に備えたV$ビューの定期取得と調査方法」
Statspackレポートでは該当時間帯に実行されたSQLが負荷の高い順に表示されます。図2はディスク読込みの多いSQLのリストを抜粋したものです。ここではselect文とdeclareで始まるPL/SQLが表示されていますので、レポート出力した時間帯ではこの2つのSQLのディスク読込みが多かったことが確認できます。
|
図2:StatspackレポートのSQL ordered by Readsの出力 |
ただし、このSQLのリストにはデータベースで実行されるすべてのSQLが表示されるわけではなく、しきい値を超えたSQLのみが表示対象になります。このしきい値はStatspackのパラメータで指定可能であり、デフォルト値は以下の通りです。
| しきい値の内容 | パラメータ | デフォルト値 |
|---|---|---|
| SQL実行回数 | i_executions_th | 100 |
| ディスク読込回数 | i_disk_reads_th | 1,000 |
| パース発生回数 | i_parse_calls_th | 1,000 |
| Buffer読込回数 | i_buffer_gets_th | 10,000 |
| 共有メモリの合計使用量 | i_sharable_mem_th | 1,048,576 |
| 子カーソルの数 | i_version_count_th | 20 |
しきい値パラメータはユーザ側で設定変更が可能です。例えばデータベースの運用状況を考慮して、もう少し負荷の低いSQLも表示したい場合はしきい値を下げる、表示されるSQLが多すぎる場合はしきい値を上げる、といったユーザに適した出力内容に微調整が可能です。
しきい値の変更は以下のコマンドで行います。この例ではディスク読込回数のしきい値を500に設定しています。ディスク読込回数のしきい値パラメータは表1に記載したi_disk_reads_thですので、このパラメータを引数に渡して実行しています。しきい値変更はコマンド実行後に取得したSnapshotから有効となります。
|
|
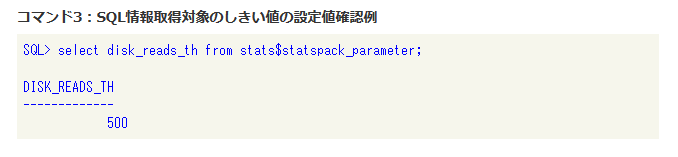
しきい値が正しく変更されているかは以下のコマンドで確認可能です。
|
|
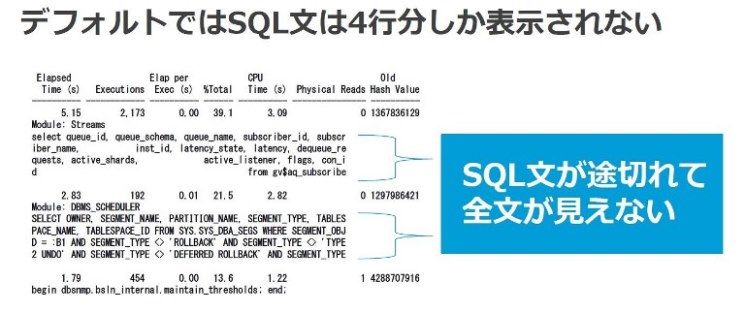
レポートに出力されるSQLは、デフォルトでは以下のように4行分のSQLテキストしか表示されません。そのため、SQLテキストが非常に長い場合はSQL全文を確認できず、どの処理かの判別が困難になることがあります。
|
図3:StatspackレポートのSQL情報抜粋 |
この表示行数もユーザ側で設定変更可能です。設定変更するためには以下のファイル内に記載されているnum_rows_per_hashパラメータを直接編集します。
|
|
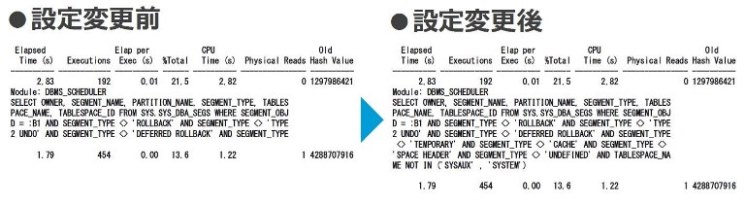
図4が表示行数変更前後のレポート出力の比較です。出力されているSQLテキストの行数が増えていることがわかります。
|
図4:SQL表示行数変更前後の出力例 |
Snapshotは取得レベルに応じて収集される情報が変わります。デフォルトではレベル5で取得されるように設定されています。取得済みSnapshotのレベルはstats$snapshotのsnap_level列から確認可能です(図5参照)。
|
図5:取得済みSnapshotの確認例 |
このSnapshot取得レベルを上げることで、追加の情報取得が可能になります。SnapshotレベルはStatspackインストール後でも変更可能です。変更はStatspackパッケージのsnapプロシージャで行います。i_snap_levelの引数に設定したいレベルを指定して実行します。コマンド実行後から、指定されたレベルでSnapshotが取得されるようになります。
|
|
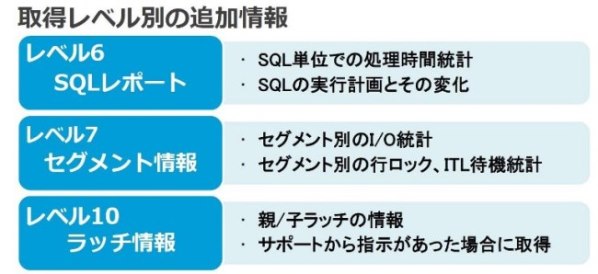
取得レベルはデフォルトの5以外にもレベル6、7、10の3段階が用意されています(図6参照)。
|
図6:Snapshotレベル別の追加情報 |
ただし、レベル10に関してはSnapshot取得にリソースを大量に消費するため、原則Oracle Database製品のサポートより指示があった場合のみ使用してください。今回はレベル6と7で取得される情報を紹介します。
レベル6でSnapshotを取得している場合、新たに「SQLレポート」と呼ばれるSQL単位の詳細情報が確認できるようになります。本文でこれまでご紹介してきた「Statspackレポート」とはDBインスタンス全体のレポートで、ここで紹介するSQLレポートはStatspackレポートとは別に出力されます。SQLレポートの出力方法は以下の通りです。
|
|
sprepsql.sqlを実行時にはSnapshotの範囲指定とSQLのHash Value値の入力が求められます。入力プロンプトの出力例を以下に記載します。
|
|
Snapshotの範囲指定では取得済みのSnapshotのどの範囲からSQLの情報を出力させるかを指定します。コマンド5実行例の※1に指定範囲の始点となるSnapshot Id、※2に終点となるSnapshot Idを指定します。また、SQLのHash ValueはSQLを一意に識別する値であり、Statspackレポートから確認可能です。Statspackレポートで出力されるSQLリストの情報の右端の列にOld Hash Valueという値があり、これがSQLレポート出力時に指定するHash Valueにあたります(図7参照)。Hash Valueの値はコマンド5実行例の※3の箇所に入力します。コマンド5実行例では、Snapshot Id:936~937を範囲指定し、Hash Value値:1367836129を指定して実行しています。
|
図7:Hash Valueの確認方法 |
まず、Statspackレポートを出力し、その中で表示されている負荷の高いSQLをより詳しく確認したい場合にはOld Hash Valueを確認して、SQLレポートを取得する、といった流れが一般的です。
SQLレポートで着目したいポイントの一つは実行計画の変化です。
SQLのパフォーマンスで重要な要素となるのは、実行計画が適切であるかという点です。実行計画はOracle Databaseが内部的に自動で生成しますが、SQLの構文やSQLの処理対象テーブルのデータ内容、データ量、索引の有無など様々な要素を考慮して生成されます。急激なSQLのパフォーマンス遅延が発生した場合には、実行計画が変化して不適切になっている可能性があります。SQLレポートではこの実行計画の変化を確認することができます。
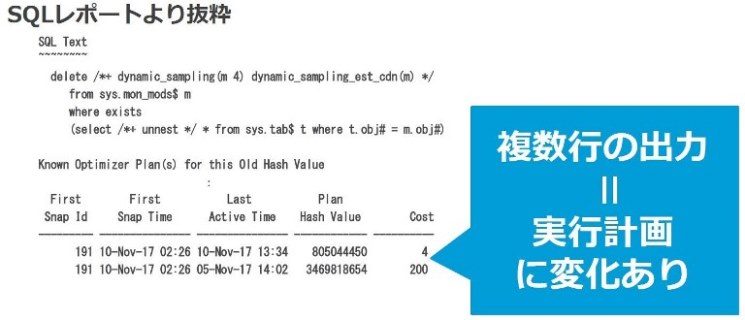
実行計画の変化を確認するにはまずSQLレポート内の「Known Optimizer Plan(s) for this Old Hash Value」の項目を参照します。ここで複数行の出力があった場合、1つのSQLに対して異なる実行計画が複数ある、つまり実行計画に変化があったことを示しています。図8は2つの実行計画が表示されている例です。実行計画の識別は“Plan Hash Value”列の値で行います。この例では“805044450”と“3469818654”の2つの実行計画が実行されたことがわかります。
|
図8:SQLレポートより抜粋 |
また、一番右側“Cost”列も着目すべきポイントです。この“Cost”はOracle Databaseが内部的な計算で算出している処理負荷の高さを示す値です。この“Cost”値の低い方がパフォーマンスとして優れていると見積もられている実行計画です。“Last Active Time”列ではその実行計画が最後に実行された時間が示されています。今回の例では“805044450”の実行計画の方がコスト値が低く、2017年11月10日の13時34分が最後に実行された時間となります。一方、それよりコスト値の高い“3469818654”が最後に実行されたのは2017年11月5日の14時02分となっています。このケースではパフォーマンスのより優れたSQLが後の時間帯に実行されているため、SQLのパフォーマンスは改善していると言えます。逆に後の時間帯に実行されているSQLの方がコスト値が高い場合はパフォーマンス遅延が発生している可能性があります。
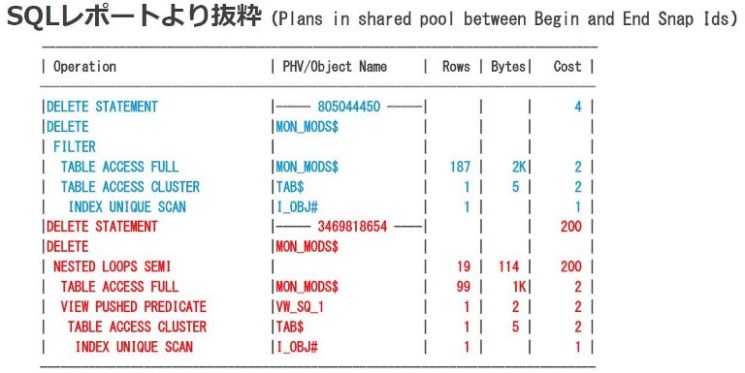
SQLレポートを読み進めて行くと、「Plans in shared pool between Begin and End Snap Ids」の項目で具体的な実行計画が出力されています。図9の例では“805044450”と“3469818654”の実行計画をそれぞれ赤字と青字で色付けして記載しています(※実際のSQLレポートは色分けで表示はされません)。
|
図9:SQLレポート内の実行計画の情報 |
SQLのパフォーマンス遅延発生時に、より新しい時間帯に実行されている実行計画のコスト値が高い場合は、コスト値の低い実行計画が選択されるようヒント句や統計情報のリストアなどの対処を検討します。
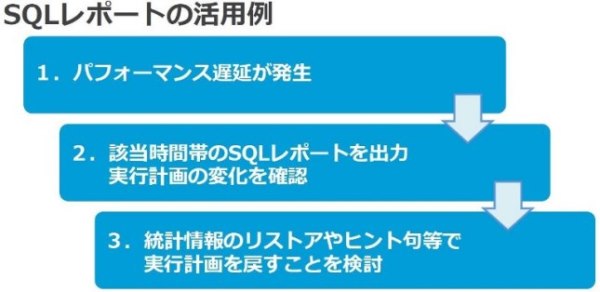
SQLレポートの活用例の流れをまとめると図10のようになります。
|
図10:レベル6 SQLレポートの活用例 |
レベル7では、Statspackレポートにセグメント別の統計が追加で出力されるようになります。物理I/Oやバッファ読込み、アクセス競合、ブロックの変更数といった観点から、どのセグメントに負荷が集中していたかが確認できます。図11はディスクからの物理読込みの多いセグメントのリストの例です。この例ではTESTユーザの持つ、TEST_TABというテーブルで最も物理読込みが発生していることを示しています。
|
図11:Statspackレポートのセグメント情報抜粋 |
レポート対象となるセグメントについてもしきい値パラメータが用意されており、SQLと同様にしきい値を超えたセグメントのみがレポートの対象となります。表2がセグメント統計に関するしきい値です。
| しきい値の内容 | パラメータ | デフォルト値 |
|---|---|---|
| 物理読込の発生回数 | i_seg_phy_reads_th | 1,000 |
| 論理読込発生回数 | i_seg_log_reads_th | 10,000 |
| ブロック競合の発生回数 | i_seg_buff_busy_th | 100 |
| 行ロックの発生回数 | i_seg_rowlock_w_th | 100 |
| ITL待機の発生数 | i_seg_itl_waits_th | 100 |
| crブロック数※ | i_seg_cr_bks_sd_th | 1,000 |
| currentブロック数※ | i_seg_cu_bks_sd_th | 1,000 |
しきい値の変更は以下のコマンドで行います。
|
|
また、レポートに表示されるセグメント数はデフォルトで5つですが、こちらも設定変更が可能です。設定変更を行うには、sprepcon.sqlのdefine top_n_segstatパラメータを編集します。編集後に出力したStatspackレポートから設定が反映されます。
|
|
セグメント別統計の活用例としては図12のようにセグメントごとでの負荷の確認に用います。
|
図12:レベル7 セグメント情報の活用例 |
Statspackレポートのセグメント別の統計から負荷の集中しやすいセグメントを特定します。集中している負荷の種類によって対処は変わってきますが、例えばディスクからの物理読込みが集中している場合は対象のテーブルをパーティション化したり、テーブルデータの内容自体を複数テーブルに分けて再構成し、異なる物理ディスク上に配置します。これにより物理ディスクのアクセス負荷を分散することで、システムのパフォーマンス向上を図るといったことが対策案として考えられます。
DBインスタンス全体のレポートを出力する方法はコマンド1でご紹介したspreport.sqlのみですが、spreport.sqlは一度の実行で一つのレポートしか出力できません。複数のsnpashotを跨いだ広い時間でのレポートの出力は可能ですが、連続したsnapshotごとに細かく出力したい場合は何度もspreport.sqlを実行する必要があり、工数がかかってしまいます。
Database Support Blogでは、日付単位の指定で各snapshotごとのレポートを一括で出力するスクリプトを公開しておりますので、是非ご利用ください。
【Oracle】Statspackレポートを期間指定で一括取得するスクリプト
ここからは運用上の注意点を紹介します。
Statspackレポートを出力するにはSnapshotを保存・蓄積していく必要があることを説明しましたが、その具体的な保存先はOracle Database内の専用テーブル(頭文字が“stats$”で始まるテーブル群)になります。Snapshotを取得する度に専用テーブルへデータがinsertされる仕組みとなっています。そのため、Snapshotを蓄積していけば、該当のテーブルは肥大化していくことになります。肥大化が進めば格納先表領域の空きが減っていきますので、継続してSnapshotを取得する運用の環境では定期的にSnapshotの削除を行う必要があります。ちなみに専用テーブルの格納先表領域はStatspackインストール時に指定します。
Snapshotの削除方法は以下の通りです。
|
|
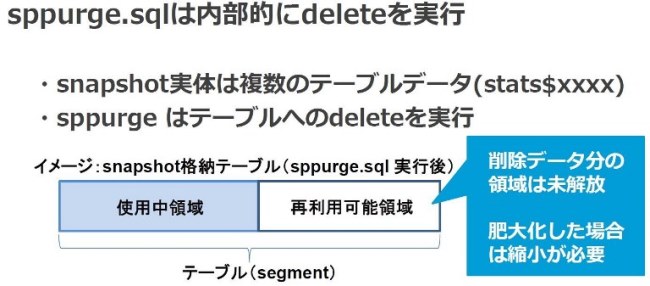
しかし、sppurge.sqlによるSnapshotの削除には領域観点での注意が必要です。sppurge.sqlは内部的にStatspack専用テーブルに対してdelete処理を行っています。Oracle Databaseではテーブルに対してdeleteを行った場合、削除したデータ領域はそのテーブルの再利用可能な領域として扱われ、表領域への開放は行われません。そのため、テーブルが肥大化した後にSnapshotデータを削除し、再利用可能領域も含めて開放を行いたい場合は別途shrink(縮小)処理を行う必要があります(図13参照)。
|
図13:sppurge.sqlでの削除イメージ |
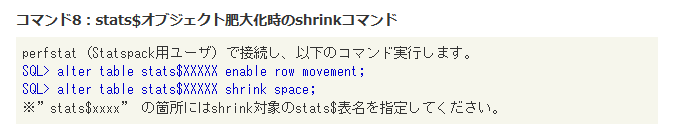
shrink処理は以下のコマンドで実行します。Statspack専用テーブルは“stats$”から始まるテーブル名ですので、shrink対象のテーブル名を当てはめて実行してください。
|
|
定期的にsnapshotを削除し、できるだけ“stats$”表を肥大化させない運用が理想的です。また、表領域は通常のユーザ・テーブルとの同居は避けてStatspack専用の表領域として用意するとより理想的です。Statspack専用テーブルとユーザ・テーブルが表領域内に同居していた場合、Statspack専用テーブルが肥大化して表領域を圧迫し、ユーザ・テーブルへのinsertができなくなるといった運用上の障害を避けるためです。稼働情報の収集・レポーティングはシステムの安定運用を目指して行いますが、そのための専用テーブルが肥大化することにより実運用に影響を与えてしまっては本末転倒です。
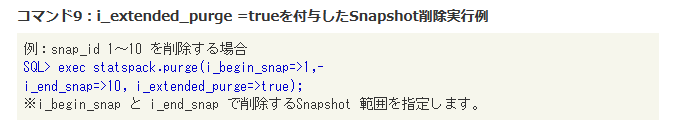
sppurge.sqlによる削除にはもう一つ注意点があります。sppurge.sqlでは“stats$”で始まるテーブルのうち一部のテーブルではデータが削除されない動作となっています。これは削除時の処理負荷を考慮した仕様と考えられます。sppurge.sqlで削除されないデータも含めてSnapshotを削除するには、i_extended_purge=>trueのオプションを付与してStatspackパッケージのpurgeプロシージャを実行します。
|
|
i_extended_purge=>trueでの削除時の注意点としては、sppurge.sql実行よりも多くのリソースを消費することが挙げられます。これは削除対象のデータがsppurge.sql実行時よりも多くなるためです。実際の負荷がどの程度かは環境に依存するため一概には言えませんが、念のため、出来る限り運用上の負荷の低い時間帯で実行することをお奨めします。
|
|
柿沼 修
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に示した定義及び条件は変更される場合があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java、MySQL及びNetSuiteは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。


アシストオラクルサポートセンターが公開しているFAQは、仕様に関するQAやエラー発生時の対処方法などはもちろん、不具合情報や障害発生時の情報取得方法といった安定運用に役立つ内容も扱っています。そのFAQをどのように作成しているのか、サポートセンターの取り組みをご紹介します。

Oracle Databaseのバージョン11g R2、12g.R1、12g.R2は既にすべてのメーカーサポートが終了しています。OCIのBase Database Serviceでも2024年1月中旬ころから11g R2、12g R1、12g R2での新規プロビジョニングができなくなりました。

アシストでは全社員にAIアシスタントGleanを導入しました。サポートセンターで2ヶ月間使ってみて感じた効果やメリットをお伝えします。



