
はじめに
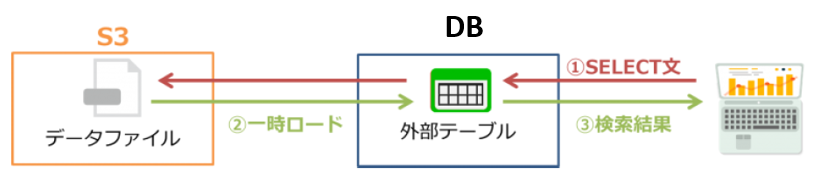
VerticaをAWS上で利用している場合、以下のS3ダイレクト連携機能を利用することが可能です。
①S3内のデータファイルをVerticaにロードする

②外部テーブルを使用してS3内のデータファイルを検索する
事前準備
事前に以下の準備を実施します。
IAMロールの割り当て
対象のS3のバケットに対するアクセス権限を持ったIAMロールをAWS上で作成し、VerticaがインストールされているEC2インスタンスに割り当てます。
対象ファイルの配置
Verticaで利用したいファイルをS3上に配置します。
なお、VerticaのS3ダイレクト連携機能で利用可能なファイルフォーマットは以下の通りです。
・テキストデータ(.csv、.txt等)
・Parquet
・ORC
※ParquetまたはORCを外部テーブル(②の方法)で参照する場合、外部ファイルのサイズが
課金対象となります。
外部テーブル用のライセンスもあるため、利用を検討したい方は、本ぺージの一番下にある
お問い合わせ先へご連絡ください。
※上記以外のファイルフォーマットを利用したい場合は、UDSourceを利用してください。
①S3内のデータファイルをVerticaにロードする
S3内に保管されているデータをCOPYコマンドを利用して、ダイレクトにVerticaにロードすることが可能です。
コマンド構文
dbadmin=> SELECT SET_CONFIG_PARAMETER('AWSRegion','S3バケットのリージョン');
dbadmin=> COPY テーブル名 FROM 's3://ロード対象ファイル' オプション;利用例
table1にap-northeast-1リーションのS3の「/kka/parquet/table1.parq」というparquetファイルをロードする場合
dbadmin=> SELECT SET_CONFIG_PARAMETER('AWSRegion','ap-northeast-1');
dbadmin=> COPY table1 FROM 's3://kka/parquet/table1.parq' PARQUET;
Rows Loaded
-------------
9
(1 row)②Verticaの外部テーブルを使用してS3内のデータファイルを検索する
S3内に保管されているデータをデータソースとする外部テーブルをVertica上に作成しておくことで、S3のデータをVerticaのSELECT文でダイレクトに検索することが可能です。
コマンド構文
dbadmin=> SELECT SET_CONFIG_PARAMETER('AWSRegion','S3バケットのリージョン');
dbadmin=> CREATE EXTERNAL TABLE テーブル名(テーブル定義)
-> AS COPY FROM 's3://検索対象ファイル' オプション;利用例
table1にap-northeast-1リーションのS3の「/kka/parquet/table1.parq」というparquetファイルをデータソースとする外部テーブルを作成する場合
dbadmin=> SELECT SET_CONFIG_PARAMETER('AWSRegion','ap-northeast-1');
dbadmin=> CREATE EXTERNAL TABLE table1_parquet(
-> 日付 varchar(8),
-> ID int,
-> 店舗 varchar(10),
-> エリア varchar(10),
-> 売上 int)
-> AS COPY FROM 's3://kka/parquet/table1.parq' PARQUET;
CREATE TABLE
dbadmin=> select * from table1_parquet;
日付 | ID | 店舗 | エリア | 売上
----------+-------+--------+--------+--------
20130701 | 10001 | 新宿 | 東京 | 100
20140701 | 10002 | 新宿 | 東京 | 1000
20150702 | 10003 | 名古屋 | 名古屋 | 10000
20130703 | 10004 | 梅田 | 大阪 | 2400
20140703 | 10005 | 池袋 | 東京 | 1600
20150703 | 10006 | 新宿 | 東京 | 6400
20130705 | 10007 | 品川 | 東京 | 1000
20140706 | 10008 | 梅田 | 大阪 | 1100
20150706 | 10009 | 名古屋 | 名古屋 | 1300
(9 rows)なお、以下のように「*」を利用することで指定ディレクトリ配下のすべてのファイルを検索の対象にすることが可能です。
dbadmin=> CREATE EXTERNAL TABLE table1_parquet(
-> 日付 varchar(8),
-> ID int,
-> 店舗 varchar(10),
-> エリア varchar(10),
-> 売上 int)
-> AS COPY FROM 's3://kka/parquet/*' PARQUET;参考情報
Loading Data from an S3 Bucket
https://my.vertica.com/docs/9.0.x/HTML/index.htm#Authoring/Eon/LoadingDataFromS3.htm
Verticaのデータロードの基本
https://www.ashisuto.co.jp/cm/analytics-database/dataload_overview.html
検証バージョンについて
この記事の内容はVertica 9.0.2で確認しています。
更新履歴
2019/04/05 ParquetまたはORCを外部テーブルで参照する場合の課金について補足説明を追加
2018/05/02 本記事を公開