
はじめに
機械学習において数値データの列を説明変数として利用する場合は、事前に正規化を行うと精度が向上することがあります。
例えば従業員データの内、「給与」列と「勤続年数」列を説明変数として機械学習に利用する場合、給与は「円」や「ドル」、勤続年数は「年」といったように単位が異なります。また単位が異なれば当然数値の範囲も異なります。このようなスケールが異なる列を同じスケールにするために正規化を利用します。
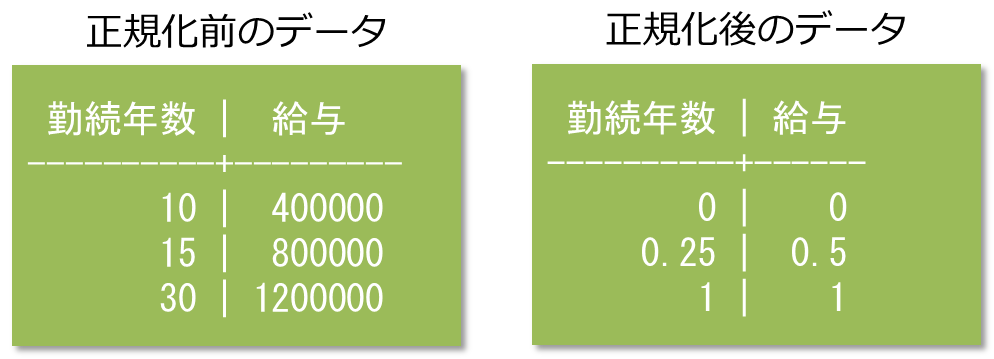
VerticaはNORMALIZE_FIT/APPLY_NORMALIZE関数を利用するとデータの正規化を行うことができます。
NORMALIZE_FIT/APPLY_NORMALIZE
コマンド構文
SELECT NORMALIZE_FIT ( 'model‑name', 'input‑relation', 'input‑columns', 'normalization‑method'
[ USING PARAMETERS [exclude_columns='excluded‑columns']
[, output_view='output‑view'] ] ) パラメータ名 | 内容 |
|---|---|
model‑name | 正規化の計算パラメータを保持するモデル名 |
input‑relation | 正規化対象のテーブル、ビュー |
input‑columns | 正規化対象の列。複数列指定する場合は「,」カンマで区切ります。 |
normalization‑method | minmax:0~1の範囲で正規化を実施します。 |
exclude_columns | (オプション) input‑columnsで*(全列)と指定した場合に、対象列から除外する列 |
output_view | (オプション) 正規化後のデータを保存する場合はそのビュー名を指定します。 |
利用例
例として従業員データであるsalary_dataテーブルを正規化します。
1)years_worked(勤続年数)、current_salary(給与)列はスケールが異なるため、正規化を実施します。
SELECT * FROM salary_data ORDER BY 1;
employee_id | first_name | last_name | years_worked | current_salary
-------------+-------------+------------+--------------+----------------
110 | Brenda | Morrison | 0 | 111294
112 | Jerry | Thomas | 7 | 121821
189 | Andrew | Burns | 4 | 38798
189 | Shawn | Moore | 7 | 151023
313 | Ruby | Black | 13 | 282291
426 | Anne | Green | 11 | 133469
518 | Earl | Shaw | 2 | 294344
593 | Lawrence | Larson | 19 | 264219
620 | Mary | Rose | 17 | 213873
630 | Michelle | Crawford | 7 | 129393
718 | Harry | Larson | 6 | 48123
777 | Ruby | Johnston | 16 | 51444
1043 | Diane | Morris | 14 | 207271
1126 | Susan | Alexander | 5 | 275869
1157 | Jack | Stone | 2 | 194583
1198 | Martha | Cooper | 4 | 197949
1202 | Norma | Stone | 19 | 110821
1277 | Scott | Wagner | 1 | 155972
1337 | Bruce | Fuller | 15 | 38062
1372 | Justin | Edwards | 1 | 111823
1436 | Judith | Parker | 9 | 100724
・
・
・
(1000 rows)2)years_worked、current_salary列に対して、NORMALIZE_FIT関数を使用して正規化の計算を行います。
※本例ではminmax法を用いて正規化を計算します。
SELECT NORMALIZE_FIT('salary_data_normfit', 'salary_data', 'years_worked,current_salary', 'minmax');
NORMALIZE_FIT
---------------
Success
(1 row)3)GET_MODEL_SUMMARY関数を使用すると、計算時に利用したデータの範囲(min/max)を確認することができます。
SELECT GET_MODEL_SUMMARY(USING PARAMETERS model_name='salary_data_normfit');
=======
details
=======
column_name | min | max
--------------+-----------+------------
years_worked | 0.00000 | 20.00000
current_salary|35321.00000|299936.00000
(1 row)4)NORMALIZE_FIT関数で計算した正規化パラメータはモデルとしてVertica内に保存されています。
実際に正規化を行う場合はAPPLY_NORMALIZE関数を使用してモデルを適用します。
SELECT APPLY_NORMALIZE ( input‑columns
USING PARAMETERS model_name='model‑name') FROM table-name;パラメータ名 | 内容 |
|---|---|
input‑columns | 正規化対象の列。複数列指定する場合は「,」カンマで区切ります。 |
model‑name | 使用する正規化パラメータのモデル名 |
APPLY_NORMALIZE関数で実際にsalary_dataテーブルのyears_worked、current_salary列を正規化します。
※手順2)で作成したsalary_data_normfitを使用します。
SELECT APPLY_NORMALIZE(* USING PARAMETERS model_name = 'salary_data_normfit') FROM salary_data ORDER BY 1;
employee_id | first_name | last_name | years_worked | current_salary
-------------+-------------+------------+--------------------+---------------------
110 | Brenda | Morrison | 0 | 0.287107676267624
112 | Jerry | Thomas | 0.349999994039536 | 0.326890021562576
189 | Andrew | Burns | 0.200000002980232 | 0.0131398448720574
189 | Shawn | Moore | 0.349999994039536 | 0.437246561050415
313 | Ruby | Black | 0.649999976158142 | 0.933318197727203
426 | Anne | Green | 0.550000011920929 | 0.370908677577972
518 | Earl | Shaw | 0.100000001490116 | 0.978867411613464
593 | Lawrence | Larson | 0.949999988079071 | 0.865022778511047
620 | Mary | Rose | 0.850000023841858 | 0.674761474132538
630 | Michelle | Crawford | 0.349999994039536 | 0.355505168437958
718 | Harry | Larson | 0.300000011920929 | 0.048379722982645
777 | Ruby | Johnston | 0.800000011920929 | 0.0609300322830677
1043 | Diane | Morris | 0.699999988079071 | 0.649811983108521
1126 | Susan | Alexander | 0.25 | 0.909048974514008
1157 | Jack | Stone | 0.100000001490116 | 0.601863086223602
1198 | Martha | Cooper | 0.200000002980232 | 0.614583432674408
1202 | Norma | Stone | 0.949999988079071 | 0.285320192575455
1277 | Scott | Wagner | 0.0500000007450581 | 0.45594921708107
1337 | Bruce | Fuller | 0.75 | 0.0103584453463554
1372 | Justin | Edwards | 0.0500000007450581 | 0.289106816053391
1436 | Judith | Parker | 0.449999988079071 | 0.247162863612175
・
・
・
(1000 rows)これにより、years_worked、current_salary列の値がデータ間の差は維持したまま0~1の範囲に置き換えられました。
例えば、years_workedの最大値は手順2)で20であることが確認できています。
以下のemployee_id 2974のデータはyears_workedが20ですが、正規化後は1に置き換えられています。
SELECT * FROM salary_data WHERE years_worked=20 LIMIT 1;
employee_id | first_name | last_name | years_worked | current_salary
-------------+------------+-----------+--------------+----------------
2974 | Janet | Russell | 20 | 292120
(1 row)SELECT APPLY_NORMALIZE(* USING PARAMETERS model_name = 'salary_data_normfit') FROM salary_data WHERE employee_id=2974;
employee_id | first_name | last_name | years_worked | current_salary
-------------+------------+-----------+--------------+-------------------
2974 | Janet | Russell | 1 | 0.970462739467621
(1 row)また、employee_id 2659のデータはyears_workedが10で全体の中央値のため、正規化後は0.5に置き換えられています。
SELECT * FROM salary_data WHERE years_worked=10 LIMIT 1;
employee_id | first_name | last_name | years_worked | current_salary
-------------+------------+-----------+--------------+----------------
2659 | Gregory | Mason | 10 | 253352
(1 row)SELECT APPLY_NORMALIZE(* USING PARAMETERS model_name = 'salary_data_normfit') FROM salary_data WHERE employee_id=2659;
employee_id | first_name | last_name | years_worked | current_salary
-------------+------------+-----------+--------------+-------------------
2659 | Gregory | Mason | 0.5 | 0.823955535888672
(1 row)なお、NORMALIZE_FIT関数で作成した正規化モデルは、計算時に指定したテーブル以外でも適用可能なため、学習時だけでなく実際の予測時にも前処理で利用可能です。
参考情報
APPLY_NORMALIZE
https://www.vertica.com/docs/9.1.x/HTML/index.htm#Authoring/SQLReferenceManual/Functions/MachineLearning/APPLY_NORMALIZE.htm
検証バージョンについて
この記事の内容はVertica 9.1で確認しています。