
はじめに
Verticaは複数台構成でノードダウンが発生した場合、ノード復旧後は各ノード間でデータの整合性を保つために、リカバリが実行されます。Vertica7.1までは、リカバリ実行中は全てのテーブルに対して一度にロックをかける動作だったので、DDL/DML(Delete, Update, Merge) は長時間ロックで待たされることがありました。Vertica7.2からは、優先度に従ってテーブル単位でリカバリが実行できるようになったため、リカバリが完了したテーブルから、随時 DDL/DMLを実行できるようになりました。
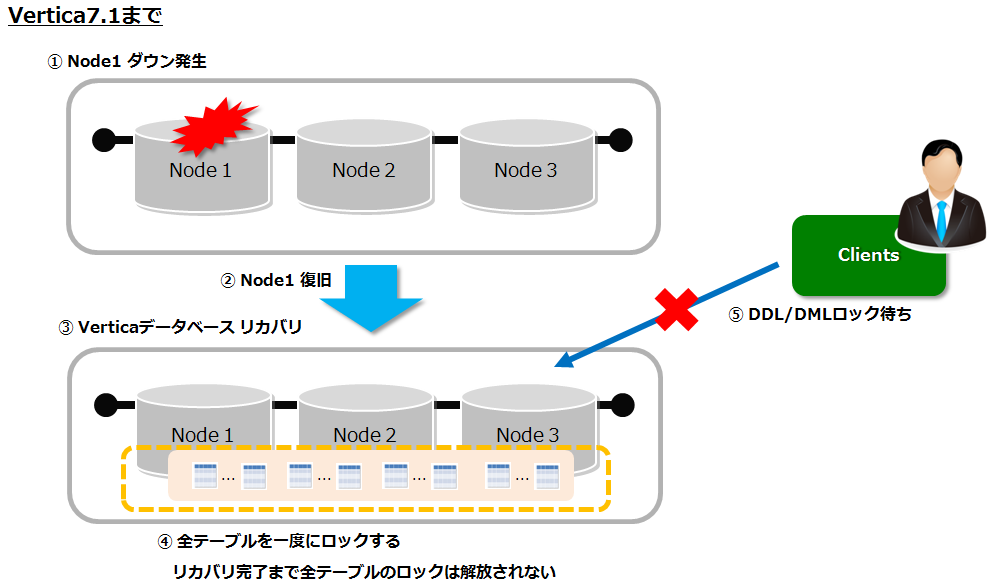
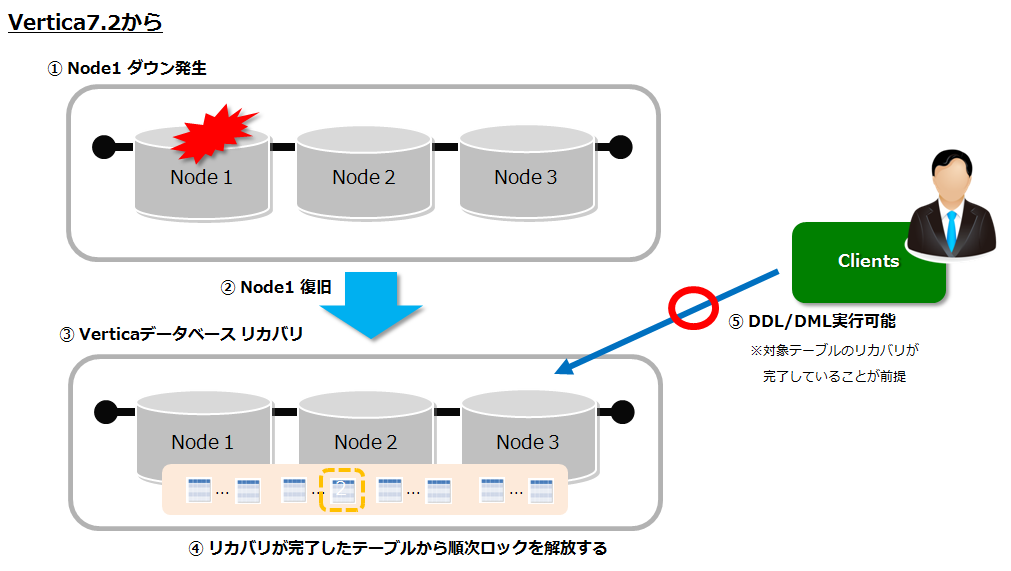
リカバリの優先度について
優先的にリカバリを実行したいテーブルが存在する場合は、「優先度」を明示的に指定する必要があります。
以下の表は、テーブルがリカバリされる順番を示しており、①→②の順で実行されます。
リカバリの順番 | 説明 |
|---|---|
①優先度が指定された順 | 各テーブルに優先度を指定した場合は、優先度に従ってリカバリが実行されます。 |
②作成した日時が古い順 | 「優先度を指定していないテーブル」や「優先度が同一のテーブル」は、OIDが小さい順にリカバリが実行されます。 |
コマンド構文
テーブルの優先度を指定する場合は、以下の SQL を実行します。
SELECT set_table_recover_priority(’テーブル名’,’優先度’);
[set_table_recover_priority]
項目 | 説明 |
|---|---|
テーブル名 | テーブル名を指定します。 |
優先度 | テーブル名の優先度を指定します。値は「-9223372036854775807~9223372036854775807」の範囲で指定可能です。 |
実行例
優先度が指定されたテーブルについて、実行例をもとにリカバリの動作を解説いたします。
【1】リカバリ対象のテーブル一覧を確認します。
[dbadmin@server01 ~]$ vsql
Password:
Welcome to vsql, the Vertica Analytic Database interactive terminal.
Type: \h or \? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
dbadmin=> \d
List of tables
Schema | Name | Kind | Owner | Comment
--------+------+-------+---------+---------
public | t4 | table | dbadmin |
public | t5 | table | dbadmin |
public | t6 | table | dbadmin |
public | t_p1 | table | dbadmin |
public | t_p2 | table | dbadmin |
public | t_p3 | table | dbadmin |
(6 rows)【2】各テーブルにリカバリの優先度を指定します。以下の例は、優先度を「t_p1=1000, t_p2=500, t_p3=1」に指定しています。
dbadmin=> SELECT set_table_recover_priority('t_p1', '1000');
set_table_recover_priority
---------------------------------------
Table recovery priority has been set.
(1 row)
dbadmin=> SELECT set_table_recover_priority('t_p2', '500');
set_table_recover_priority
---------------------------------------
Table recovery priority has been set.
(1 row)
dbadmin=> SELECT set_table_recover_priority('t_p3', '1');
set_table_recover_priority
---------------------------------------
Table recovery priority has been set.
(1 row)【3】優先度を指定したテーブルを確認します。以下の例は、「t4, t5, t6」に優先度は指定していません。
dbadmin=> SELECT table_name as name, recover_priority,table_id as oid FROM tables ORDER BY recover_priority DESC, oid;
Name | recover_priority | oid
------+----------------------+-------------------
t_p1 | 1000 | 45035996273839508
t_p2 | 500 | 45035996273839506
t_p3 | 1 | 45035996273839504
t4 | -9223372036854775807 | 45035996273840180
t5 | -9223372036854775807 | 45035996273840182
t6 | -9223372036854775807 | 45035996273840184
(6 rows)【4】リカバリの同時実行数を変更します。リカバリが実行された順番を簡単に識別するために「MAXCONCURRENCY=1」(※)を設定します。「MAXCONCURRENCY=1」に設定することで、各テーブルのリカバリがシリアルに実行されます。
(※)デフォルト値の場合は、同時に複数のテーブルに対して、リカバリが実行されます。
dbadmin=> ALTER RESOURCE POOL recovery MAXCONCURRENCY 1;
ALTER RESOURCE POOL【5】データベースのデータ領域を削除することで、1号機をDOWN状態にします。
[dbadmin@server01 ~]$ rm -rf /home/dbadmin/testdb/v_testdb_node0001_data
[dbadmin@server01 ~]$ admintools -t stop_node -s v_testdb_node0001
*** Forcing host shutdown ***
Sending host shutdown command to '10.0.0.25'
[dbadmin@server01~]$ admintools -t list_allnodes
Node | Host | State | Version | DB
-------------------+-----------+-------+-----------------+--------
v_testdb_node0001 | 10.0.0.25 | DOWN | vertica-9.2.0.6 | testdb
v_testdb_node0002 | 10.0.0.26 | UP | vertica-9.2.0.6 | testdb
v_testdb_node0003 | 10.0.0.27 | UP | vertica-9.2.0.6 | testdb【6】1号機を起動して、リカバリを自動実行させます。
[dbadmin@server01 ~]$ admintools -t restart_node -s v_testdb_node0001 -d testdb --force
Info: no password specified, using none
*** Restarting nodes for database testdb ***
Restarting host [10.0.0.25] with catalog [v_testdb_node0001_catalog]
Issuing multi-node restart
Starting nodes:
v_testdb_node0001 (10.0.0.25)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (UP) v_testdb_node0003: (UP)
Restart Nodes result: 1【7】「table_recoveries」システムテーブルで、各テーブルのリカバリ状況を確認します。「start_time」と「end_time」の時刻から、「t_p1→t_p2→t_p3→t4→t5→t6」の順番で、リカバリされたことが確認できます。
[dbadmin@server01 ~]$ vsql
Password:
Welcome to vsql, the Vertica Analytic Database interactive terminal.
Type: \h or \? for help with vsql commands
\g or terminate with semicolon to execute query
\q to quit
[dbadmin@server01 ~]$ admintools -t list_allnodes
Node | Host | State | Version | DB
-------------------+-----------+-------+-----------------+--------
v_testdb_node0001 | 10.0.0.25 | UP | vertica-9.2.0.6 | testdb
v_testdb_node0002 | 10.0.0.26 | UP | vertica-9.2.0.6 | testdb
v_testdb_node0003 | 10.0.0.27 | UP | vertica-9.2.0.6 | testdb
dbadmin=> SELECT node_name,table_name,recover_priority,table_oid,status,start_time,end_time FROM table_recoveries WHERE start_time > '2019-04-10 19:45' ORDER BY start_time;
node_name | table_name | recover_priority | table_oid | status | start_time | end_time
-------------------+-------------+----------------------+-------------------+-----------+-------------------------------+-------------------------------
v_testdb_node0001 | public.t_p1 | 1000 | 45035996273839508 | recovered | 2019-04-10 19:45:02.925977+09 | 2019-04-10 19:45:03.142597+09
v_testdb_node0001 | public.t_p2 | 500 | 45035996273839506 | recovered | 2019-04-10 19:45:03.1432+09 | 2019-04-10 19:45:03.351753+09
v_testdb_node0001 | public.t_p3 | 1 | 45035996273839504 | recovered | 2019-04-10 19:45:03.352333+09 | 2019-04-10 19:45:03.556473+09
v_testdb_node0001 | public.t4 | -9223372036854775807 | 45035996273840180 | recovered | 2019-04-10 19:45:03.557015+09 | 2019-04-10 19:45:06.854506+09
v_testdb_node0001 | public.t5 | -9223372036854775807 | 45035996273840182 | recovered | 2019-04-10 19:45:06.855025+09 | 2019-04-10 19:45:09.94958+09
v_testdb_node0001 | public.t6 | -9223372036854775807 | 45035996273840184 | recovered | 2019-04-10 19:45:09.950291+09 | 2019-04-10 19:45:13.132874+09
(6 rows)参考情報
・Verticaノードのクラスタ
https://www.ashisuto.co.jp/cm/analytics-database/node_cluster.html
検証バージョンについて
この記事の内容はVertica 9.2で確認しています。
更新履歴
2019/05/10 テーブル優先度の実行例を修正、リカバリ状況の確認方法を別記事に統合
2016/02/22 本記事を公開