
はじめに
Verticaは7.2.2以降、複数のテーブルを同時にリカバリができるようになりました。
同時にリカバリができるテーブルの数は、次の内容によって決定されます。
・RECOVERYリソースプールのMAXCONCURRENCY
・テーブル毎のプロジェクション数
MAXCONCURRENCYの値を増やすことで、同時にリカバリできるプロジェクションの数も増えて、リカバリのパフォーマンスを向上できる可能性があります。今回は実行例をもとに、MAXCONCURRENCYの値とリカバリの実行時間について、解説いたします。
[リカバリ実行時のイメージ]
赤枠はMAXCONCURRENCYの値による、リカバリ対象の範囲を示しています。
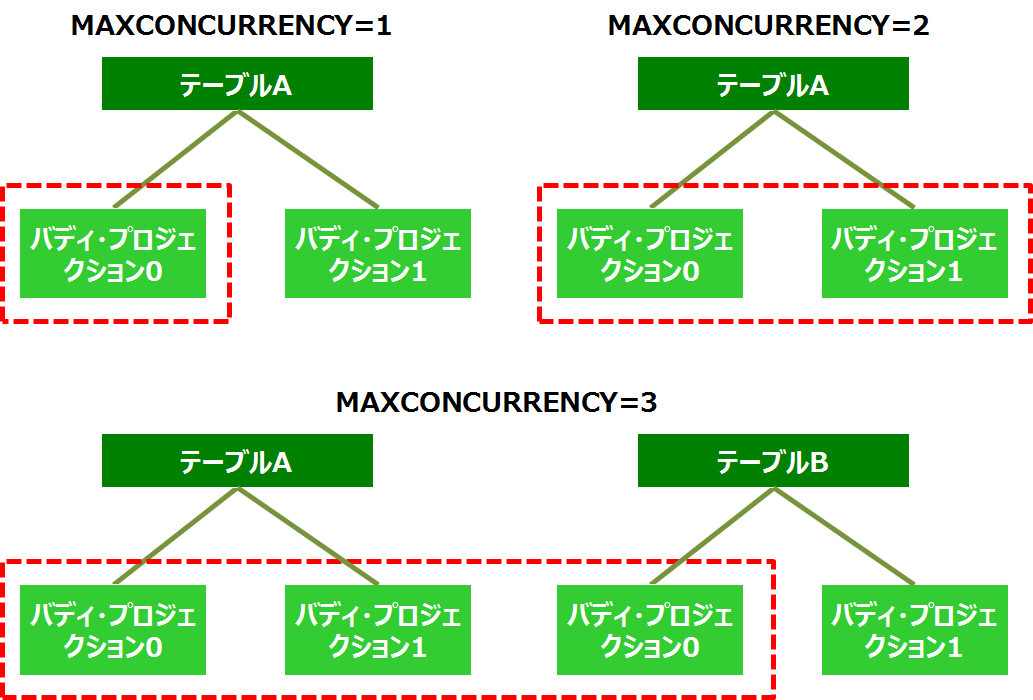
※MAXCONCURRENCYの値を増やすことで、リカバリの同時実行数は増えますが、使用されるメモリサイズも増えます。そのため、リカバリ中に利用者がSQLを実行した場合は、メモリが割当てられずにSQLが遅延する可能性があるので、ご注意ください。
リカバリのテストについて
テスト内容
RECOVERYリソースプールのMAXCONCURRENCYを 1、9(※)、18に設定して、リカバリの実行時間を計測しました。
※デフォルト値。Verticaサーバのコア数に依存します。
[テスト環境]
項目 | 内容 |
|---|---|
CPU | E5-2667 v3 @ 3.20GHz 1CPU(8Core) * 2 |
RAM | 256GB |
Vertica | 9.2.0.6 |
OS | Red Hat Enterprise Linux Server release 7.4 |
ノード数 | 3 |
k-safe | 1 |
テーブル数 | 500(※) |
レコード件数 | 3750000(※) |
※各テーブルは、すべて同一のカラムと件数です。
テスト結果
リカバリは、MAXCONCURRENCY=18に設定した場合が、最も速い結果になりました。
値 | 実行時間(秒) |
|---|---|
MAXCONCURRENCY=1 | 112 |
MAXCONCURRENCY=9 | 72 |
MAXCONCURRENCY=18 | 61 |
実行例
ご参考までに、MAXCONCURRENCY=18でテストした時の実行例をご紹介いたします。MAXCONCURRENCY=1、9も同様の手順でテストをしています。
【1】MAXCONCURRENCYの値を9→18に変更します。
dbadmin=> SELECT * FROM resource_pools WHERE name = 'recovery';
-[ RECORD 1 ]------------+------------------
pool_id | 45035996273705008
name | recovery
is_internal | t
memorysize | 0%
maxmemorysize |
maxquerymemorysize |
executionparallelism | AUTO
priority | 107
runtimepriority | MEDIUM
runtimeprioritythreshold | 60
queuetimeout | 00:05
plannedconcurrency | AUTO
maxconcurrency | 9
runtimecap |
singleinitiator | t
cpuaffinityset |
cpuaffinitymode | ANY
cascadeto |
dbadmin=> ALTER RESOURCE POOL recovery MAXCONCURRENCY 18;
ALTER RESOURCE POOL【2】リカバリを実行するために、ノード1のデータ領域を削除します。その後、ノード1のVerticaを停止し、起動するとリカバリが開始されます。
[dbadmin@server01 ~]$ rm -rf /data/testdb/v_testdb_node0001_data
[dbadmin@server01 ~]$ admintools -t stop_node -s v_testdb_node0001
*** Forcing host shutdown ***
Sending host shutdown command to '10.0.0.25'
[dbadmin@server01 ~]$ admintools -t restart_node -s v_testdb_node0001 -d testdb -F
Info: no password specified, using none
*** Restarting nodes for database testdb ***
Restarting host [10.0.0.25] with catalog [v_testdb_node0001_catalog]
Issuing multi-node restart
Starting nodes:
v_testdb_node0001 (10.0.0.25)
Starting Vertica on all nodes. Please wait, databases with a large catalog may take a while to initialize.
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (DOWN) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (RECOVERING) v_testdb_node0003: (UP)
Node Status: v_testdb_node0001: (UP) v_testdb_node0003: (UP)
Restart Nodes result: 1【3】リカバリ中に「table_recovery_status」システムテーブルを確認すると、9テーブルに対してリカバリが実行されています。各テーブルは、2つのプロジェクション(バディ・プロジェクション)で構成されているため、合計18個のリカバリ処理が実行されていることになります。
dbadmin=> SELECT * FROM table_recovery_status;
node_name | node_recovery_start_time | recover_epoch | recovering_table_name | tables_remain | is_running
-------------------+-------------------------------+---------------+-----------------------------------------------------------------------------------------------------------------------+---------------+------------
v_testdb_node0001 | 2019-04-16 20:57:39.242701+09 | 516 | public.t329; public.t337; public.t338; public.t339; public.t340; public.t341; public.t342; public.t343; public.t344; | 500 | t
v_testdb_node0002 | | | | 0 | f
v_testdb_node0003 | | | | 0 | f
(3 rows)【4】リカバリ完了後に「node_states」システムテーブルを確認すると、リカバリの実行時間を確認することができます。ノード1は「2019-04-16 20:57:38.246166+09」に「INITIALIZING」状態となり、「2019-04-16 20:58:39.840811+09」に「UP」状態になって、リカバリは完了しています。
dbadmin=> SELECT * FROM node_states;
event_timestamp | node_id | node_name | node_state
-------------------------------+-------------------+-------------------+--------------
:
2019-04-16 20:57:19.062846+09 | 45035996273704978 | v_testdb_node0001 | SHUTDOWN
2019-04-16 20:57:19.485828+09 | 45035996273704978 | v_testdb_node0001 | DOWN
2019-04-16 20:57:38.246166+09 | 45035996273704978 | v_testdb_node0001 | INITIALIZING
2019-04-16 20:57:38.999254+09 | 45035996273704978 | v_testdb_node0001 | RECOVERING
2019-04-16 20:58:39.840699+09 | 45035996273704978 | v_testdb_node0001 | READY
2019-04-16 20:58:39.840811+09 | 45035996273704978 | v_testdb_node0001 | UP
:
(68 rows)検証バージョンについて
この記事の内容はVertica 9.2で確認しています。
更新履歴
2019/04/24 本記事を公開