
はじめに
Verticaにデータロードを行うコマンドとして以下の2つが用意されています。
・INSERT
・COPY
本記事ではそれぞれのコマンドの基本的な使用方法をご案内します。
INSERTとCOPYの使い分け
データロード方式は、以下のように使い分けます。
INSERT:マスターテーブルに新規データを追加する等、少量のデータ追加を行う場合に使用
COPY :CSVファイル等を利用してデータを一括ロードする場合に使用
Verticaにおける大量データのロードについては、COPYによる一括ロードの方がパフォーマンスの面で優れます。
そのため特別な要件がない限り、Verticaでの大量データロードには、INSERTではなくCOPYの使用をご検討ください。
INSERT
構文
INSERT INTO [[データベース.]スキーマ.]テーブル名
... [ ( 列リスト ) ]
... { デフォルト値 | 値 ( 値リスト ) | SELECT文 }実行例
以下に基本的な実行例をいくつかご案内します。
--通常(数値データの挿入)
=> INSERT INTO t1 VALUES (1, 2, 3);
--通常(文字列データの挿入)
--文字列はシングルコーテーションで囲みます。
=> INSERT INTO t2 VALUES ('aaa');
--列指定
=> INSERT INTO t3 (col1, col3) VALUES (1, 'aaa');
--副問合せを使用する場合
=> INSERT INTO t4 SELECT * FROM t3 WHERE col1 < '3';
--特定の列に対して、副問合せの結果セットを挿入したい場合
※Verticaでは、特定の列に値を挿入する目的で、他の値と並列に副問合せを指定することができません。
例えば、以下のように指定するとエラーとなります。
=> INSERT INTO t5 (col1, col2) VALUES ('abc', (SELECT col1 FROM t4));
ERROR 4821: Subqueries not allowed in target of insert
--値リスト内で副問合せを使用したい場合は、以下のように指定します。
※SELECTの出力のみで、ロード対象の列全てに値を挿入できるようにしています。
=> INSERT INTO t5 (col1, col2) SELECT 'abc', col1 FROM t4;
OUTPUT
--------
2
(1 row)補足
9.2以前のバージョンでは、VerticaはROSに加え規模の小さいデータロードに使用されるWOSというメモリ領域が存在しましたが、アーキテクチャを簡素化する目的で9.3以降では廃止されます。
9.3以降は、WOSを経由せず、常にROSに直接データロードされる仕様となりました。
COPY
構文
COPY [[データベース名.]スキーマ名.]テーブル名 FROM 'ロード対象ファイル' オプションオプション
ロード対象ファイルのフォーマット等に対応するため、COPYコマンドには豊富なオプションが用意されています。
その中から、よく使用するものを一部ご紹介します。
| パラメータ名 | 説明 | デフォルト値 (未指定時の動作) |
|---|---|---|
| DELIMITER | 区切り文字を指定します。 | |(パイプ) |
| ENCLOSED BY | 囲み文字を指定します。 | なし |
| ENFORCELENGTH | ロードするデータが列幅を超過(桁あふれ)した場合、その行のロードをスキップします。 | 桁あふれした部分を切り捨ててロード |
| ABORT ON ERROR | エラーレコードを検出した時点でロード処理を中止し、処理全体をロールバック | エラーレコードはスキップして処理 |
実行例
前述したオプションの紹介も兼ね、以下に実行例をご案内します。
オプションが必要ない場合
=> \! cat /tmp/work/test01.csv
10|渋谷|東京
20|梅田|大阪
30|新宿|東京
=> copy table1 from '/tmp/work/test01.csv';
Rows Loaded
-------------
3
(1 row)区切り文字を指定する場合
=> \! cat /tmp/work/test02.csv
10,渋谷,東京
20,梅田,大阪
30,新宿,東京
=> copy table1 from '/tmp/work/test02.csv' delimiter ',';
Rows Loaded
-------------
3
(1 row)囲み文字を指定する場合
=> \! cat /tmp/work/test03.csv
"10"|"渋谷"|"東京"
"20"|"梅田"|"大阪"
"30"|"新宿"|"東京"
=> copy table1 from '/tmp/work/test03.csv' enclosed by '"';
Rows Loaded
-------------
3
(1 row)データ分散について
複数ノード構成のVerticaでは、大規模なテーブル(プロジェクション)のデータは各ノードに分散して保持します。
データロード処理(COPY、INSERT)を実行した際、Verticaはデータの分散配置を自動的に行います。
そのため、ユーザー側でデータの分散方式等について意識する必要はありません。
以下に分散配置のイメージ図を記載します。
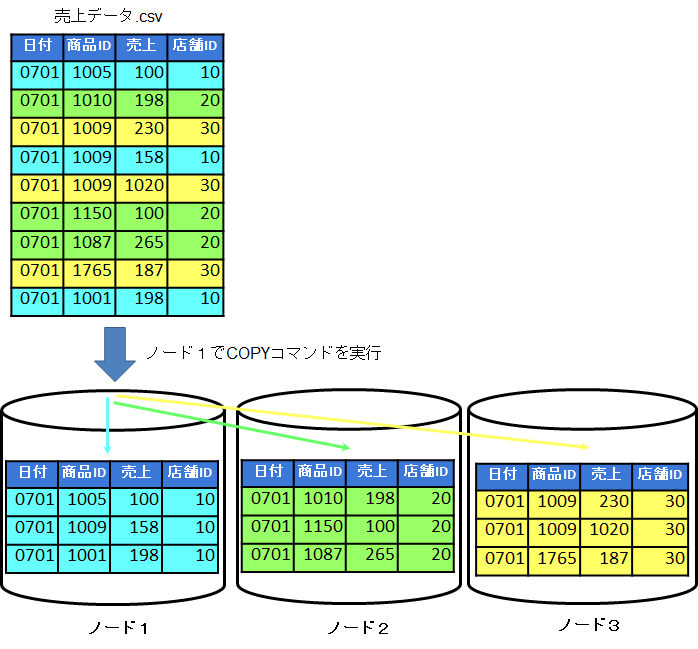
※Verticaは、セグメントキーを設定してデータ分散を行います。
上記図の例では、店舗ID列がセグメントキーに設定されています。
※全ノードに複製(レプリケーション化)されるテーブルは、上記のようなデータ分散処理は行われません。
参考情報
INSERT
https://www.vertica.com/docs/9.3.x/HTML/Content/Authoring/SQLReferenceManual/Statements/INSERT.htm
検証バージョンについて
この記事の内容はVertica 9.3で確認しています。
更新履歴
2020/04/27 本記事を公開