
はじめに
大量データのテーブル同士を結合したSQLを実行した場合、以下のようなメモリ不足のエラーが発生することがあります。
ERROR 3815: Join inner did not fit in memory [(SCHEMA1.TABLE_BIG1 x SCHEMA1.TABLE_BIG2) using TABLE_BIG1_b0 and previous join (PATH ID: 5)]
本記事では、テーブル結合によるメモリ不足のエラーが発生した場合のトラブルシューティングをご紹介します。
原因
エラーの多くは、以下が原因です。
・統計情報を一度も取得していないため、最適なアクセスパスでSQLが実行されていない。
・大きなテーブル同士を「Hash Join」で結合している。
Hash Joinによるエラーの原因
結合方法
テーブルの結合方法には、「Hash Join」と「Merge Join」の2種類あります。SQL実行時にどちらの結合方法を使用するかは、Verticaのオプティマイザが判断します。
それぞれの結合方法の仕組みについては、以下をご確認ください。
・テーブルの内部的な結合処理について(HASH JOIN,MERGE JOIN)
https://www.ashisuto.co.jp/cm/analytics-database/join_type-2.html
エラー発生までの流れ
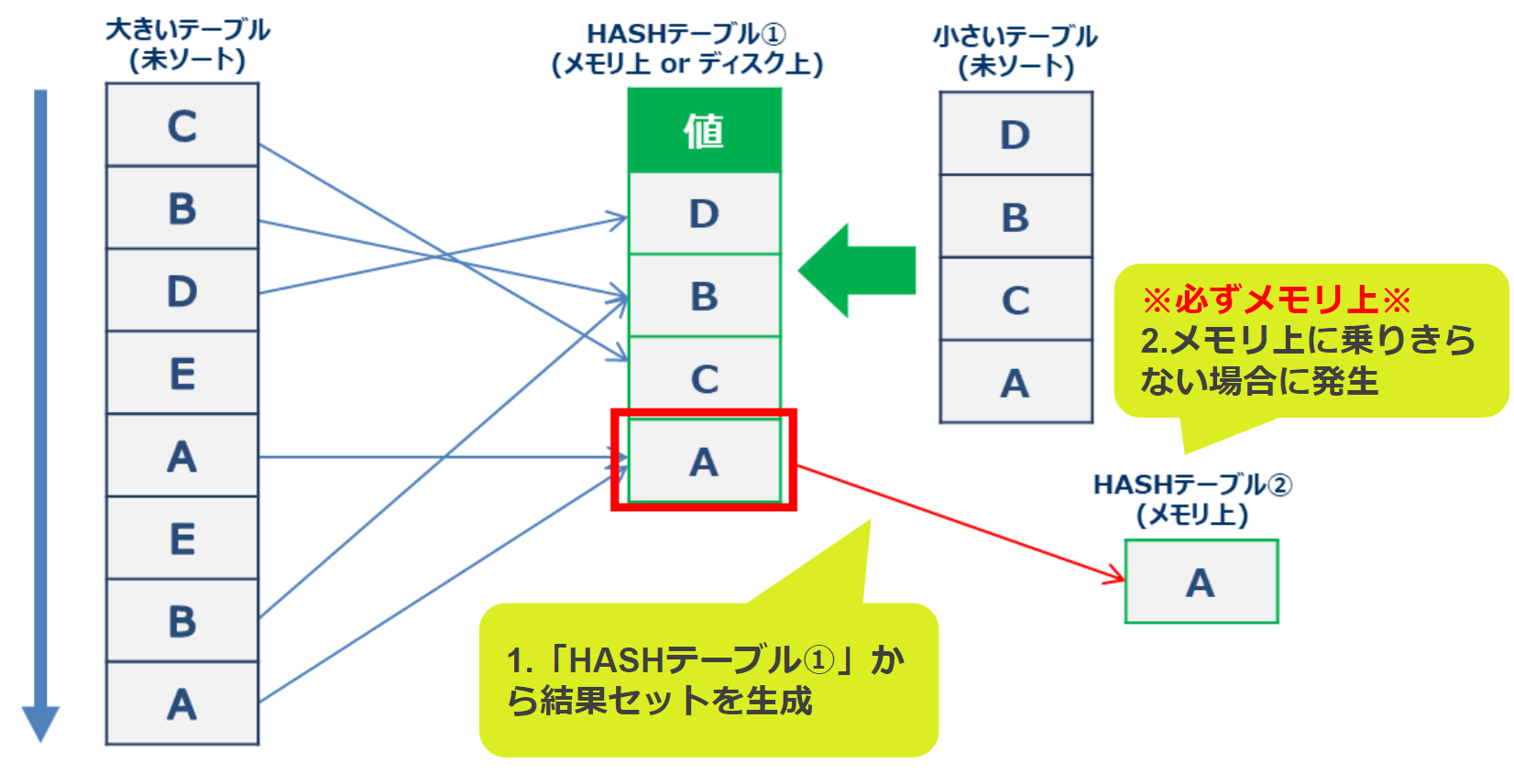
「Hash Join」では、HASHテーブルを使って結合を行いますが、HASHテーブルはメモリ上またはディスク上で作成されます。(下の図の赤枠)

続いて、HASHテーブルを使って結合した結果セット(HASHテーブル②)をメモリ上に作成します。この処理は必ずメモリ上で行われます。メモリ上に乗り切らない場合は、エラーが発生します。
対処方法
対処方法は以下が考えられます。①→⑥の順に対応の難易度は高くなります。
① 何もしない(経過観察)
② 運用方法の検討(利用者のアクセス制御)
③ 統計情報の取得とプロジェクション最適化の実行
④ クエリスペシフィックプロジェクションの作成
⑤ SQLのチューニング
⑥ 物理メモリの増設
各対処方法の説明やメリット・デメリットは、以下のとおりです。
対処方法 | 説明 |
|---|---|
①何もしない(経過観察) | エラーの発生頻度が少ないようであれば、様子をみることも選択肢として挙げられる。 メリット:作業工数が発生しない。 |
②運用方法の検討(利用者のアクセス制御) | 特定のSQLで発生している場合は、SQLを発行している利用者のアクセスを制御する等、運用での回避も考えられる。 メリット:作業工数は発生しない。 |
③統計情報の取得と | 一度もテーブルの統計情報取得と最適化が実行されていない場合は、統計情報の取得と最適化を実行する。 メリット:Verticaのコマンド実行やツール操作(admintoolsやMC)による対応のため、SQLの改修に比べて、作業工数を抑えることができる。 |
④クエリスペシフィックプロジェクションの作成 | 特定のSQLで発生している場合は、クエリスペシフイックプロジェクションを作成して、処理に必要なメモリサイズが小さくなるようにする。 メリット:Verticaのコマンド実行やツール操作(admintoolsやMC)による対応のため、SQLの改修に比べて、作業工数を抑えることができる。 |
⑤SQLのチューニング | 特定のSQLで発生している場合は、SQLの構造を見直して、処理に必要なメモリサイズを小さくするように改修する。 メリット:SQLのメモリ使用量を減らすことにより、根本的な解決につながると考えられる。 |
⑥物理メモリの増設 | 各ノードのメモリを増設する。 メリット:根本的な解決につながると考えられる。 |
これらの対処方法の中で、Vertica側での対応が必要な③~⑤の手順をご説明します。
難易度の低い③から対応し、解消しない場合は④、⑤の順で対応することをお薦めします。
対処方法③ 統計情報の取得とプロジェクション最適化の実行
一度もテーブルの統計情報取得と最適化が実行されていない場合は、統計情報の取得と最適化を実行することでエラーが解消する可能性があります。以下の手順で行います。
Step1:実行計画の確認
Step2:統計情報の取得、最適化の実行
Step3:SQLの再実行
Step4:実行計画の確認
Step5:SQLのメモリ使用量を確認
Step1:実行計画の確認
SQLの実行計画を取得し、統計情報と最適化の状態を確認します。
実行計画の確認方法は、以下をご確認ください。
・SQLの実行計画を確認する方法
https://www.ashisuto.co.jp/cm/analytics-database/sql-plan.html
EXPLAIN SELECT * FROM table1 AS a INNER JOIN table2 AS b ON a.col1=b.col1;
Access Path:
...
| +-- Outer -> STORAGE ACCESS for b [Cost: 661, Rows: 10K (NO STATISTICS)★] (PATH ID: 2)
| | Projection: public.table2_super★
| | Materialize: b.col1
...
| +-- Inner -> STORAGE ACCESS for a [Cost: 16, Rows: 7] (PATH ID: 3)
| | Projection: public.table1_DBD_1_rep_sp2
...上の実行計画を確認すると、(NO STATISTICS) の出力が確認できます。(NO STATISTICS) は、統計情報が一度も取得されていないことを表します。
また、プロジェクションの名前は、_super となっていることが確認できます。_super はテーブルにデータをロードした直後に生成されるプロジェクションの名前のため、最適化が行われていないことが分かります。
Step2:統計情報の取得、最適化の実行
統計情報の取得とプロジェクションの最適化を実行します。手順は以下をご確認ください。
※プロジェクションの最適化を実行するとき、オプションで統計情報も一緒に取得することが可能です。
・手動で統計情報を取得する方法
https://www.ashisuto.co.jp/cm/analytics-database/collect_analyze.html
・データベースデザイナを使用してテーブル単位でプロジェクションを最適化する
https://www.ashisuto.co.jp/cm/analytics-database/table_dbd.html
Step3:SQLの再実行
SQLを再実行して、エラーが解消されたことを確認します。
Step4:実行計画の確認
再度実行計画を取得して、統計情報と最適化の状態を確認します。
EXPLAIN SELECT * FROM table1 AS a INNER JOIN table2 AS b ON a.col1=b.col1;
Access Path:
...
| Join Cond: (a.col1 = b.col1)
| +-- Outer -> STORAGE ACCESS for a [Cost: 16, Rows: 7] (PATH ID: 2)
| | Projection: public.table1_DBD_1_rep_sp2
...
| +-- Inner -> STORAGE ACCESS for b [Cost: 13, Rows: 3★] (PATH ID: 3)
| | Projection: public.table2_DBD_1_rep_sp3★
...Step1 で確認した(NO STATISTICS) の出力が消えています。統計情報が取得されたことが分かります。
また、プロジェクションの名前も、_super から_rep に変更されています。プロジェクションの最適化が実行されたことが分かります。
※”rep”はレプリケーションの略です。複数ノード構成の場合はセグメンテーションの略で”seg”と出力される場合もあります。セグメンテーションについては、以下をご確認ください。
・セグメンテーションとレプリケーションの概要
https://www.ashisuto.co.jp/cm/analytics-database/segmentation_replication_overview.html
Step5:SQLのメモリ使用量を確認
エラー発生時のSQLとStep3で実行したSQLのメモリ使用量を比較し、Step3で実行したSQLのメモリ使用量が少なくなっていることを確認します。
query_requestsシステムテーブルからメモリ使用量を確認することができます。以下はコマンドの例です。このコマンドは、SQLの開始時間、終了時間、SQL文、実行時間、メモリ使用サイズが確認できます。
SELECT
node_name,
DATE_TRUNC('second',start_timestamp::TIMESTAMP) start_time,
DATE_TRUNC('second',end_timestamp::TIMESTAMP) end_time,
LEFT(REQUEST,100) query,
ROUND((request_duration_ms/1000)::NUMERIC(9,2),2) request_duration_sec,
CAST(memory_acquired_mb/1024 as numeric(9,2)) as memory_gb
FROM
query_requests
WHERE
request ILIKE '% select %'
AND start_timestamp BETWEEN '2022-08-04 08:00:00' AND '2022-08-04 18:00:00'
ORDER BY
node_name,
start_time ;query_requestsシステムテーブルで参照できる情報については、以下マニュアルをご確認ください。
・QUERY_REQUESTS
https://www.vertica.com/docs/12.0.x/HTML/Content/Authoring/SQLReferenceManual/SystemTables/MONITOR/QUERY_REQUESTS.htm
対処方法④ クエリスペシフィックプロジェクションの作成
特定のSQLで発生している場合は、クエリスペシフイックプロジェクションを作成することで、エラーが解消する可能性があります。クエリスペシフイックプロジェクションで結合列がソートされ、結合方法に「Merge Join」が使用されるようになる場合があります。
クエリスペシフィックプロジェクションは、Administration Tools、またはManagement Consoleを使用して作成できます。作成方法は以下をご確認ください。
・Administration Toolsを利用したクエリスペシフィックプロジェクションの作成方法
https://www.ashisuto.co.jp/cm/analytics-database/create-query-specific-projection-admintools.html
・Management Consoleを利用したクエリスペシフィックプロジェクションの作成方法
https://www.ashisuto.co.jp/cm/analytics-database/create-query-specific-projection.html
クエリスペシフィックプロジェクションを作成した後、SQLを再実行して、エラーが解消されたことをご確認ください。
対処方法⑤ SQLのチューニング
特定のSQLで発生している場合、SQLの構造を見直して処理に必要なメモリサイズを小さくすることで、エラーが解消する可能性があります。
チューニングの検討ポイントは、以下です。
1)SQLの中で選択している不要なカラムがある場合は取り除き、必要なカラムのみを選択する。
2)中間結果セットが小さくなるよう結合順序を変更する、もしくはSQLを分割する。
3)JOINを実行しないようにSQLを変更する。
4)Hash JoinではなくMerge Joinが使用されるように実行計画を変更する。
1)~3)は、Vertica独自の改修方法はなく、通常のSQLチューニングとなりますので、試行錯誤しながらの改修となります。4)は、Vertica独自の改修方法がありますので、ここでは4)についてご説明します。
改修前のSQLの実行計画を確認すると、結合キー列(c1)がソートされていないため、「Hash Join」が選択されていることが分かります。
explain select f.* from f left join d on d.c1 = f.c1;
Access Path:
...
+-JOIN HASH★ [LeftOuter] [Cost: 0, Rows: 0] (PATH ID: 1) Outer (LOCAL ROUND ROBIN)
| Join Cond: (d.c1 = f.c1)
| +-- Outer -> SELECT [Cost: 0, Rows: 0] (PATH ID: 2)
| +-- Inner -> SELECT [Cost: 0, Rows: 0] (PATH ID: 3)
...「Merge Join」が使用されるようにするためのSQL改修方法は2つあります。
・結合列をソートするように改修
・SQLヒントを指定するように改修
結合列をソートするように改修
order by句を使用して、結合列をソートすることで、「Merge Join」が使用されるようになります。
explain select f.* from (select * from f order by 1★) f left join
(select * from d order by 1★) d on d.c1 = f.c1;
Access Path:
+-JOIN MERGEJOIN★(inputs presorted) [LeftOuter] [Cost: 0, Rows: 0] (PATH ID: 1)
| Join Cond: (d.c1 = f.c1)
| +-- Outer -> SELECT [Cost: 0, Rows: 0] (PATH ID: 2)
| | +---> SORT [Cost: 0, Rows: 0] (PATH ID: 3)
| | | Order: f.c1 ASC
| +-- Inner -> SELECT [Cost: 0, Rows: 0] (PATH ID: 5)
| | +---> SORT [Cost: 0, Rows: 0] (PATH ID: 6)
| | | Order: d.c1 ASCSQLヒントを指定するように改修
JTYPEヒントを使用して、「Merge Join」が使用されるよう指定します。
※JTYPEヒントを使用する時は、SYNTACTIC_JOINヒントも含める必要があります。
SYNTACTIC_JOINヒントがない場合は、ヒントは無視されますのでご注意ください。
explain select /*+ SYNTACTIC_JOIN */ ★f.* from f left join /*+ JTYPE(FM) */ ★
d on d.c1 = f.c1;
Access Path:
+-JOIN MERGEJOIN★(inputs presorted) [LeftOuter] [Cost: 0, Rows: 0] (PATH ID: 1)
Outer (SORT ON JOIN KEY) Inner (SORT ON JOIN KEY)
| Join Cond: (d.c1 = f.c1)
| +-- Outer -> SELECT [Cost: 0, Rows: 0] (PATH ID: 2)
| +-- Inner -> SELECT [Cost: 0, Rows: 0] (PATH ID: 3)JTYPEヒントで指定できる結合タイプ
FM:強制的にMerge Joinで処理。マージを実行する前に、結合対象の列を再ソートする。
H:「Hash Join」で処理。
M:「Merge Join」で処理。結合対象の列がソートされている場合のみ有効。ソートされていない場合は、Verticaは無視する。
JTYPE(FM)の制約事項
・FMは、単純な結合処理でのみ有効。
・結合対象の列は、データ型、精度、スケールが同じでなければならない。
文字列型のカラム長は異なっていてもかまわない。
検証バージョンについて
この記事の内容はVertica 12.0で確認しています。
更新履歴
2022/08/19 本記事を公開