
はじめに
本記事は、Verticaのデータ配置方法をご紹介します。
セグメンテーションとは
複数ノード構成の場合、Verticaでは分散処理のために、サイズの大きなプロジェクションのデータを各ノードに分散して保持します。これをセグメンテーションといいます。これによりクエリ実行時のシェアードナッシングによる分散処理が実現され、パフォーマンスが向上します。
例)3ノード構成の場合のデータ分散イメージ

レプリケーションとは
複数ノード構成で、セグメンテーション化して分散するほどではない小さなプロジェクション(例 ディメンジョン表)の場合は、セグメンテーション化せずプロジェクションの完全コピーを各ノードに配置します。 Verticaではこれをレプリケーションといいます。
セグメンテーション/レプリケーションの使い分け
一般的には、ファクト表のようなサイズの大きなプロジェクションはセグメンテーション化し、ディメンジョン表のような小さなプロジェクションはレプリケーション化します。
これにより、ファクト表とディメンジョン表の結合処理時に各ノードのローカル内で結合処理が完結するようになります。ディメンジョン表もセグメンテーション化した場合と比べると、結合時のネットワークオペレーションが最小化されるため、より高速な処理が可能になります。
例)ローカル結合のイメージ

以下、レプリケーション化とセグメンテーション化を使い分ける必要性について具体的なイメージをご案内いたします。
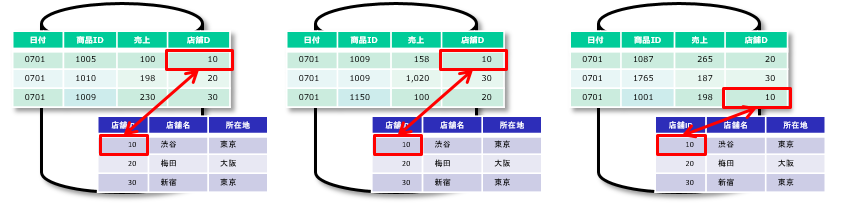
■ファクト表、ディメンジョン表ともにセグメンテーション化した場合
結合処理時に他のノードのデータを参照しなければならないケースが発生します。 例えば、店舗IDが10のデータの結合処理の場合はノード2、3は自身のノードで結合処理を完結できないため、非効率な処理となります。

■ファクト表をセグメンテーション化、ディメンジョン表をレプリケーション化した場合
ディメンジョン表をレプリケーション化しているため、結合処理時に必要なデータはすべて自身のノードにあります。 他のノードのデータを参照する必要がないため、効率の良い処理となります。
以上のように、必要に応じてレプリケーション化とセグメンテーション化を使い分ける必要がございます。
プロジェクションをセグメンテーションおよびレプリケーションする基準
Verticaでは、プロジェクションをレプリケーション化するか、セグメンテーション化するかは、Database Designerでプロジェクションを作成する際に以下のフローで自動的に判断します。
■自動判断フロー
1.プロジェクションの最適化中に、最適化対象の全プロジェクションのデータ件数をチェックする。
2.全プロジェクションの中で、最もデータ件数が多いプロジェクションを見つける。
3.「最もデータ件数が多いプロジェクション」と「それ以外のプロジェクション」のデータ件数を比較する。
4.比較結果に基づき、各プロジェクションを「セグメンテーション化」もしくは「レプリケーション化」する。
■判断基準

また、上記以外にセグメント化されないケースもございます。セグメントされないケースは以下2つです。
1.インスタンスが、単一ノードで構成されている。
2.対象のテーブルにLONG VARCHAR および LONG VARBINARY 列が含まれている。
セグメンテーション化されているか確認する方法
プロジェクションがセグメンテーション化されているか確認する場合は、projectionsテーブルを参照します。
例)LINEORDER_seg_b0プロジェクションを確認する場合
dbadmin=> SELECT * FROM projections WHERE projection_name='LINEORDER_seg_b0';
-[ RECORD 1 ]------------+--------------------------------------------------
projection_schema_id | 45035996273736160
projection_schema | ssbm
projection_id | 49539595901104158
projection_name | LINEORDER_seg_b0
projection_basename | LINEORDER_seg
owner_id | 45035996273704962
owner_name | dbadmin
anchor_table_id | 45035996273736164
anchor_table_name | LINEORDER
node_id | 0
node_name |
is_prejoin | f
created_epoch | 187
create_type | DESIGNER
verified_fault_tolerance | 1
is_up_to_date | t
has_statistics | t
is_segmented | t
segment_expression | hash(LINEORDER.LO_ORDERKEY)
segment_range | implicit range: v_test_node0003[33.3%]
v_test_node0001[33.3%]
v_test_node0002[33.3%]
is_super_projection | t
has_expressions | f
is_aggregate_projection | f
aggregate_type |
セグメンテーションの情報は以下の列で確認できます。
[projectionsシステムテーブル]
列名 | 内容 |
|---|---|
is_segmented | セグメンテーション化されている場合は「t」、レプリケーション化されている場合は「f」 |
segment_expression | セグメント方式※例の場合はLO_ORDERKEYをキーにハッシュ分散 |
segment_range | セグメント対象のノード及び、ノードごとのデータの分散状況(%) |
検証バージョンについて
この記事の内容はVertica 12.0で確認しています。