
Verticaはデータベース上でSQLを使った機械学習を実施することが可能です。
本記事ではVerticaの機械学習機能を利用してタイタニック号の乗客生存予測にチャレンジします。
使用するデータ
KaggleやSignate等で機械学習の初心者向けに公開されているデータセットである、タイタニックデータを使用します。

タイタニック号は1912年4月15日の早朝、氷山と衝突して大西洋に沈没しました。
タイタニックデータには、沈没時にタイタニック号に乗船していた乗客の名簿情報が格納されています。
この名簿情報を学習し、各乗客が「生存」したか「死亡」したかを予測していきます。
サンプルスキーマ、データのダウンロード
本記事では、Verticaが公開している機械学習のサンプルデータセットに含まれているタイタニックデータを使用します。
以下URLよりサンプルファイルをダウンロードします。
https://github.com/vertica/Machine-Learning-Examples
画面右上にある「Clone or Download」をクリックします。
展開される画面の右下にある「Download ZIP」をクリックしてファイルを保存します。
サンプルスキーマの作成、データのロード
ダウンロードしたファイルをVerticaサーバ上の任意のディレクトリに転送します。
転送後、以下コマンドでファイルを解凍します。
$ cd
$ unzip Machine-Learning-Examples-master.zip解凍後に以下コマンドでサンプルスキーマとテーブルの作成、データロードを実行します。
$ cd Machine-Learning-Examples-master/data
$ /opt/vertica/bin/vsql -d <データベース名> -w <パスワード> -f load_ml_data.sql
DROP TABLE
DROP TABLE
DROP TABLE
CREATE TABLE
~途中、省略~
COMMIT
CREATE TABLE
CREATE TABLEデータの確認
本記事ではtitanic_trainingを使用します。
\x
SELECT * FROM titanic_training LIMIT 1;
-[ RECORD 1 ]------------+------------------------
passenger_id | 1
survived | 0
pclass | 3
name | Braund, Mr. Owen Harris
sex | male
age | 22
sibling_and_spouse_count | 1
parent_and_child_count | 0
ticket | A/5 21171
fare | 7.25
cabin |
embarkation_point | S各列の意味は以下の通りです。
パラメータ名 | 意味 |
|---|---|
passenger_id | 乗客のID |
survived | 生死情報 |
pclass | 乗客のクラス |
name | 乗客名 |
sex | 性別 |
age | 年齢 |
sibling_and_spouse_count | 兄弟および妻の人数 |
parent_and_child_count | 親および子の人数 |
ticket | チケット番号 |
fare | 乗船料金 |
cabin | キャビン番号 |
embarkation_point | 乗船地 |
まず、データ件数を確認します。
SELECT COUNT(*) FROM titanic_training;
COUNT
-------
815
(1 row)死亡(survived=0)、生存(survived=1)の割合も併せて確認します。
SELECT survived,COUNT(*) FROM titanic_training GROUP BY survived ORDER BY 1;
survived | COUNT
----------+-------
0 | 519
1 | 296
(2 rows)
SELECT 296 / 815 AS raito;
raito
----------------------
0.363190184049079755
(1 row)生存者データは全体の36%程度であることが確認できました。
次にSUMMARIZE_NUMCOL関数を利用して数値データの基本統計量を確認します。
SELECT SUMMARIZE_NUMCOL(* USING PARAMETERS exclude_columns = 'passenger_id,name,sex,ticket,cabin,embarkation_point' ) OVER() FROM titanic_training;
COLUMN | COUNT | MEAN | STDDEV | MIN | PERC25 | MEDIAN | PERC75 | MAX
--------------------------+-------+-------------------+-------------------+-----+--------+---------+---------+----------
age | 656 | 30.172256097561 | 14.3014190862079 | 1 | 21 | 29 | 39 | 80
fare | 815 | 33.1048303067484 | 50.7783288265627 | 0 | 7.925 | 14.4542 | 31.3875 | 512.3292
parent_and_child_count | 815 | 0.376687116564418 | 0.810978914656903 | 0 | 0 | 0 | 0 | 6
pclass | 815 | 2.29325153374233 | 0.843323892994739 | 1 | 1 | 3 | 3 | 3
sibling_and_spouse_count | 815 | 0.532515337423313 | 1.10665195736505 | 0 | 0 | 0 | 1 | 8
survived | 815 | 0.36319018404908 | 0.481214303403728 | 0 | 0 | 0 | 1 | 1
(6 rows)次に文字データも含む全列の欠損の有無を確認します。
\x
SELECT COUNT(*) - COUNT(passenger_id) AS passenger_id,
COUNT(*) - COUNT(survived) AS survived,
COUNT(*) - COUNT(pclass) AS pclass,
COUNT(*) - COUNT(name) AS name,
COUNT(*) - COUNT(sex) AS sex,
COUNT(*) - COUNT(age) AS age,
COUNT(*) - COUNT(sibling_and_spouse_count) AS sibling_and_spouse_count,
COUNT(*) - COUNT(parent_and_child_count) AS parent_and_child_count,
COUNT(*) - COUNT(ticket) AS ticket,
COUNT(*) - COUNT(fare) AS fare,
COUNT(*) - COUNT(cabin) AS cabin,
COUNT(*) - COUNT(embarkation_point) AS embarkation_point
FROM titanic_training;
-[ RECORD 1 ]------------+----
passenger_id | 0
survived | 0
pclass | 0
name | 0
sex | 0
age | 159
sibling_and_spouse_count | 0
parent_and_child_count | 0
ticket | 0
fare | 0
cabin | 622
embarkation_point | 2age列、cabin列、embarkation_point列に欠損データがあることがわかります。
データ準備
タイタニックデータに限らず、集めたデータをそのまま機械学習で利用できることは滅多にありません。
まずは、機械学習で利用できるようにデータを加工していきます。
欠損値の補完
欠損データがあると、その行は学習データとして利用できません。そのためage列、cabin列の欠損値を補完します。
cabin列は欠損データが多すぎるため、補完は行わず学習の対象から除外します。
欠損値の補完はIMPUTE関数を使用します。
まずはage列の欠損データを補完します。今回はpclass、sex列のパーティションごとの平均値で補完します。
SELECT IMPUTE('titanic_training_age_impute','titanic_training', 'age','mean'
USING PARAMETERS partition_columns='pclass,sex');
IMPUTE
--------------------------
Finished in 1 iteration
(1 row)補完後のデータはtitanic_training_age_imputeビューを検索すると確認できます。
次に、embarkation_point列の欠損データを補完します。今回は全データの最頻値で補完します。
SELECT IMPUTE('titanic_training_embark_impute','titanic_training_age_impute', 'embarkation_point','mode');
IMPUTE
--------------------------
Finished in 1 iteration
(1 row)上記にて、age列、embarkation_point列の欠損データが補完されたtitanic_training_embark_imputeビューが作成されました。
再度欠損データを確認するとage列、embarkation_point列の結果が「0」(欠損なし)になっていることが確認できます。
\x
SELECT COUNT(*) - COUNT(passenger_id) AS passenger_id,
COUNT(*) - COUNT(survived) AS survived,
COUNT(*) - COUNT(pclass) AS pclass,
COUNT(*) - COUNT(name) AS name,
COUNT(*) - COUNT(sex) AS sex,
COUNT(*) - COUNT(age) AS age,
COUNT(*) - COUNT(sibling_and_spouse_count) AS sibling_and_spouse_count,
COUNT(*) - COUNT(parent_and_child_count) AS parent_and_child_count,
COUNT(*) - COUNT(ticket) AS ticket,
COUNT(*) - COUNT(fare) AS fare,
COUNT(*) - COUNT(cabin) AS cabin,
COUNT(*) - COUNT(embarkation_point) AS embarkation_point
FROM titanic_training_embark_impute;
-[ RECORD 1 ]------------+----
passenger_id | 0
survived | 0
pclass | 0
name | 0
sex | 0
age | 0 ★
sibling_and_spouse_count | 0
parent_and_child_count | 0
ticket | 0
fare | 0
cabin | 622
embarkation_point | 0 ★新しい特徴量の生成
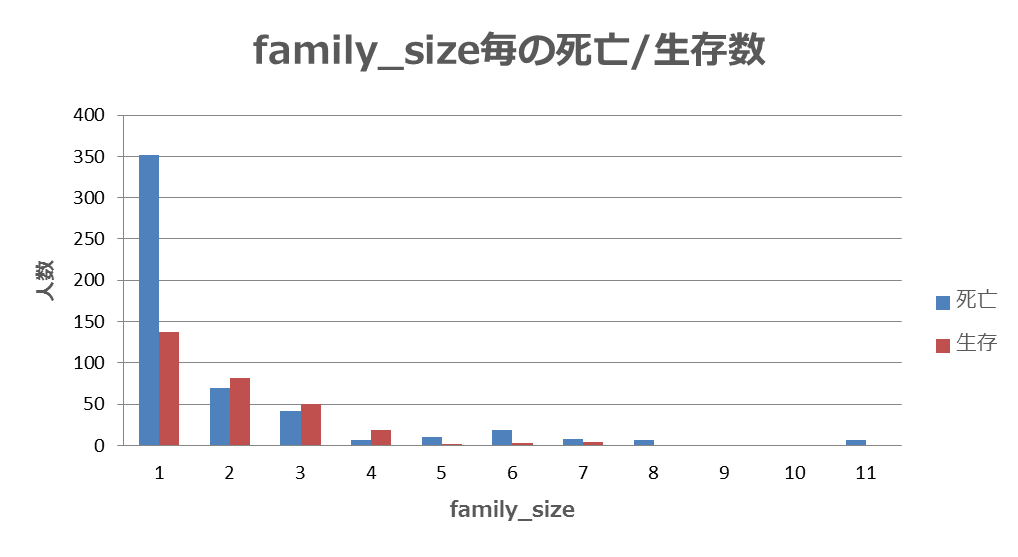
家族の人数と死亡/生存者数を確認すると、家族の人数が死亡 or 生存に影響を及ぼす可能性が考えられます。
※sibling_and_spouse_count(兄弟および妻の人数)、parent_and_child_count(親および子の人数)に本人(+1)を足した値を家族の人数(family_size)とする
そのため、以下のSQLでfamily_size(家族の人数)という新たな特徴量を生成します。
CREATE VIEW titanic_training_add_family_size AS
SELECT *,
(sibling_and_spouse_count + parent_and_child_count + 1) AS family_size
FROM titanic_training_embark_impute;以下のようにfamily_size列が追加されました。
\x
SELECT * FROM titanic_training_add_family_size LIMIT 1;
-[ RECORD 1 ]------------+------------------------
passenger_id | 1
survived | 0
pclass | 3
name | Braund, Mr. Owen Harris
sex | male
age | 22
sibling_and_spouse_count | 1
parent_and_child_count | 0
ticket | A/5 21171
fare | 7.25
cabin |
embarkation_point | S
family_size | 2 ★One-hot表現変換
データ内にはカテゴリデータがいくつか含まれているため、One-hot表現に変換します。
One-hot表現変換はONE_HOT_ENCODER関数を使用します。
SELECT ONE_HOT_ENCODER_FIT('titanic_encoder', 'titanic_training_add_family_size', 'pclass,sex, embarkation_point');
ONE_HOT_ENCODER_FIT
---------------------
Success
(1 row)上記にて、sex列、embarkation_point列をOne-hot表現に変換するためのエンコーダ(titanic_encoder)が作成されました。
次に、APPLY_ONE_HOT_ENCODER関数でtitanic_encoderを使用して、One-hot表現変換を実行します。
その際、今回学習に使用しないname列、ticket列、cabin列、sex列、embarkation_point列は選択リストから除外します。
CREATE VIEW titanic_training_encoded AS
SELECT passenger_id,
survived,
pclass_0 AS pclass1,
pclass_1 AS pclass2,
pclass_2 AS pclass3,
sex_0 AS female,
sex_1 AS male,
age,
fare,
embarkation_point_0 AS C,
embarkation_point_1 AS Q,
embarkation_point_2 AS S,
family_size
FROM
(SELECT APPLY_ONE_HOT_ENCODER(* USING PARAMETERS model_name='titanic_encoder' ,drop_first='false')
FROM titanic_training_add_family_size
) ohe;ここまでで、以下のような学習データができあがりました。
SELECT * FROM titanic_training_encoded LIMIT 10;
passenger_id | survived | pclass1 | pclass2 | pclass3 | female | male | age | fare | C | Q | S | family_size
--------------+----------+---------+---------+---------+--------+------+-----+---------+---+---+---+-------------
1 | 0 | 0 | 0 | 1 | 0 | 1 | 22 | 7.25 | 0 | 0 | 1 | 2
2 | 1 | 1 | 0 | 0 | 1 | 0 | 38 | 71.2833 | 1 | 0 | 0 | 2
3 | 1 | 0 | 0 | 1 | 1 | 0 | 26 | 7.925 | 0 | 0 | 1 | 1
4 | 1 | 1 | 0 | 0 | 1 | 0 | 35 | 53.1 | 0 | 0 | 1 | 2
5 | 0 | 0 | 0 | 1 | 0 | 1 | 35 | 8.05 | 0 | 0 | 1 | 1
6 | 0 | 0 | 0 | 1 | 0 | 1 | 26 | 8.4583 | 0 | 1 | 0 | 1
7 | 0 | 1 | 0 | 0 | 0 | 1 | 54 | 51.8625 | 0 | 0 | 1 | 1
8 | 0 | 0 | 0 | 1 | 0 | 1 | 2 | 21.075 | 0 | 0 | 1 | 5
9 | 1 | 0 | 0 | 1 | 1 | 0 | 27 | 11.1333 | 0 | 0 | 1 | 3
10 | 1 | 0 | 1 | 0 | 1 | 0 | 14 | 30.0708 | 1 | 0 | 0 | 2
(10 rows)正規化
最後に、One-hot表現以外の列の正規化を行います。本記事ではminmax法を使用します。
正規化はNORMALIZE関数を使用します。
SELECT NORMALIZE_FIT('titanic_training_normfit', 'titanic_training_encoded',
'age,fare,family_size', 'minmax'
USING PARAMETERS output_view='titanic_training_final');
NORMALIZE_FIT
---------------
Success
(1 row)以上でデータ準備は完了です。最終的には以下のデータができあがりました。
SELECT * FROM titanic_training_final LIMIT 10;
passenger_id | survived | pclass1 | pclass2 | pclass3 | female | male | age | fare | C | Q | S | family_size
--------------+----------+---------+---------+---------+--------+------+--------------------+--------------------+---+---+---+-------------------
1 | 0 | 0 | 0 | 1 | 0 | 1 | 0.265822798013687 | 0.014151057228446 | 0 | 0 | 1 | 0.100000001490116
2 | 1 | 1 | 0 | 0 | 1 | 0 | 0.468354433774948 | 0.139135733246803 | 1 | 0 | 0 | 0.100000001490116
3 | 1 | 0 | 0 | 1 | 1 | 0 | 0.316455692052841 | 0.0154685694724321 | 0 | 0 | 1 | 0
4 | 1 | 1 | 0 | 0 | 1 | 0 | 0.430379748344421 | 0.103644296526909 | 0 | 0 | 1 | 0.100000001490116
5 | 0 | 0 | 0 | 1 | 0 | 1 | 0.430379748344421 | 0.0157125536352396 | 0 | 0 | 1 | 0
6 | 0 | 0 | 0 | 1 | 0 | 1 | 0.316455692052841 | 0.0165095012634993 | 0 | 1 | 0 | 0
7 | 0 | 1 | 0 | 0 | 0 | 1 | 0.670886099338531 | 0.101228855550289 | 0 | 0 | 1 | 0
8 | 0 | 0 | 0 | 1 | 0 | 1 | 0.0126582281664014 | 0.041135661303997 | 0 | 0 | 1 | 0.400000005960464
9 | 1 | 0 | 0 | 1 | 1 | 0 | 0.329113930463791 | 0.0217307545244694 | 0 | 0 | 1 | 0.200000002980232
10 | 1 | 0 | 1 | 0 | 1 | 0 | 0.164556965231895 | 0.0586942918598652 | 1 | 0 | 0 | 0.100000001490116
(10 rows)予測モデルの作成(学習)/評価
Cross-Validation(交差検証)
本記事では、Cross-Validation(交差検証)を利用して予測モデルを作成し、評価ます。
Cross-Validationを実施するには、CROSS_VALIDATE関数を使用します。
なお、利用する予測モデルはCROSS_VALIDATE関数で利用可能なサポートベクターマシン(SVM)、ナイーブベイズ、ロジスティック回帰の3つです。また評価指標としてaccuracyとAUCを使用します。
サポートベクターマシン
SELECT CROSS_VALIDATE('svm_classifier', 'titanic_training_final', 'survived', '*'
USING PARAMETERS exclude_columns='passenger_id,survived',
cv_fold_count= 6,
cv_hyperparams='{"class_weights":"auto"}',
cv_model_name='titanic_classifier_svm',
cv_metrics='accuracy,auc_roc');
CROSS_VALIDATE
----------------------------------
Finished
===========
run_average
===========
class_weights|accuracy|auc_roc
-------------+--------+--------
auto | 0.79332| 0.85165
(1 row)ナイーブベイズ
SELECT CROSS_VALIDATE('naive_bayes', 'titanic_training_final', 'survived', '*'
USING PARAMETERS exclude_columns='passenger_id,survived',
cv_fold_count= 6,
cv_model_name='titanic_classifier_nb',
cv_metrics='accuracy,auc_roc');
CROSS_VALIDATE
----------------------------------
Finished
===========
run_average
===========
accuracy|auc_roc
--------+--------
0.79399| 0.16310
(1 row)ロジスティック回帰
SELECT CROSS_VALIDATE('logistic_reg', 'titanic_training_final', 'survived', '*'
USING PARAMETERS exclude_columns='passenger_id,survived',
cv_fold_count= 6,
cv_hyperparams='{"optimizer":"BFGS","max_iterations ":1000}',
cv_model_name='titanic_classifier_lr',
cv_metrics='accuracy,auc_roc');
CROSS_VALIDATE
----------------------------------
Finished
===========
run_average
===========
max_iterations |optimizer|accuracy|auc_roc
---------------+---------+--------+--------
1000 | BFGS | 0.81761| 0.84883
(1 row)本記事ではAUCが一番高いサポートベクターマシンを採用することにします。
グリッドサーチ
次に、サポートベクターマシンのハイパーパラメータをチューニングします。
引き続きCROSS_VALIDATE関数を使用します。今回はC(コスト)パラメータのグリッドサーチを行い、最適なパラメータ値を見つけます。
SELECT CROSS_VALIDATE('svm_classifier', 'titanic_training_final', 'survived', '*'
USING PARAMETERS exclude_columns='passenger_id,survived',
cv_fold_count= 6,
cv_hyperparams='{"class_weights":"auto","C":[1,10,100,1000,5000]}',
cv_model_name='titanic_classifier_svm2',
cv_metrics='accuracy,auc_roc');
CROSS_VALIDATE
----------------------------------
Finished
===========
run_average
===========
C |class_weights|accuracy|auc_roc
----+-------------+--------+--------
1 | auto | 0.80886|| 0.85290
10 | auto | 0.80890|| 0.85132
100 | auto | 0.80890|| 0.85128
1000| auto | 0.80890|| 0.85135 ★
5000| auto | 0.80890|| 0.85135accuracyはC >= 100は変化がありません。AUCはC=1000が一番良い精度となりました。
そのため、今回はC=1000を採用します。
予測モデルの実装
サポートベクターマシンを利用した予測モデルの作成を行います。作成時のC(コスト)パラメータは、上記結果のC=100を採用します。
サポートベクターマシンを利用したモデル作成はSVM_CLASSIFIER関数を使用します。
SELECT SVM_CLASSIFIER(
'titanic_classifier_svm_final', 'titanic_training_final', 'survived', '*'
USING PARAMETERS exclude_columns = 'passenger_id,survived',class_weights='auto',C=1000);
SVM_CLASSIFIER
----------------------------------------------------------------
Finished in 4 iterations.
Accepted Rows: 815 Rejected Rows: 0
(1 row)作成したモデルのサマリー情報はGET_MODEL_SUMMARY関数で確認できます。
SELECT GET_MODEL_SUMMARY (USING PARAMETERS model_name= 'titanic_classifier_svm_final');
GET_MODEL_SUMMARY
------------------------------------------------------------
=======
details
=======
predictor |coefficient
-----------+-----------
Intercept | 0.26696
pclass1 | 0.43283
pclass2 | 0.11172
pclass3 | -0.27760
female | 0.66027
male | -0.39331
age | -0.92834
fare | 0.51699
c | 0.16736
q | 0.06182
s | 0.03778
family_size| -0.77327
===========
call_string
===========
SELECT svm_classifier('public.titanic_classifier_svm_final', 'titanic_training_final', '"survived"', '*'
USING PARAMETERS exclude_columns='passenger_id,survived', class_weights='0.785164,1.37669', C=1000, max_iterations=100, intercept_mode='regularized', intercept_scaling=1, epsilon=0.001);
===============
Additional Info
===============
Name |Value
------------------+-----
accepted_row_count| 815
rejected_row_count| 0
iteration_count | 5
(1 row)作成した予測モデルを呼び出して、予測結果を確認してみます。予測モデルの呼び出しはPREDICT_SVM_CLASSIFIER関数を使用します。
SELECT passenger_id,
survived,
PREDICT_SVM_CLASSIFIER (pclass1,pclass2,pclass3,female,male,age,fare,C,Q,S,family_size
USING PARAMETERS model_name='titanic_classifier_svm_final') AS Predicted
FROM titanic_training_final;
passenger_id | survived | Predicted
--------------+----------+-----------
1 | 0 | 0
2 | 1 | 1
3 | 1 | 1
4 | 1 | 1
5 | 0 | 0
6 | 0 | 0
7 | 0 | 0
8 | 0 | 0
9 | 1 | 1
10 | 1 | 1
11 | 1 | 1
12 | 1 | 1
・
・
・
888 | 1 | 1
890 | 1 | 1
891 | 0 | 0
(815 rows)以上で、タイタニック号の乗客生存予測チャレンジは終了です。
このように、Verticaでは機械学習で一般的に必要な操作を、全てVertica上でSQLを用いて実施することができます。

参考情報
Titanic: Machine Learning from Disaster (Kaggle)
https://www.kaggle.com/c/titanic
【練習問題】タイタニックの生存予測 (Signate)
https://signate.jp/competitions/102
検証バージョンについて
この記事の内容はVertica 9.1で確認しています。