


- AWS
AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説
この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します
![]()






|
|
ビジネスにおいてデータ活用は、今や欠かせないものとなっています。しかし、質の高いデータ活用基盤を構築することは、容易ではありません。データ活用をビジネスに取り入れても、思うように費用対効果が向上しないこともあります。あるいは、既存業務へのインパクトを懸念して、基盤の構築に踏み切れない企業もあるでしょう。
そのような中、データ活用のために「Amazon Web Services(AWS)」を利用されるお客様が増加しています。本稿では、AWSでデータ活用を行う際には欠かせない「Amazon Redshift」にフォーカスし、特徴や料金、使い方まで幅広くお伝えします。
※文中でご紹介するサービス画面は記事作成時点のものです。ご利用時は、サービスのアップデートによりUIに変更がある可能性があります。
Index
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
Amazon Redshiftとは、AWS上で提供されているデータウェアハウス専用のデータベースサービスです。あらゆるデータを構造化して蓄積し、高速に分析処理できることが大きな特徴です。
またAmazon Redshiftを用いることで、機械学習を用いた高度なデータ分析も可能です。拡張性・パフォーマンスに優れたデータ活用基盤を構築できるため、企業のデジタルトランスフォーメーションが加速するでしょう。
|
|
Amazon Redshiftは、PostgreSQLをベースに開発されました。そのため、PostgreSQLに馴染んでいる方は、同じような感覚で違和感なく利用できます。しかし、Amazon Redshiftは大規模データ分析(OLAP)専用として開発されているため、その内部構造や利用目的は大きく異なります。PostgreSQLはトランザクション処理(OLTP)に適しますが、Amazon RedshiftはDWHのような「データ分析用途」に特化して利用するデータベースと理解していただくと良いでしょう。
AWSの主なデータベースサービスには、Amazon Redshift以外にも「Amazon RDS」や「Amazon Aurora」があります。
Amazon RDSは、リレーショナルデータベースの構築や運用を支援するサービスです。ポピュラーなデータベースエンジンである「Oracle Database」や「PostgreSQL」などが用意されており、既存データベースのクラウド移行が容易に行えます。
またAmazon Auroraは、Amazon RDS の一つのサービスではありますが、クラウドのために再設計されたデータベースエンジンです。構成やコスト、パフォーマンスなど様々な独特な特徴があるので、「RDS」ではなく「Aurora」と区別して呼ばれることが多いです。Amazon AuroraはMy SQLとPostgreSQLのどちらかと互換性のあるタイプを指定して作成できます。
Amazon RDSやAmazon Auroraは、データ更新を得意とし、オンライントランザクション処理(OLTP)に使われます。一方で「Amazon RedshiftとPostgreSQLの違い」でも記載したようにAmazon Redshiftは高度なデータ分析を得意とし、大量データを高速に分析できることが特徴です。AWSでDWHやデータ分析基盤の構築を検討する際は、まずRedshiftが選択肢になることを覚えておきましょう。
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
Amazon Redshiftには、主に以下の4つの特徴があります。それぞれ、順番に解説します。
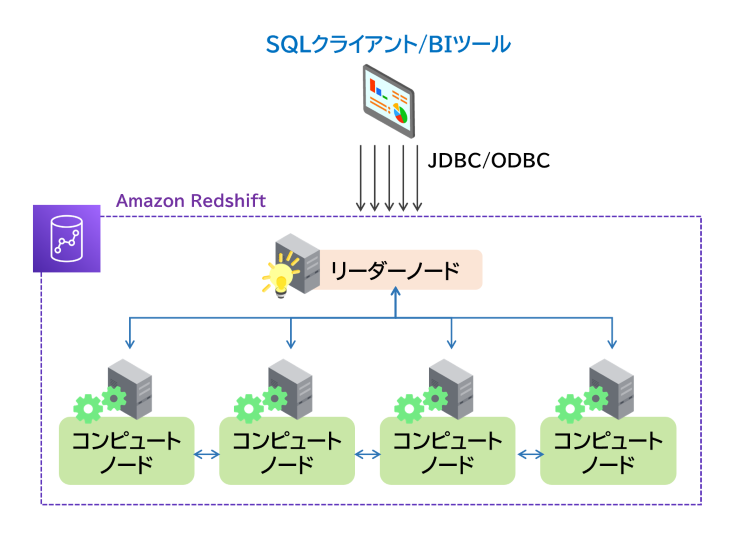
Amazon Redshiftに採用されている「MPP」(超並列処理アーキテクチャ)によって、高速なデータ処理が可能となります。MPPとは、複数のノードでSQLのクエリを分散処理できる仕組みのことです。オンプレミスで稼働するデータベースにMPPが搭載されている場合もありますが、ノードを追加するためにサーバを購入したり、セットアップしたりする必要があるため、すぐにノードを追加することはできません。Redshiftの場合、ノードを簡単に追加することが可能であるため、データ量が膨大な場合でも迅速なレスポンスを得ることができ、データ分析を高速化できます。
Amazon Redshiftの主な構成要素は、クエリを受け付ける1つの「リーダーノード」と、クエリを処理する複数の「コンピューティングノード」の2種類です。1つのクエリを複数のコンピューティングノードに並列実行させることで、ハイパフォーマンスを実現しています。
|
|
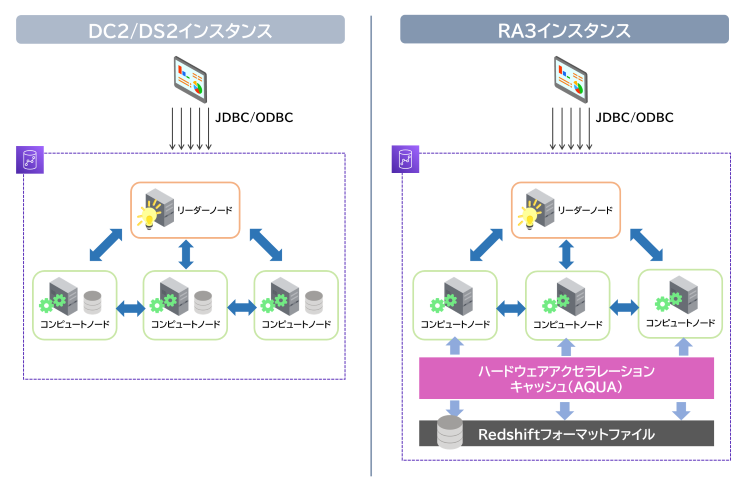
Amazon Redshiftには、「ノードタイプ」という概念があり、以下3種類のいずれかを指定して構築します。
・DC2インスタンス
DC2インスタンスは、各コンピューティングノードが個別のSSDストレージを持つタイプで、データ処理の独立性が高まりさらなるパフォーマンス向上につながります。
・DS2インスタンス
DS2インスタンスは、各コンピューティングノードが個別のHDDストレージを持つタイプで、速度面ではSSDを採用しているDC2インスタンスに及ばないものの、より大容量で構築することが可能です。しかし、次に紹介するRA3インスタンスにより代用可能なため、選択される機会が少なくなりつつあります。
・RA3インスタンス
RA3インスタンスは、データ処理とストレージを独立させる方式です。RA3インスタンスは、3つのノードタイプのうち、一番新しいものとなります。各ノードは個別のストレージを持たない代わりに、RMS(Redshift Managed Storage)を共有利用します。RMSは、ストレージサービス「Amazon S3」のデータ領域を内部的に利用します。ノードが軽量なため拡張性に優れ、必要な処理能力に応じたスケールアウトが容易です。また、アクセス頻度が高いデータは「AQUA」と呼ばれるキャッシュ領域で高速処理されます。
|
|
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
オンプレミスで構築したデータ活用基盤は、自社で物理サーバの運用や保守を行わなければなりません。データベースのチューニングやバックアップ、ソフトウェアの更新などを継続的に実施する必要があり、担当者に大きな負荷がかかります。
その点Amazon Redshiftでは、通常DWHで発生するタスクの多くを自動化・簡素化できます。例えば、代表的な機能の1つである「自動テーブル最適化」を使用すると、データ圧縮やソートキーを自動で設定できるため、担当者がデータベースの細かいチューニングを行う必要はありません。
またシステムの稼働状況は、後述の「Amazon Redshiftコンソール」によって可視化されます。システムのパフォーマンスに関する様々な項目が1画面に集約されており、日々のシステム監視を簡素化することが可能です。他にも、監査ログ取得やバージョンアップも自動で行われます。少ない人員でも運用しやすくなるのは、データ活用を実現する上で大きなメリットです。
複数のRedshiftクラスターを管理したり、その他のAWSサービスをまとめて監視したりする場合は、Amazon CloudWatchを使用するようにしましょう。
|
|
Amazon Redshiftに限らずAWSの料金体系は、基本的に従量課金制(オンデマンド方式)です。リソースを利用した分だけ費用が発生する方式のため、過剰なコストの発生を防止できます。
また、新たなデータ分析基盤を構築する際、その導入効果を事前に予測することは難しいため「まずはスモールスタートしたい」と考えることも多いでしょう。Redshiftは最小構成でスタートし、データ量やアクセス量に合わせて容易にノードを追加できるため、「小さく始めて大きく育てる」という要件を満たすことができます。
Amazon Redshiftには、様々なAWSサービスとの連携機能があります。
本稿では、代表的な2つの機能をご紹介します。
■フェデレーテッドクエリ
OLTP向けのデータベースサービスである、Amazon RDS for PostgreSQL、Amazon RDS for MySQL、Amazon Auroraに対して、Amazon Redshiftからクエリを実行できる機能です。
フェデレーテッドクエリを使用することで、外部データベースで保持しているデータをAmazon Redshiftにロードすることなく、クエリを実行することが可能です。
■Redshift Spectrum
データレイクに使用される、Amazon S3に対してクエリを実行できる機能です。
普段あまりアクセスしないデータをAmazon S3に格納しておき、Redshift Spectrumを使用してクエリを実行することで、Amazon Redshiftの保有するデータサイズを削減することが可能です。
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
ここではAmazon Redshiftの使い方として、①クラスターを作成し、②そのクラスターに接続する方法をご紹介します。
クラスターとは、Amazon Redshiftの管理単位です。構成要素として、リーダーノード、コンピュートノード、RMS(Redshift Managed Storage)があります。本稿では、クラスターの作成方法についてご説明します。
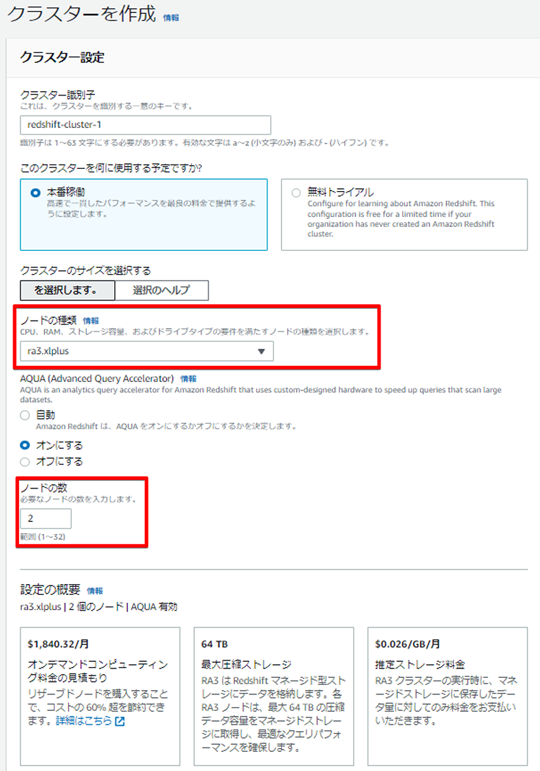
・ノードタイプとノード数の設定
ノードタイプ(DC2, DS2, RA3)とコンピュートノードの数を設定します。
ノードの種類や数が性能やコストに影響するため、小さいスペックを指定することで、スモールスタートをすることも可能です。
|
|
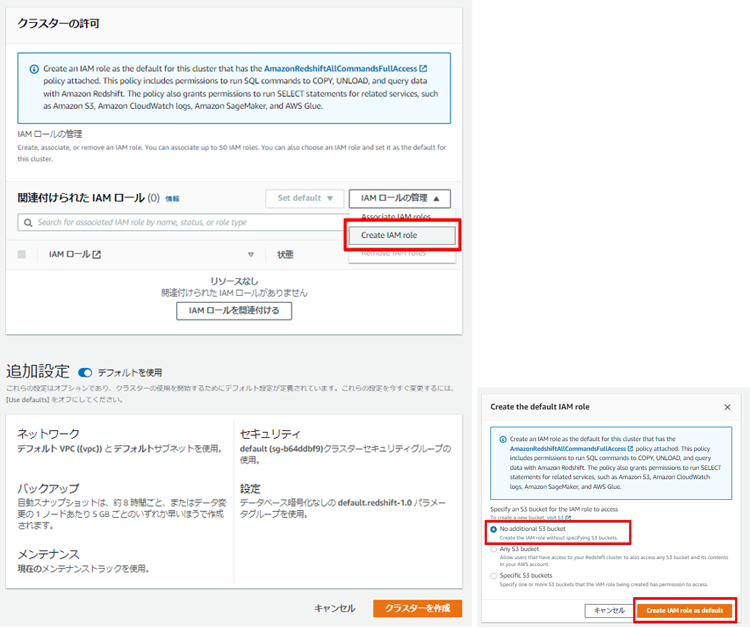
・IAMロールの設定
作成したRedshiftクラスターから別のAWSサービスへアクセスする場合、IAMロールが必要です。
Amazon S3へのアクセスが不要な場合は、「No additional S3 bucket」を選択しましょう。
IAMロールを設定することで、Amazon S3からAmazon Redshiftへデータをロードすることが可能になります。
|
|
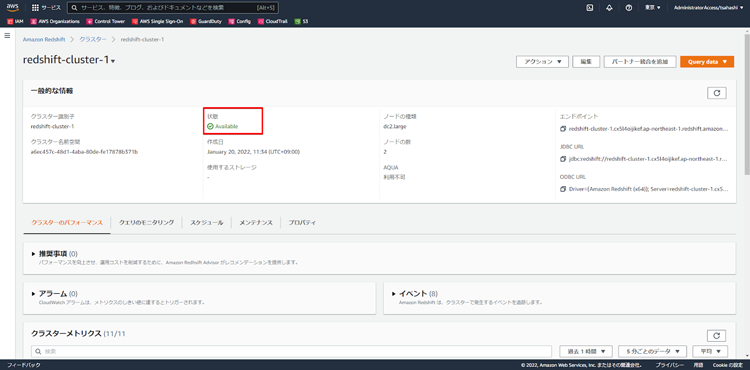
ネットワークやバックアップの設定をカスタマイズする場合は、「追加設定」から実施してください。入力が終わりましたら、「クラスターを作成」をクリックします。
「状態」が、Availableになれば、Redshiftクラスターの準備は完了です。BIツールやSQLクライアントを使い、クエリを実行してみましょう。
|
|
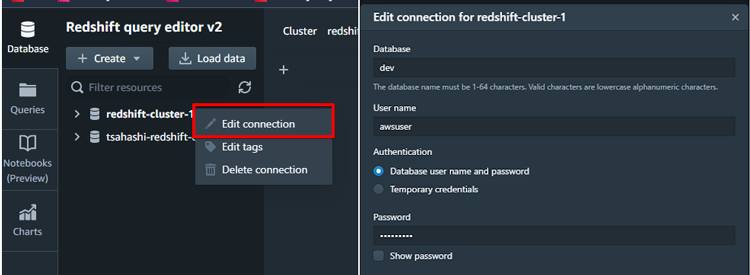
BIツールやSQLクライアント以外にも、Redshiftコンソールからクエリを実行する「クエリエディタ」があります。前手順で作成したクラスターに接続し、テスト用のテーブルを1つ作成します。
クラスター作成時に入力した、ユーザー名とパスワードを入力します。
|
|
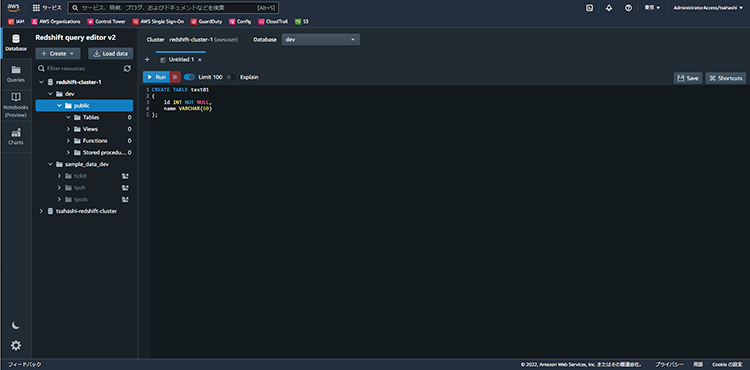
クラスターに接続できたことを確認し、CREATE TABLE文を実行してみます。
CREATE TABLE test01 ( id INT NOT NULL, name VARCHAR(60) );
|
|
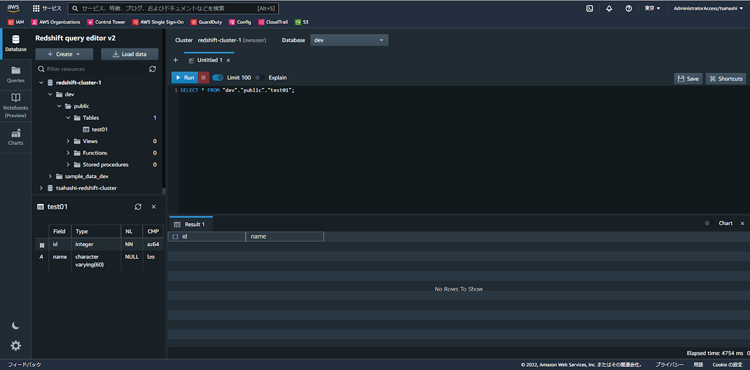
これで、test01テーブルが作成できました。クエリエディタからSELECT文でデータを参照する場合は以下のようになります。
SELECT * FROM "dev"."public"."test01";
|
|
簡単でしたが、Amazon Redshiftの利用イメージをつかんでいただけたでしょうか。
次に実際どのようなシーンでAmazon Redshiftが選択・活用されているのかご紹介します。
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
Amazon Redshiftの使用イメージをより具体化しやすくするために、主なユースケースを2つご紹介します。
・オンプレの情報系システムをクラウド移行し、運用負荷を軽減したユースケース
長年使い続けてきたオンプレミスの情報系システムが老朽化し、運用・保守にかかる大きな負荷の課題に対し、AWSへ移行。業務システムのバックエンドとしてAmazon Redshiftを採用し、リアルタイムなデータ分析を可能にしました。その結果、運用負荷を削減できたことはもちろん、社員が積極的なデータ分析を行うようになりました。また、データ分析に紙の書類や帳票を用いる必要がなくなり、ペーパーレス化によるコスト削減にもつながりました。
・データ活用基盤を最適化し、TCOを大幅に削減したユースケース
ビジネスの拡大とともにシステムが複雑化・冗長化し、効果的なデータ活用が推進できない課題に対し、データ活用基盤のAWS移行を実施。Amazon S3により統合的なデータレイクを構築し、コンピューティングには高速なAmazon Redshiftを採用。その結果、あらゆるデータを迅速に分析できるようになりました。また、従来よりも少ない人員で運用できるようになり、TCO(総所有コスト)を大幅に削減することにも成功しました。
最後に、Amazon Redshiftの料金についても解説します。AWSは利用した分だけ料金が発生する従量課金制です。Amazon Redshiftの場合は、データ処理を行うコンピューティングノードの利用時間とデータ格納先のストレージに対して課金されます。ただし、RA3インスタンスを適用している場合は、複数のコンピューティングノードで共用するRedshift Managed Strage(RMS)も課金対象となります。
コンピューティングノードは、リージョンごとに料金が異なる場合があるので、料金を確認する際は注意するようにしましょう。
また、1年以上Amazon Redshiftを利用する予定がある場合、「リザーブドノード」を適用することで、利用料を大幅に削減できる可能性があります。リザーブドノードを契約すると、一定期間(1年間もしくは3年間)の継続利用をあらかじめ約束する代わりに、割引を受けられます。
夜間や土日などの営業時間外に停止することなく、1年以上利用するのであれば、リザーブドノードを選択してコストを節約し、反対に夜間や土日などの営業時間外に停止することができる場合は、クラスターの停止によりコストを節約できる従量課金制(オンデマンド方式)を選択するようにするのが良いでしょう。
Amazon Redshiftの料金計算方法や料金を下げるポイントを解説した資料や、Amazon Redshiftを体験できる動画などにお申し込みいただけます。
今回はAmazon Redshiftの特徴や料金、使い方についてご紹介しました。
Amazon Redshiftとは、データウェアハウスを構築・運用できるAWSのサービスです。複数ノードでの分散処理により高速なデータ処理が可能な上に、運用を自動化・簡素化する様々な機能によって、運用担当者の負担も軽減できます。
また、Amazon Redshiftはクラウドサービスのため、ブラウザ操作で簡単に利用開始できるのも魅力です。従量課金制なので、スモールスタートでリスクを最小限に抑えられます。既存のデータ活用基盤に課題を感じている方は、Amazon Redshiftをぜひお試しください。

|
|---|
愛知県の文系大学を卒業し、2019年アシストに新卒で入社。
幼いころから社内SEである父を見て育ち、同じ業界に進むことを決意。配属後は、主にOracle CloudとAWSのフィールド業務を担当している。新人の頃から主にクラウドを担当し、アシスト内ではオンプレミスを触れていない"クラウド世代"の先陣を切っている。...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します

この記事では「AWS Control Towerとは?マルチアカウント管理を自動化する仕組み」をご紹介します

この記事ではAmazon QuickのチャットエージェントでMySQLなどのデータベースを検索・分析する方法を解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

