


- Snowflake
SoRとSoIで考えるデータ基盤の作り方 ― AI Readyを目指すためのセミナー見どころ紹介!
2026年7月24日開催のセミナー「AI活用の前に整えるべきデータ活用基盤とは」では、SoR(守り)とSoI(攻め)を分離し、既存の基幹系を生かしてAI Readyな基盤を構築する方法を解説。OracleとSnowflakeの役割分担や製品選定のヒントを知りたいデータベース技術者・アーキテクト必見です。
![]()






|
|
Snowflake(スノーフレーク)は、データウェアハウス(DWH)をはじめとした様々な機能を提供するAIデータクラウドです。
データの格納・処理・分析・共有・AI活用を一元的に担う基盤として、世界12,000社超、日本国内でも約700社以上の企業に採用されています。
本稿ではSnowflakeのアーキテクチャや特長を、初心者の方にも分かりやすく解説します。
Index
本稿を読むと、以下5つのSnowflakeのすごさが理解できます!
・シンプルさがすごい!
インフラや性能設計の複雑さをできるだけユーザーから遠ざけ、データ活用そのものに集中しやすいように設計
Snowflakeの魅力、それは「シンプルさ」です。
従来のデータ基盤では、性能設計やインフラ運用、リソース競合の調整など、データ活用の前に多くの複雑さと向き合う必要がありました。
一方、Snowflakeはそうした複雑さをできる限り排除し、データの格納・処理・共有・活用をよりシンプルに行えるように設計されています。
そのため、ユーザーはインフラ管理そのものではなく、本来注力すべきデータ分析や価値創出により多くの時間を使うことができ、データドリブン企業へ近づくアシストをしてくれます。
本稿では、Snowflakeがどのようなアーキテクチャ、特長を持ち合わせているのかをご紹介し、Snowflakeの魅力をお伝えいたします。
|
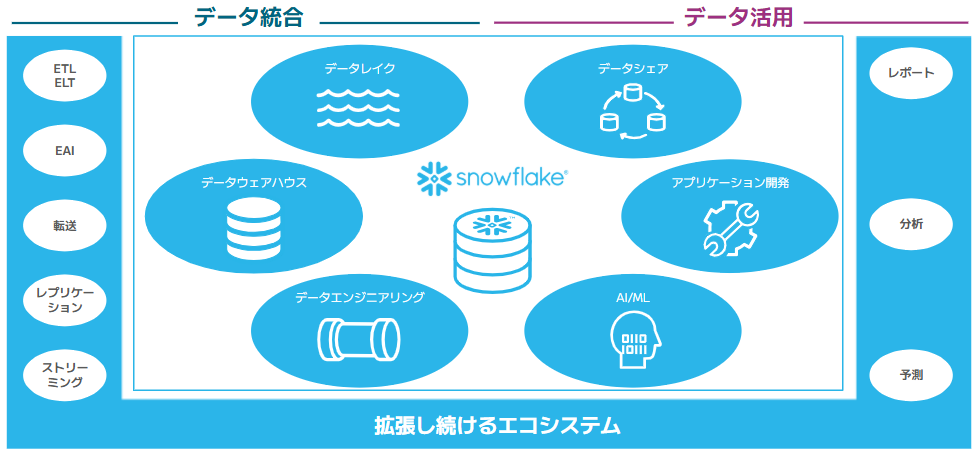
図1.Snowflakeの全体像
Snowflakeは2014年にクラウドネイティブなDWHとして登場して以来、データの保存・処理・分析にとどまらず、データ共有、データエンジニアリング、アプリケーション開発、AI / ML活用と機能領域を広げてきました。
そのため現在のSnowflakeは、単なるデータを保管するための器としての役割だけではなく、データ活用全体を支える基盤として進化を遂げています。特に最近はAI機能の進化が目まぐるしくCortex AIをはじめとした、ユーザーのデータ活用をアシストする機能が多く発表されており、さらにユーザーフレンドリーな製品へと変化しています。
AI機能に関する詳細はこちらも合わせてご覧ください。
・Snowflake Intelligenceについて
https://www.ashisuto.co.jp/product/category/datacloud/snowflake/snowflake-intelligence/#tab
・Snowflake Intelligenceで実現するデータドリブン - 構造化データと非構造化データを活用する生成AI「実践」- PARTⅠ
https://www.ashisuto.co.jp/db_blog/article/snowflake-intelligence_01.html
・Snowflake Intelligenceで実現するデータドリブン - 構造化データと非構造化データを活用する生成AI「実践」- PARTⅡ
https://www.ashisuto.co.jp/db_blog/article/snowflake-intelligence_02.html
また、SnowflakeはAmazon Web Services(AWS)、Microsoft Azure、Google Cloudの各クラウドプラットフォームで稼働をサポートしています。お客様がご利用中のクラウド環境にあわせてSnowflakeのホスティング先を選ぶことはもちろん、マルチクラウド環境でのご利用も可能です。
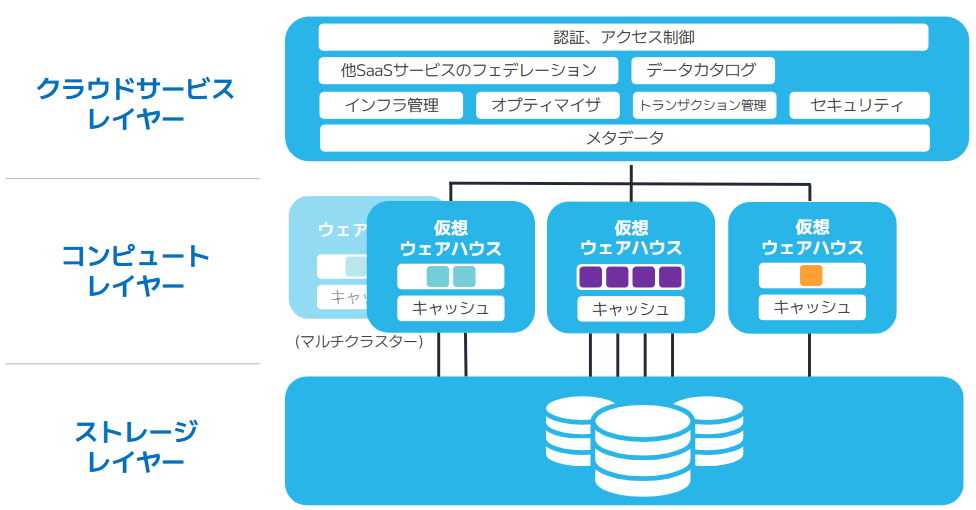
Snowflakeは「クラウドサービスレイヤー」、「コンピュートレイヤー」、「ストレージレイヤー」の3層で構成されています。それぞれの役割や特長は以下の通りです。
|
【クラウドサービスレイヤー】
ユーザー認証 / クエリ最適化 / メタデータ管理 / セキュリティ制御 などを担っており、Snowflakeの頭脳として機能しています。
ユーザーがインフラを意識せずとも安定してSnowflakeを利用できるのは、クラウドサービスレイヤーが土台を支えているからです。
【コンピュートレイヤー】
仮想ウェアハウスというコンピュートリソースが稼働しており、クエリを実行しデータを処理する役割を担っています。
仮想ウェアハウスとはCPUとメモリがセットになった、Snowflakeにおけるコンピュートオブジェクトのことです。用途に応じて性能や並列実行の台数を調整することができます。
【ストレージレイヤー】
実データを格納する役割を担っているレイヤーです。
Amazon S3や、Azure Blob Storage、Google Cloud Storageなどのオブジェクトストレージが内部的に使用されており、ユーザーはストレージ容量を気にすることなく、ほぼ無制限にデータを格納することができます。
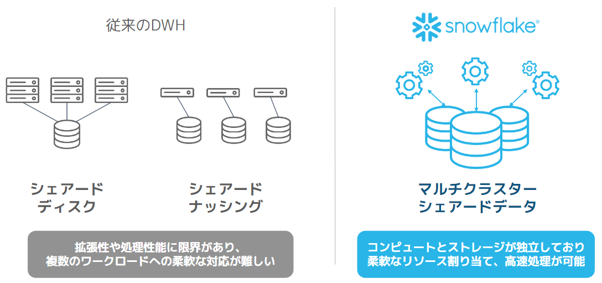
さらにSnowflakeではコンピュートレイヤーとストレージレイヤーが完全に独立して存在・稼働しています。これをマルチクラスターシェアードデータ(multi-cluster, shared-data)と呼んでいます。
従来のDWHではストレージとコンピュートが密結合していることが多く、性能をあげたいときに不要なリソースまで一緒に増やさなければならないという課題がありました。
一方Snowflakeでは、データを1つの共有ストレージに保存したまま、必要な性能のコンピューティングリソースを、必要な時に、独立して追加・変更することができます。
この3層構造 × マルチクラスターシェアードデータにより、Snowflakeは高い拡張性と運用負担の最小化を実現しています。
|
ここからは前述のアーキテクチャを踏まえて、Snowflakeの特長を「仮想ウェアハウス」と「ストレージ」の2つの観点から紹介します
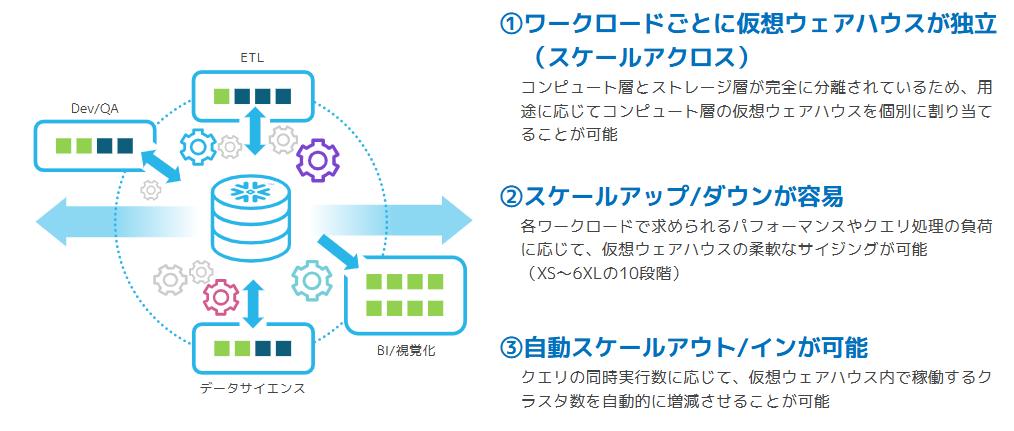
Snowflakeではコンピュートリソースのことを仮想ウェアハウスと呼んでいると紹介しました。この仮想ウェアハウスに関してSnowflakeは3つのスケーラビリティを備えています。
中でもスケールアクロスはSnowflakeのストレージレイヤーとコンピュートレイヤーが独立して存在しているため、実現できるユニークなスケーラビリティとなっています。
実際の運用をイメージして、Snowflakeの拡張性を理解しましょう。
例えば、社内では同じデータ基盤に対してさまざまな処理が同時に走っています。
こうした処理は、求められる性能も優先度もそれぞれ異なります。
こういったケースでSnowflakeは各処理に対して、別々の仮想ウェアハウスを割り当てられるため、より柔軟に性能をコントロールし、リソース競合を起こすことなく、管理・実行が可能となります。
例えば今回のケースであれば、次のような使い分けが可能です。
このように用途ごとにコンピュートを分けて使える考え方をSnowflakeではスケールアクロスと呼んでいます。
さらにスケールアップ、スケールダウンについては、SnowflakeではGUIもしくはSQLベースで実行可能で、仮想ウェアハウスを停止することなくミリ秒単位で変更可能です。スケールアウトに関しても、あらかじめ最小台数・最大台数を設定しておくことで負荷に応じて自動的にスケールアウト / インさせることも可能です。
|
以上、Snowflakeは3つのスケーラビリティを持って、ユーザーに優れた拡張性を提供しています。
Snowflakeのストレージは、単にデータを保存するための入れ物ではありません。
データを効率よく処理するための仕組みや、ストレージ消費を抑える仕組み、さらに誤操作からデータを守る仕組みまで備えています。
本章では、そうしたSnowflakeのストレージ機能の中から、マイクロパーティション / クローン / タイムトラベル / データ共有を取り上げて解説します。
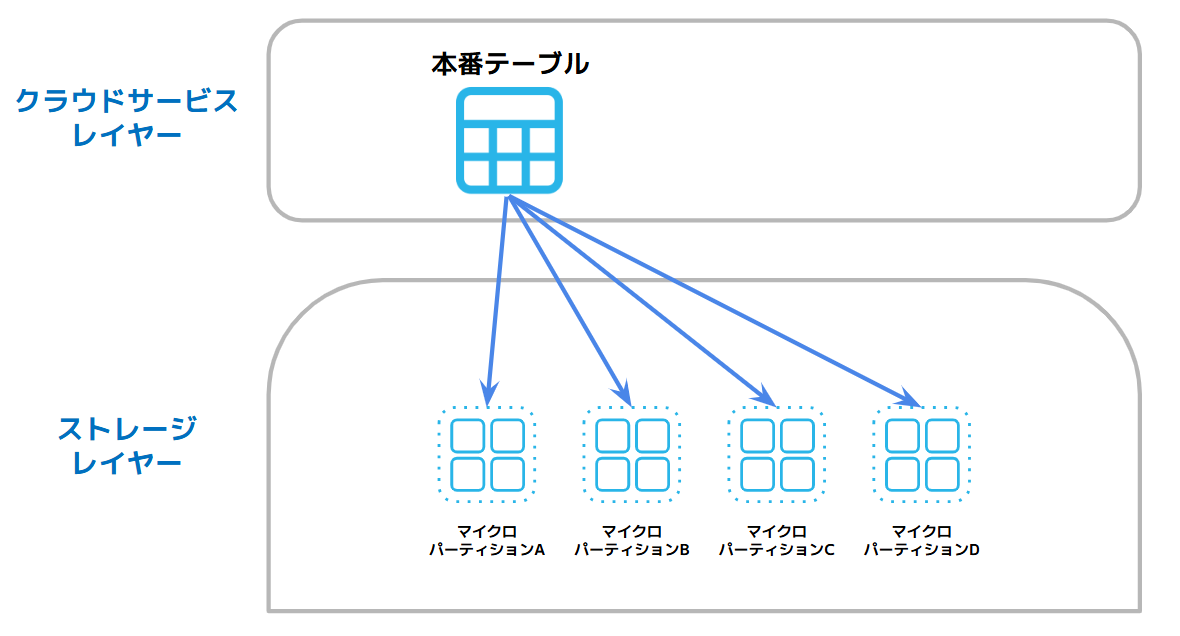
Snowflakeのストレージを知るうえで、まず初めに押さえておきたいのがマイクロパーティションです。
これはSnowflakeがデータを内部で区画分けし、管理するための保存単位で、Snowflakeの高速処理はマイクロパーティションによって実現しています。
|
従来のDWHでは、ユーザーがパーティション設計やメンテナンスを意識しなければならない場面が少なくありませんでした。
一方でSnowflakeでは、テーブルに格納されたデータは自動的にマイクロパーティションへ分割されます。ユーザー側で分割区分を細かく定義する必要性がなく、日々の運用でもパーティションを意識して管理する必要がありません。
マイクロパーティションにはデータが列指向で保存され、その中には圧縮前で50 MB~500 MBのデータが格納されます。さらにSnowflakeは、各マイクロパーティションに対して、各列の値の範囲や異なる値の数などのメタデータを保持しています。
このメタデータがあることで、Snowflakeはクエリ実行時にどのマイクロパーティションを読めばいいのかを効率よく判断することができるようになり、関係のないデータを読み飛ばす事ができるようになります。これをプルーニングと呼びます。
また、列指向で格納していることにより、必要な行の必要な列の値だけをスキャンできるようになり、リレーショナルデータベースと比較すると、大規模なデータに対しても無駄の少ない処理を実現できます。
総括すると、Snowflakeのマイクロパーティションはユーザーに複雑な管理を求めることなく、高速なクエリ性能と効率的なストレージ利用を両立するための仕組みとなっています。
Snowflakeの「シンプルさ」はこうしたストレージの内部設計にも現れています。
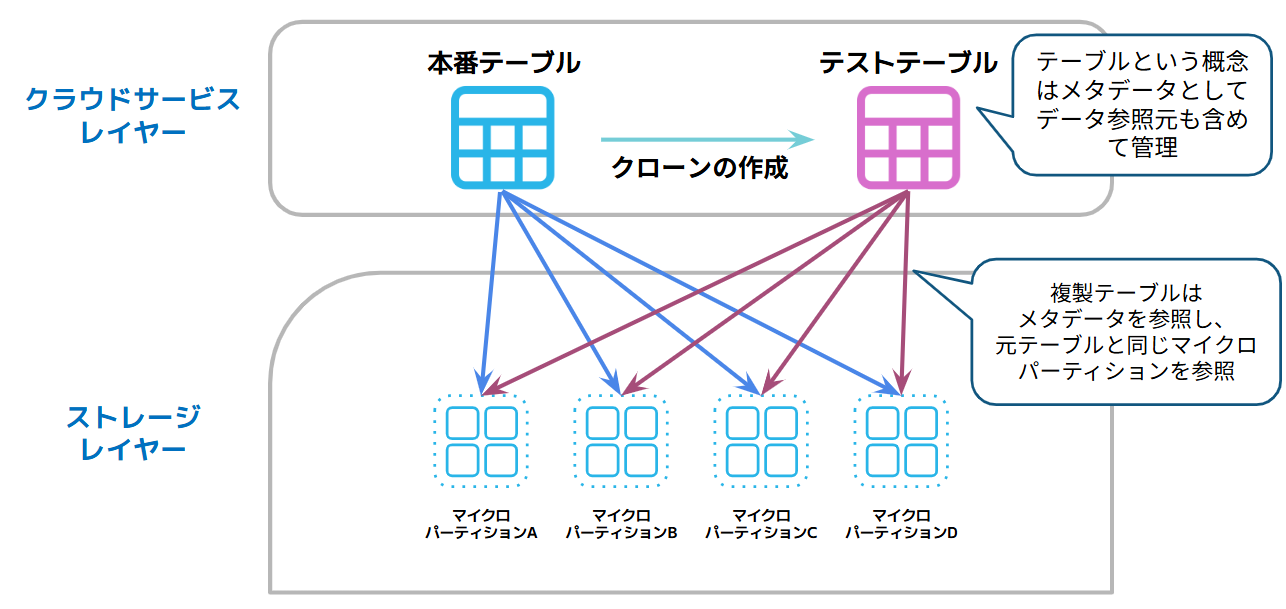
データを複製する際、元データを物理的にコピーしない「ゼロコピークローン(Zero-Copy Cloning)」という仕組みを採用しています。
Snowflakeのクローン機能は、データ活用のスピードとコスト効率を両立する非常に強力な機能です。一般的には、データの複製時には、データ量に応じた時間と追加のストレージ容量が必要となります。
一方でSnowflakeでは、元データを「物理的に複製せず」にクローンを作成できるため、短時間で構築できます。下図をご覧ください。Snowflakeでクローンを作成する場合、クラウドサービスレイヤーに存在するメタデータのみ複製され、そのテーブルの中身である実データは複製されることなく、元テーブルと同様のマイクロパーティションを参照することで、あたかもデータを複製したかのようにふるまいます。
|
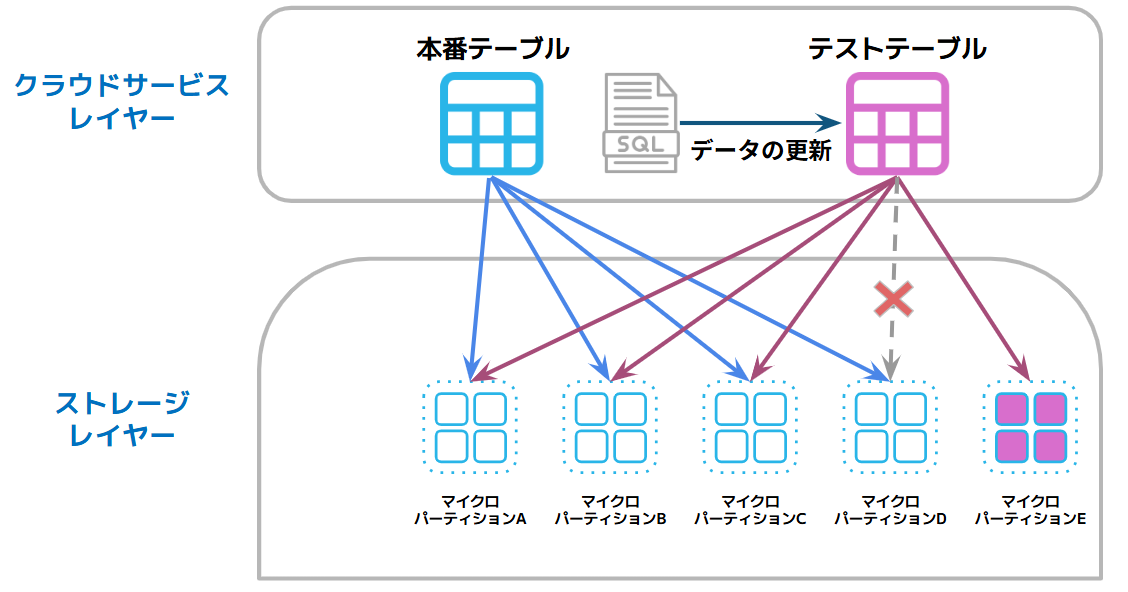
マイクロパーティションはイミュータブル(不変)な性質を持っているため、クローン先でデータの更新や変更があった場合のみ、その差分データが新しいマイクロパーティションとして作成されます。これにより、必要な差分に対してのみ容量が消費されるため、極めて高いコスト効率を実現します。
|
以上の特長により、クローンは以下のような用途で役に立ちます。
このようにSnowflakeのクローンは、マイクロパーティションの仕組みを活用することで、高速性、容量効率、安全性を高いレベルで両立した便利な機能となっています。
検証の際にコストや時間を気にすることなく、「とりあえず複製して試してみる」という使い方を実現できる魅力的な機能です。
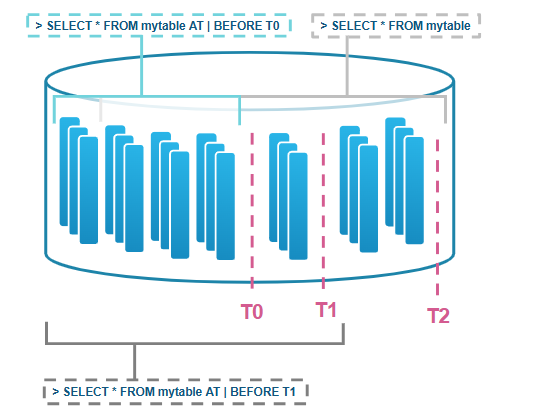
Snowflakeのストレージ機能の中でも、誤操作からデータを守る上で重要なのがタイムトラベル機能です。タイムトラベルは、更新・削除・DROPなどにより、過去の状態から変わってしまったデータに、一定期間さかのぼってアクセスできる機能です。誤ってデータを削除してしまった場合や、変更前の状態を確認したい場合に役立ちます。
下図はSnowflakeのあるテーブルにおけるデータをT0、T1、T2という更新時系列順に並べたものです。Snowflakeのタイムトラベル機能を用いることで、T2の時点にいるユーザーでも、T0やT1といった過去のデータへ即座にアクセスすることができます。
|
Snowflakeではタイムトラベルを使って次のような操作を行えます。
この機能は、Snowflakeが変更前のデータ状態を一定期間保持する仕組みによって支えられています。この保持期間をデータ保持期間と呼び、最大で90日まで保持することが可能です。
例えば、あるテーブルに対して誤ってDELETE文を実行してしまったとします。その際、タイムトラベルを使えば、削除前の状態を参照できます。SnowflakeではATやBEFORE句を使うことで、特定の時点や特定のSQL実行前の状態を参照できます。
SELECT * FROM my_table AT(OFFSET => -60*5);
この例では、5分前時点のmy_tableを参照しています。
また、誤ってDROPしてしまったテーブルについても、保持期間内であればUNDROPコマンドで復元できます。
UNDROP TABLE my_table;
このようにタイムトラベルは、単なるバックアップ機能ではなく、過去の状態を確認する、復元する、その時点の状態をもとにクローンを作るといった柔軟な使い方ができる点が特長です。
特に、開発・運用の現場では、誤削除への備えだけではなく、障害時の調査や検証用途でも大きな価値を発揮します。
このようにSnowflakeのタイムトラベルは、ユーザーに複雑な復旧作業を求めることなく、データの安全性と運用上の安心感を高めてくれる機能です。
Snowflakeの「シンプルさ」は、データ活用をしやすくするだけではなく、万が一のときに素早く復旧できる仕組みにも表れています。
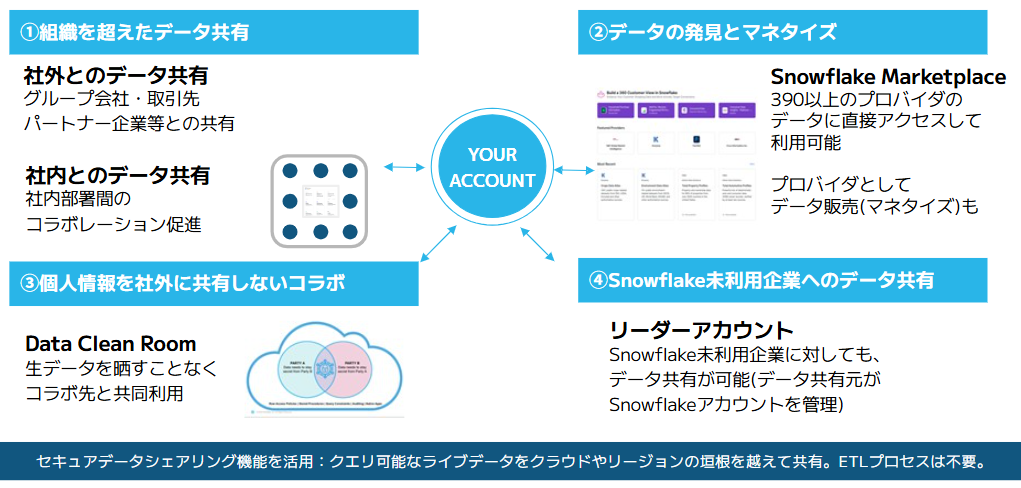
最後に、Snowflakeの特長が色濃く表れているデータ共有機能について紹介します。
Snowflakeでは、データをためるだけではなく、必要な相手に安全かつ素早く共有することで、データをコラボレーションさせ、最大限活用していくことを大切にしており、優れたデータ共有の仕組みやマーケットプレイスといった外部データ活用の仕組みが提供されています。
下図はSnowflakeのデータ共有について4つのポイントでまとめたものです。
|
Snowflakeにおけるその実態は共有先のアカウントに対して、共有元のデータへの閲覧権限を付与することであり、共有先では読み取り専用のデータとして扱います。そのため、データ共有時に追加のストレージコストが発生することもなく、データの移動が無いため共有もスピーディーです。
この閲覧権限の共有に加えて、Snowflakeでは②のSnowflake Marketplace機能によって、外部のデータプロバイダーが公開しているデータセットを自社環境で利用する環境も提供しています。実際に自社のデータと天気データ、地理データ、人の流動のデータなど、さまざまなデータをコラボレーションさせ、さらに深い洞察を得ている企業もたくさん存在しています。
さらにSnowflakeでは③のData Clean Roomによって、機密情報を漏らすことなく他社とデータ共有が可能な環境を提供していたり、④のリーダーアカウント機能により、Snowflake未利用企業にもデータ共有が可能な機能を提供するなど、多種多様な機能でユーザーのデータ共有を促進してくれます。
ここまで話したように、Snowflakeではデータ共有を前提としない、閲覧権限の共有によって、データのサイロ化をスピーディーかつ安価に防ぐことが可能です。
ここまでの解説を読んで、実際に触りたくなった方も多いのではないでしょうか。Snowflakeでは、30日間の無料トライアルを提供しています。
そんな皆さんはぜひ、以下のURLから30日間のSnowflakeトライアルに申し込んでみてください。

|
|---|
今回は、本トライアル環境と私のナビゲートを通して、皆さんに3つの素早さ / 簡単さを体験していただこうと思います。
体験してもらうのは
1)「環境構築」の素早さ / 簡単さ
2)「オブジェクト作成」の素早さ / 簡単さ
3)「スケールアップ」の素早さ / 簡単さ
の3つです。
トライアル申し込みを進めていただくとわかりますが、おおよそ3分ほどでSnowflake環境を申し込むことができます。
申し込み後、メールが届きますのでアカウントをアクティベートして、Snowflakeの世界にアクセスしてみましょう。
みなさんが最初にアクセスするのがSnowflakeが提供するユーザーインターフェースである「Snowsight」です。
|
Snowsightでは、GUI形式で操作を進めることができ、GUI形式でデータベースやウェアハウスといったオブジェクトを作ることができます。
次にデータベースと仮想ウェアハウスを作ってみましょう。
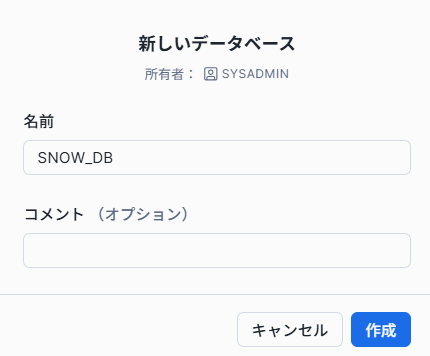
【データベースの作り方】
以上の3ステップにより、数秒でデータベースが作成できます。
|
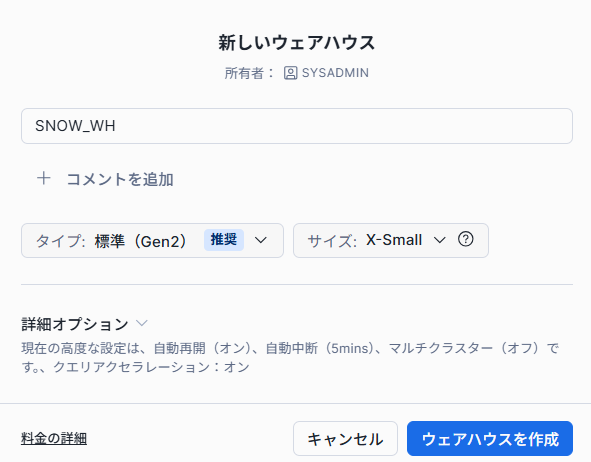
【仮想ウェアハウスの作り方】
以上の3ステップにより、データベース同様数秒でウェアハウスが作成できます。
|
最後に、GUI上でSNOW_WHの性能をX-SmallからMediumにスケールアップしてみましょう。
【スケールアップの手順】
|
すると、ウェアハウスSNOW_WH更新済みとポップアップが登場し、下にスクロールして詳細を確認するとサイズがMediumに変更されている様子を確認できると思います。
|
ほかにもたくさんGUIでSnowflakeの機能を試してみることができます!
ぜひ、Snowflakeの素早さと簡単さをトライアルを通して、体験してみてください!
本稿では、Snowflakeのすごさを製品思想の観点、コンピュートリソースの観点、ストレージの観点から紐解いてみました。
Snowflakeは単なるデータを保管するための器ではなく、データを「ためる」、「効率的に処理する」、「守る」、「複製する」、「共有する」というデータ活用における重要事項を、シンプルかつ柔軟に実現できる製品だと言えます。
Snowflakeは日々進化を遂げています。
本稿を通して、皆さんにSnowflakeの魅力が伝わり、データ活用中心に位置するハブとなりうることが伝われば幸いです。
弊社ではお客様の要件や目指したいゴールに合わせて、Snowflakeの最適な活用方法を支援し、伴走いたします。Snowflakeの導入をお考えのお客様は、ぜひ弊社までお気軽にご相談ください。
今回の記事でお伝えしきれなかったSnowflakeの魅力的な機能に関しては、今後どんどん発信していく予定ですので、お楽しみに!

|
|---|
2025年に新卒入社。 Snowflakeの技術部門に配属後、 プリセールス、ポストセールスを担当し、Snowflakeを中心としたデータ活用基盤の提案・構築支援を行う 。自身がIT未経験だからこそ、...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

2026年7月24日開催のセミナー「AI活用の前に整えるべきデータ活用基盤とは」では、SoR(守り)とSoI(攻め)を分離し、既存の基幹系を生かしてAI Readyな基盤を構築する方法を解説。OracleとSnowflakeの役割分担や製品選定のヒントを知りたいデータベース技術者・アーキテクト必見です。

【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。

データ活用は「予測」から「アクション」へ。Snowflake×アシストが共催したセミナーの模様をレポートします。AIにビジネスを正しく理解させる鍵となる「セマンティックモデル」の重要性や、Snowflakeを用いた実装戦略など、当日語られた核心部分を凝縮して解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

