

現在、国内では生成AIやRAGを活用する様々なツールやサービスが登場しています。
すでに一部部署でツールを導入したりPoCを実施している企業も多くいらっしゃる印象ですが、期待した検索結果が得られなかったり回答精度が低かったり、満足行く結果に至らないケースが多いようです。
この記事では、RAGや生成AIツールを検証したが上手く行かなかった方や、今後の検証に向けて情報収集したい方にむけて、Glean をはじめ、AWS や Snowflake など様々なツールを取り扱うパッケージベンダーの視点から、RAG検討時のポイントや棲み分けについてアシストのAI技術者が解説します。
この記事の記載内容は以下のとおりです。
RAGを検討する前に整理しておくべきポイント
用途に応じたRAGの選定方法
RAGの運用面
みなさんの「生成AI活用」に少しでもお役立ちできれば幸いです。
RAGを検討する前に整理しておくべきポイント
RAGを検討する前に整理しておくべきポイントはたくさんありますが、今回は以下の4点に関して詳しく述べていきます。
生成AIを活用した方向性は何か?
解決したい問題・課題は何か?
RAGを利用するユーザーの範囲は?
検索対象のデータの特性は?
1.生成AIを活用した方向性は何か?
弊社では以下のような図で生成AIの方向性を整理しています。
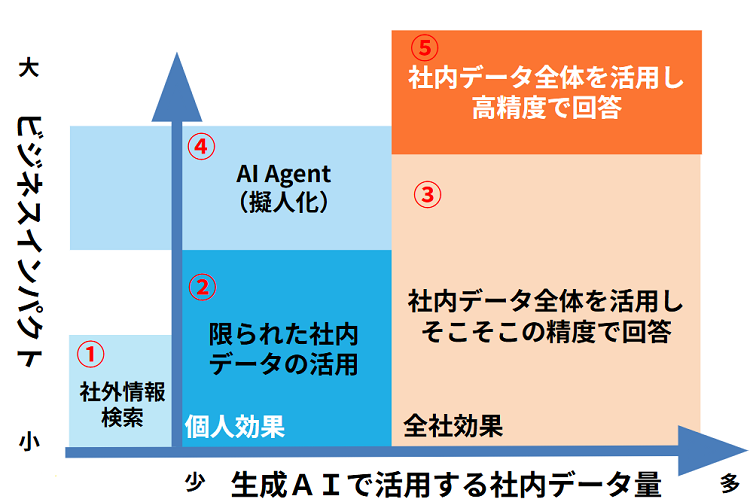
まず、左側の領域(①、②、④)は、社員個人がAIを利用することで効果を積み上げ、会社全体の価値につながっていくものです。
限られたデータを使ってビジネスプロセスの生産性を上げたり、省人化するために、予測AI、生成AI、ルールベースAIなどを組み合わせた複合型AI Agents(エージェント)やPhysical AIなどが該当します。
一方、右側の領域(③、⑤)は会社全体への効果をイメージしています。
こちらは、社内に散らばっているナレッジを有効活用していくことで業務効率化やプロセス改善・生産性向上の付加価値につなげていきます。弊社ではこのアプローチを「Internet of Knowledge」と呼んでいます。
方向性として、
■ 複合型AI AgentsやPhysical AIなどを目指して個人効果を上げていくのか
■ Internet of Knowledgeのようなアプローチを目指していくのか
を最初に決定することが必要です。
この選択は、プロジェクトの目標、利用可能なリソース、そして期待される成果に大きく影響します。今回の記事では②⇒④のような複合型AI AgentsやPhysical AIの方向性を対象とせず、②⇒③のアプローチを対象として解説していきます。
2.解決したい問題・課題は何か?
RAGの導入には相応のコストと労力が必要となるため、方向性が決まり次第、解決したい具体的な問題や課題を明確にすることが重要です。
例えば、既存の検索システムでは対応できない複雑な質問への回答が必要なのか、社内ドキュメントの効率的な活用が課題なのかなど、目的を具体化することで適切な実装方針を定めることができます。問題と課題に対しては、以下の定義に従い整理していくとより具体的になってきます。
問題: 現状と理想の間にあるギャップ
課題: ギャップを埋めるための具体的な対策
RAG の開発者側だけで決めるのではなく、利用するユーザーも巻き込んで決めていくことも重要です。ただし、あまりに人数が多すぎるとうまくまとまらないため、検討者は人数を絞ることも非常に重要な観点です。
また、「課題に対して最適な手段は必ずしもRAGではない」ということも多々あります。
例えば、既存の検索システムで必要な情報を見つけるのに時間がかかりすぎている、もしくは精度が悪いという課題があったとします。そうした際には、RAGではなくて、単純に既存のものよりも精度が良い検索システムの方が適しているかもしれません。手段ベースで課題を考えないようにすることも重要な観点です。
3.RAGを利用するユーザーの範囲は?
RAGを利用するユーザーの範囲は、事前に決めておきましょう。
これは後述する生成AIの棲み分けにも関連しますが、対象とするユーザーの範囲によって使用するRAGを含めた生成AIの技術の使い分けが必要であったり、データ量が増加したり、運用負担が大きくなるケースがあります。また同音異義語への対応が必要になるなど、様々な技術課題が生じます。
こういった観点から、先ほど定義した課題と合わせてユーザーの対象範囲を事前に検討していくことが非常に重要です。
4.検索対象のデータの特性は?
検索対象のデータの特性を事前に整理することは、作成もしくは導入するRAGの方向性を決める上で非常に役に立ちます。以下に、データの特性を整理する際に考慮すべきポイントを詳しく説明します。
データの保存場所
データがオンプレミスにあるのか、クラウドにあるのかを確認しましょう。またそれぞれの保存場所に対して、以下のような注意が必要です。
オンプレミス: セキュリティやアクセス権限の管理がどのようになっているか。データの取り扱いやクローリングに対する制約の有無。
クラウド: 複数のクラウドサービスにまたがっていないか。ツールを検討する際は、対象のクラウドシステムへのコネクタ有無だけではなく、どういった情報を取得するのか、大規模クローリングの実績有無の確認も検討に入れた方がよいかもしれません。
データの構造
データは、構造化データか非構造化データのどちらでしょう?
対象データの量が多くなればなるほど、構造化データと非構造化データの両方が存在することが一般的です。そのため、構造化データと非構造化データの割合や、それぞれがどのようなシステム構成になっているかを整理しておくことが重要です。これにより、その後の手段として、同じRAGシステムに問い合わせる必要があるか、Agentic RAGのような最先端のRAGを使用する必要があるかなどの検討がしやすくなります。
構造化データ: データベースやスプレッドシートのように、明確なスキーマやフォーマットがあるデータ
非構造化データ: テキストファイル、PDF、画像、音声など、明確なスキーマがないデータ。スライドや画像貼り付けなどで行・列に格納されていないExcelファイルなども該当します。
データの権限に関して
データの保存場所と重なりますが、保存されているデータが適切な権限管理が設定されているかはしっかりと確認しておきましょう。どれだけRAGのアプリ側でしっかりと権限が設計されていても、データ元の権限が誤っていれば、そちらを引き継いでしまいます。RAGの検討前やトラブルシューティング時は、データ元の権限もしっかり確認すると良いです。
用途に応じたRAGの選定方法
本節では、生成AI全体の活用から見たRAGの領域、またその領域ごとの必要なRAGの技術に関して、詳しく述べていきます。
生成AI全体活用から見たRAGの領域
再掲にはなりますが、先程の図を使って説明していきます。
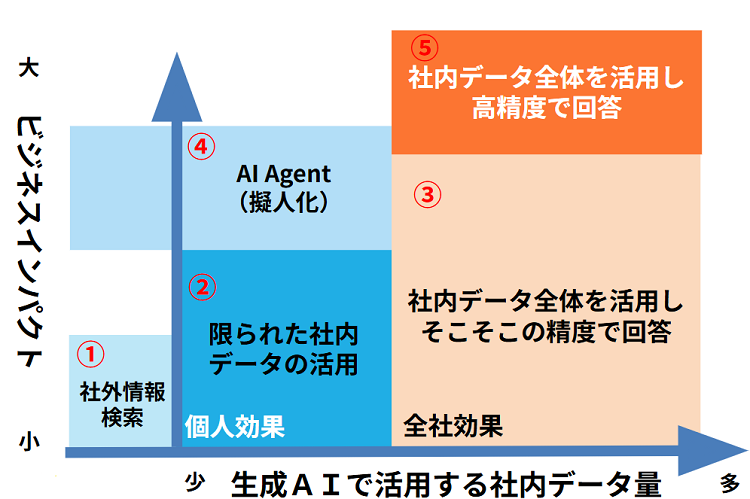
この中でRAGが活躍する場面は主に②と③です。
ただし、②で本当にROIを出しているRAGは非常に少ないと考えています。2023年から2024年前半にかけてRAGブームが起こり、大量のRAGが開発されましたが、その中でPoCを乗り越え、現在でも業務に組み込まれているRAGは(私の肌感覚では)1割にも達していないと思います。社内データを活用するために必要なRAGの技術について、このあと詳しく述べていきます。
④に関しては、一部のAgentic RAGのようなものを活用していくことになると思いますが、こちらは本記事では対象外とさせていただきます。⑤に関しては現状存在しないと考えています。理由としては、AI技術の問題よりも、人間側のデータの整備の方が要因として大きいです。あらゆる人が検索対象のデータを操作する以上、完全に統制が取れた綺麗なファイル・フォルダ構成を実現するのは難しく、まだまだ時間が必要だと考えています。
必要なRAGの技術
まず、②で使われるRAGの技術に関して説明していきます。
最もメジャーなものとしては、RAGブーム初期に頻繁に見られたベクターRAGです。こちらは文章をEmbeddingモデルに通してベクター化し、ベクターデータベースなどに格納し、プロンプトと格納されているベクターデータベースの距離で検索します。ただし、精度がEmbeddingモデルに依存しているため、Embeddingモデルの学習時に知らない知識に対して精度が出なかったり、似たような文章をうまく区別できないなどの問題があり、あまり有効な手段とはなりませんでした。
その後、キーワード検索とベクター検索によるハイブリッド検索や、文章をGraph化させることで関係性を捉えやすくしたGraph RAGなども登場しています。ただし、この段階のRAGでは③にはうまく適応できません。その理由は、大規模なデータ量とユーザに対応していないからです。
冒頭で説明したユーザの範囲を決めることがここに関わってきます。
社内用語を辞書として登録しているRAGもありますが、手間がかかる上に、企業の環境ではユーザごとに社内用語が変わってくる問題があります。
例えば、弊社の用語を例にすると、「DR」という単語は、AIに近い人にはDataRobot、データベースに近い人にはディザスタリカバリ(Disaster Recovery)、営業に近い人には案件登録(Deal Registration)を意味します。このように社内用語が人にも関連してくるため、先程のRAG技術だけではうまく検索できない問題が発生します。
そのため、③のRAGに関しては、先程の技術に加えて多数のシグナルで検索精度を向上させる必要があります。
弊社で③として使用している生成AIツールGleanを例にすると、人物関係の距離感や時系列を考慮したトレンド、検索エンジンのクリックによるフィードバックなど、60以上のシグナルによって計算されます。③の中でもさらに上位に進むためには、LLMに通すのではなく、agentを間に入れたAgentic RAGが必要となってくるかもしれません。
(参考文献 : https://www.glean.com/blog/agentic-reasoning-modern-work)
RAGの運用面
最後にRAGの運用面に関する解説です。運用面で検討すべき要素とBoxやMicrosoft SharePointなどの既存ツールとの接続コネクタなどに関して詳しく述べていきます。
運用面で検討すべき要素
運用面で検討すべき要素は企業によって異なると思いますが、最低限以下の要素は検討するべきです。
速度
権限設定
データ収集(クローリングなど)
再学習のパイプライン化
速度
精度を追及すると、推論の計算量が増え、応答速度とのトレードオフが生じがちです。ユーザーが許容できる応答時間の上限を事前に定義し、その範囲内で最適なモデル構成やインデックス検索手法を選定することが重要です。
権限設定
企業内には、外部や他部署に見せられない機密情報が必ず存在します。特に先程の棲み分けの③のRAGを目指す場合は、しっかり権限に沿った参照先をもとに回答をしているかが重要です。また、RAG以外でも参照先のクラウドストレージサービスなどで権限管理がしっかりとできていることも同じく重要となります。
データ収集(クローリングなど)
RAGの回答精度を高めるうえで、最新かつ正確なドキュメントやデータを取り込むことは極めて重要です。運用中に参照元データが増加・更新されるケースを想定し、効率的なデータ収集とインデックス更新を行う仕組みを整備する必要があります。
また、メタデータ情報はRAGにおいては重要なデータの一つであるため、クラウドストレージからどのようなデータが収集できるか、また運用時の収集状況などもあらかじめ確認しておく必要があります。
再学習のパイプライン化
RAG運用においては、参照先だけでなくモデル自体を継続的にアップデートし、精度を維持・向上させることも考慮すべきです。特に③のような社内データ全体に対してのチャット環境では、情報が絶え間なく更新されるため、再学習のパイプラインを整備しておき、運用負荷を軽減することが重要です。
既存ツールとの接続コネクタに関して
こちらはRAGツールを検討するうえで非常に重要な観点です。
コネクタも作り込み方法が異なるため、自社の既存ツールが対象かだけではなく、コネクタを使うことによってどのような差分クロールが可能か、メタデータ情報を取得できるか、RAGと既存ツールの権限は何を基準に設定できるかなどを検討しておくことが重要です。弊社で取り扱っている様々なRAGでもこのコネクタの設計は大きく異なるため、こちらの調査も非常に重要な観点となります。
最後に
RAGに関して様々な視点から解説してみました。様々なツールを取り扱っているパッケージベンダーから見ると、一見同じように見えるツールでも技術的要素が大きく異なっており、それぞれが提供できる付加価値も異なることが分かってきます。RAGや生成AIツールを検証したが上手く行かなかった方や、今後の検証に向けて情報収集したい方にとって、今回の記事が少しでもお役に立てれば幸いです。Gleanを主とした生成AIツールやお悩みがありましたら、ぜひお気軽にご相談ください!
執筆者情報

山本 耕也
株式会社アシスト
2022年に中途入社。新卒で自動車部品メーカーに就職し、製造現場でのAI活用を推進するべく、経産省の課題解決型AI人材育成プログラム『AI Quest』を受講。その後データサイエンティストを志し、アシストに転職。現在も貪欲にAI関連の技術や知識習得に邁進。アシストのトップAI技術者としてイベントでの講演や顧客支援を担う。