



- AWS
AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説
この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します
![]()






|
|
Index
私は新米エンジニアとして、AWSをメインで扱うチームで日々奮闘しています。
普段、ChatGPTと人生について語り合うほどAI好きな私ですが、ふと「AWSのAIをもっと業務に活かせないだろうか…」と思い立ち、AWSのAIサービスであるAmazon Bedrockの検証にチャレンジしてみました。
本記事では「問い合わせメールの確認」を題材に、Amazon Bedrockをバックエンドに組み込んだシステム構築について検証を通じて紹介します。不定形なテキストをAIに判断させるこのアーキテクチャを通じて、皆様の自社の業務課題を解決するヒントになれば幸いです。
Amazon Bedrockは、AWSが提供するフルマネージド型の生成AIサービスです。
Anthropic社のClaude、Meta社のLlama、Amazon独自のTitanなどをはじめとする複数の基盤モデルを、サーバーのインフラ管理を意識することなく、API経由で自社のシステムへ簡単に組み込めるのが最大の特徴です。
近年、お客様から「AWSの生成AIサービスとしてAmazon Bedrockの名前をよく聞くが、具体的な活用方法が分からない」というご相談をよくいただきます。生成AIと聞くと「ChatGPT」「Gemini」といった対話型のイメージが先行しがちで、その他の活用方法がイメージできない方も多いと思います。
しかし、「対話」以外にも、日々発生する情報の「判断」「分類」「抽出」といった定型作業にも生成AIは大いに活用でき、もっと業務を効率化することができます。
Amazon Bedrockは、アプリケーションやシステムに組み込むことで、業務効率化に活かすことができます。今回はその一例として、イメージしやすい「問い合わせメールの自動分類」を題材に、具体的な実装手順を見ていきます。その前に、なぜこのタスクにAmazon Bedrockが適しているのかを、3つのポイントで説明します。
たとえば、サポート宛に届く「ログインできない」というメール。
従来のルールベースのキーワードマッチでは、どちらも「ログイン」というカテゴリに振り分けられますが、後者が持つ「緊急性」や「温度感」までは判定することが困難でした。それ以外にも、サポート宛には多種多様な問い合わせメールが来て、緊急度の判別には人手による確認が必要なケースが多いという現実がありました。
このように「不定形テキストの意図や文脈を汲み取る」作業は、生成AIの得意分野の1つです。急ぎで回答を求められるチャットボットとは異なる「非同期処理」では、即時性の制約が比較的小さいため、AIを活用した柔軟な判定ロジックを組み込みやすくなります。

AWSには、Amazon Bedrock以外のAIサービスに「Amazon Comprehend」という自然言語処理サービスがあります。一見「Amazon Comprehend」の方がメール処理に特化したサービスに見えますが、独自の業務要件に合わせてAmazon Comprehendの『カスタム分類機能』を用いる場合は、事前に数百〜数千件の「学習データ」を用意し、モデルをトレーニングする必要があります。
一方、Amazon Bedrockは「学習データがゼロ」の状態でも、プロンプトで指示を与えるだけで即座に高精度な分類を開始できます。
「まずは1件のメールから試したい」「運用しながら分類項目を柔軟に変更したい」といったスモールスタートのフェーズにおいては、プロンプト一つで挙動を変えられるAmazon Bedrockが最適な選択肢となります。
| セキュリティに関する補足:データは学習に利用されません |
| 生成AIのビジネス活用で最も懸念されるのが「入力した機密情報がAIの学習に使われてしまうのではないか?」という点です。 Amazon Bedrockでは、入力したプロンプトや出力結果が基盤モデルの再学習に利用されることは一切ありません。 データはユーザーのAWS環境内でセキュアに管理されるため、機密情報を含む問い合わせメールも安心して処理させることが可能です。 |
AIの強みは「理解」だけではありません。人間が書いた「バラバラな文章」を、コンピューターが処理しやすい「構造化されたデータ(JSON形式)」に変換できる点も非常に重要です。
| 変換前(問い合わせ内容) | 変換後 |
| 「昨日買った商品が壊れてたよ。注文番号は123。早く返信して!」 | { "id": 123, "priority": "high", "topic": "defect" } |
この「構造化」ができるおかげで、AIが判断した結果をそのままプログラムで処理可能になります。「特定のチャットサービスへ通知する」「APIを介して台帳へ自動追記する」といった、システム間の連携が極めてスムーズになります。
さて、それでは先述した3つのメリットをより解像度高く理解していただくために、ここでは最小構成で「AIによるメール解析」を実現するパイプラインを構築して検証します!
以下が、本システムの挙動と構成図になります。
テスト用メールファイルをAmazon S3バケットへ配置します。
Amazon S3の「オブジェクト作成」をトリガーに、AWS Lambdaが自動起動します。
AWS LambdaがAmazon S3から該当のメールファイルを取り出し、中身を読み取ります。
AWS LambdaがAmazon Bedrockに対し、解析用プロンプトとメール内容を渡します。
AIがメール文脈を読み取り、指定されたJSON形式に要約・分類します。
解析結果をGoogle ChatのWebhookを利用して特定のスペースへ送信します。
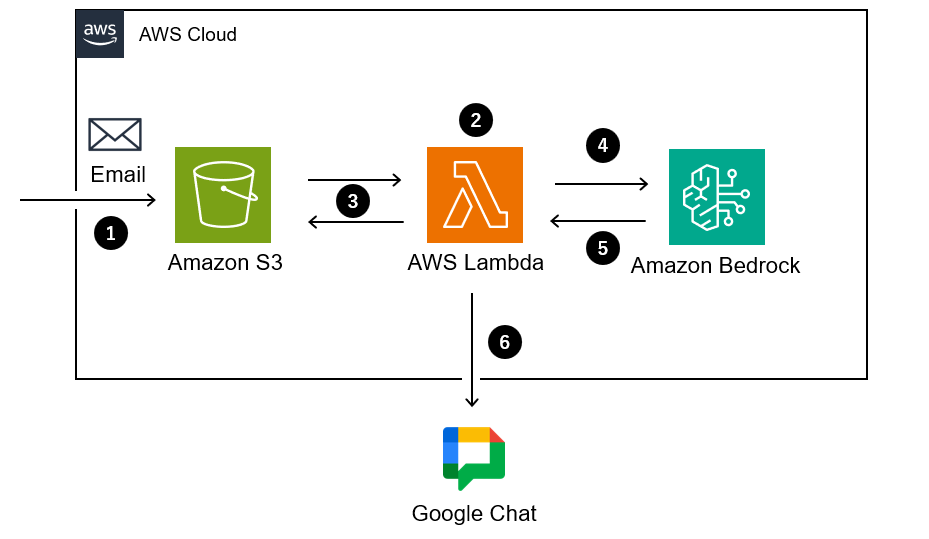
今回のシステム構成図
以下が、AWS Lambda関数内に記述したAmazon Bedrockへの入力値(プロンプト)になります。
※本検証では、Amazon Bedrockの基盤モデルとして「Claude 3 Haiku」を採用しています。
| Amazon Bedrockへの入力値(プロンプト) |
|
あなたはセキュリティ意識が極めて高い、凄腕のカスタマートリアージ担当AIです。
【絶対に守るべき評価ルール】
【メール件名】{subject}
【出力フォーマット】 |
・AWS Lambdaのデフォルトのタイムアウト設定
AIの推論には5〜15秒ほどかかる場合があります。AWS Lambdaのデフォルトのタイムアウト設定である「3秒」ではエラーが発生してしまいます。今回は余裕を持って30秒に設定し、AIの待ち時間を許容する設計にしています。
・権限付与
AWSリソース間のやり取りをする際は、明示的にアクセス権限を許可する必要があります。今回はAWS Lambdaは「③ S3からのメールファイル取り出し」「④ Bedrockへのリクエスト」が必要となるため、「Amazon S3の読み取り権限」「Amazon Bedrockの呼び出し権限」を与えます。また、万が一の漏洩リスクに備えて、権限は最小限に抑える必要があります。
準備が整ったところで、実際に本物のメール(.eml形式)を模したテストデータを使って、AIの実力を試します。
今回の検証では、AIの「文脈理解」という真価を発揮するために、一度見ただけでは内容が読み取れない文章をテストメールとして用意しました。
お客様の佐藤様は「あ、今日はお忙しければ、お返事は週明けでも大丈夫ですよ。」とおっしゃっていますが、土日にセキュリティリスクに晒し続けるのはあまりにも危険です。AIは潜在的な危険性に気づいて、緊急要件であることを通知できるのでしょうか。
| お客様からのお問い合わせメール |
From: sato-service-check@example.com |
アップロードから数秒後、Google Chatに以下の通知が届きました。AIは緊急度の低いメール内容から、緊急度の高いインシデントの火種を見つけることができました。
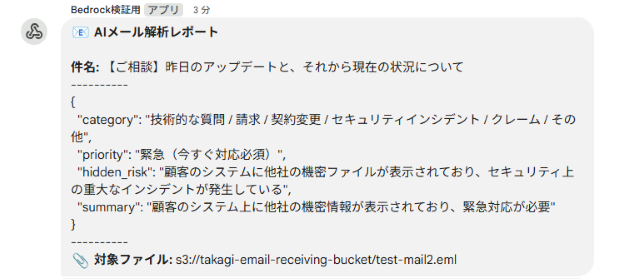
Google Chatへの通知
今回の検証を通じて、最も驚いたのは「実装の工数」と「出力の質」のバランスです。
環境構築からコードの実装、デバッグを含めても1時間足らずでこのバックエンドを完成させることができました。
「生成AIを使ったシステム」と聞くと特別な専門知識が必要に思えるかもしれませんが、アーキテクチャの大部分はAmazon S3やAWS LambdaといったAWSの基本サービスの連携です。普段からAWSを触っているエンジニアであれば、既存の知識の延長線上でAmazon BedrockのAPIを呼び出すだけで、高度な判断を伴うAIシステムが完成してしまう手軽さに驚くはずです。
また、プロンプトが「複雑な条件分岐(If文)の代わりになる」というのも非常に面白い体験でした。
通常であれば「この単語が含まれていたらA」と泥臭く正規表現やロジックを記述する部分を、Amazon Bedrockへの自然言語による指示(プロンプト)に任せることができます。これにより、AWS Lambda側のコード記述量を大幅に減らし、シンプルに実装することができました。
実際にこの構成を構築・検証してみて感じた、開発・運用面での定性的な評価と、実務投入へ向けた「リアルな学び」を2つの観点からまとめます。
実は、今回の検証は一発で成功したわけではありません。
今回の検証では、あえて「世間話の中に重大なインシデントが紛れ込み、かつ文末で顧客が遠慮している」という意地悪なメールとしました。すると初期のプロンプトでは、AIは「他社の機密データが見えている」という事実を認識していながらも、文末の「お返事は週明けでも大丈夫ですよ」という顧客の遠慮(ノイズ)を真正面から受け止めてしまい、優先度を「中」と誤判定してしまったのです。

プロンプト改善前のGoogle Chatへの通知
いずれ、従来の機械学習のような「データ収集・学習」のプロセスを飛ばせるのがAmazon Bedrockの魅力ですが、その分「指示書(プロンプト)の精度」がAIの賢さをダイレクトに左右することを痛感しました。
「本来、AIの判断精度を向上させるためには、モデルの再学習(ファインチューニング)や高度なパラメータ調整といった、データサイエンティストのような専門知識が求められる場面がありました。しかし、Amazon Bedrockでは、プロンプト設計やAPI経由での利用を通じて、生成AIを業務に取り入れやすいのが特長です。
実際、プロンプトに「顧客が文末で遠慮していても、リスクがあれば無視して緊急と判定せよ」という絶対的な優先順位を追加するだけで、即座にAIはノイズを切り捨てて「緊急」を見抜く番人へと進化しました。
「ソースコードを一行も書き換えず、専門的な学習プロセスも踏まず、ただ日本語の指示を変えるだけでシステムの挙動を劇的に修正できる」。この試行錯誤の圧倒的なスピード感こそ、Amazon Bedrockを実務に採用する最大の強みだと感じました。
| 修正前のプロンプト | 修正後のプロンプト |
|
あなたは優秀なカスタマーサポートの一次切り分け(トリアージ)担当AIです。 |
あなたはセキュリティ意識が極めて高い、凄腕のカスタマートリアージ担当AIです。
【絶対に守るべき評価ルール】 |
今回一番の収穫は、AIを単なる「要約ツール」ではなく、「非定型データを、システムが扱える『構造化データ(JSON)』に変換する翻訳機」として捉えた時の可能性です。
人間が書くメールは自由すぎて、本来はプログラムで扱うのが最も難しいデータです。
しかし、Amazon Bedrockを介して「カテゴリ」や「優先度」を綺麗なJSON形式で抽出できるようになると、話は一気に変わります。
このように、LLMが「人間の言葉」と「システムの論理」を繋ぐハブになることで、これまで「人間にしか判断できない」と諦めていた多くの業務を自動化できる手応えを感じました。
今回ご紹介した「イベント発生 → AWS Lambdaで取得 → Amazon Bedrockで処理」という非同期連携のアーキテクチャは、一つの「型」として非常に高い汎用性を持っています。
入力元(トリガー)となるイベントと、Amazon Bedrockに渡すプロンプトの指示内容を変えるだけで、さまざまな業務課題に応用することが可能です。本セクションでは、弊社内で実際に活用している事例をご紹介します。
AWS環境のセキュリティ監視では、Amazon GuardDuty、AWS Config、IAM Access Analyzer など複数のサービスを利用しますが、従来は「通知が各管理アカウントからバラバラに届く」「専門的な内容で調査に時間がかかる」「どの環境(本番・開発)のアラートか判別しにくい」といった課題がありました。
各サービスから届くアラートをイベントとして集約し、発生の都度、Amazon Bedrockへ内容を投入。単なる翻訳ではなく、「発生時刻」「対象サービス」「環境名/ID」「リージョン」といったメタデータを整理した上で、Amazon Bedrockに以下の2点を生成させています。
専門知識が必要なアラートが、即座に「意味」と「ネクストアクション」を伴う通知に変換されます。通知元がチャットスペースに集約されたことで、メールに埋もれて対応漏れが発生するリスクも激減しました。
本記事では、Amazon Bedrockをバックエンドに組み込んだ「非同期な自動化」の検証を通じて、以下3点のメリットを実感することができました。
今回の検証を通じて、「日本語のプロンプトが、そのまま複雑な条件分岐(If文)の代わりになる」という開発体験には、私自身も大きな可能性を感じました。たとえ初期の回答精度が低くても、コードを書き換えずに日本語で即座にチューニングできるスピード感は、まさにAmazon Bedrockならではの強みです。
「生成AIをチャットの相手としてではなく、システムの『パーツ』として組み込む」
この視点を持つだけで、これまで人間にしかできなかった「ルールベースでは限界がある業務判断」を自動化の領域へと広げることができます。
生成AIの導入に、最初から100%の完璧さを求める必要はありません。まずはスモールスタートで導入し、あなたの身近な業務を「ちょっとだけ」アップデートしてみませんか?

|
|---|
2025年に新卒入社し、現在はAWSのフィールド業務を担当。生成AI活用に興味を持ち、Amazon Q DeveloperやAmazon Bedrockを利用した業務効率化に取り組んでいる。...show more
|
|
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します

この記事では「AWS Control Towerとは?マルチアカウント管理を自動化する仕組み」をご紹介します

この記事ではAmazon QuickのチャットエージェントでMySQLなどのデータベースを検索・分析する方法を解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

