


- AWS
AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説
この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します
![]()






|
|
Index
Amazon Quickのチャットエージェントを利用すると、様々な社内外のデータを自然言語で検索・分析することができます。よくあるニーズとしては「社内のデータベースを自然言語で検索したい」といったものではないでしょうか?
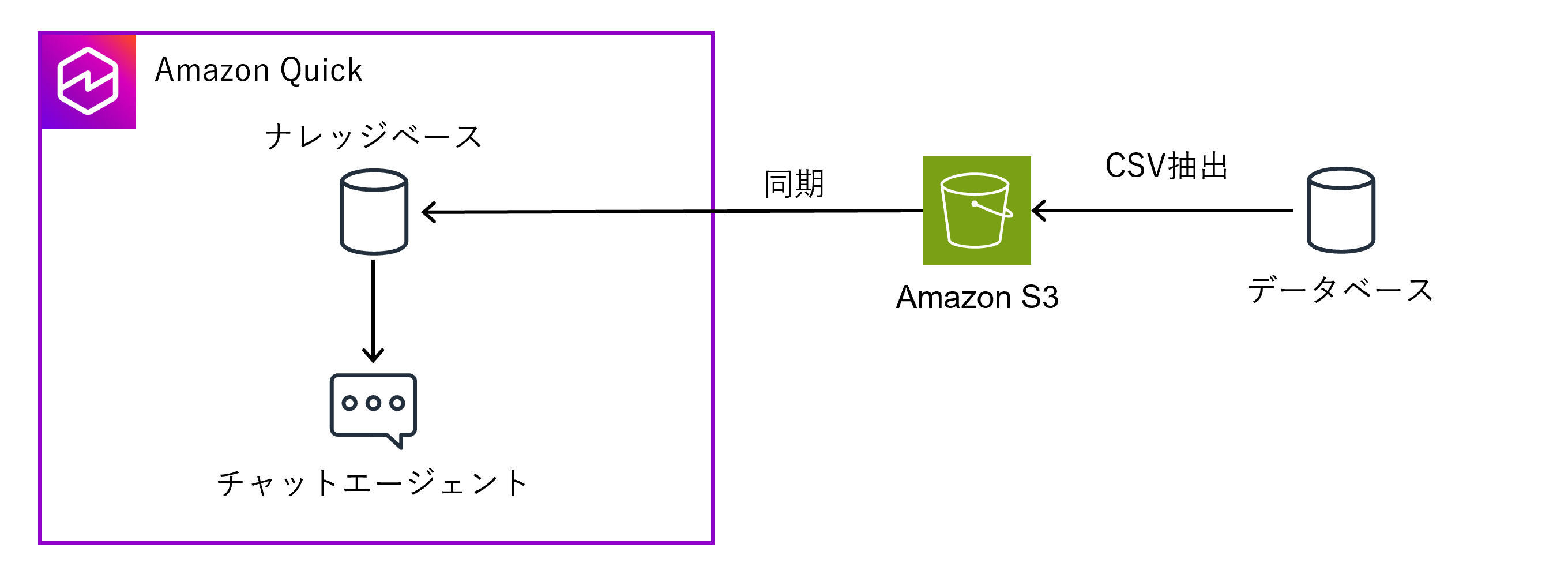
PoCでこれらを試したい場合「データベースのデータから一部をCSVで出力してS3バケットに配置し、それをAmazon Quickの検索対象(ナレッジベース)にする」という方法を取るパターンが多いかと思います。
|
|
PoCフェーズではこの方法は気軽に試せるのですが、実際の利用を考えるとCSVへの変換やS3への配置などの処理を自動化する仕組みを作ったりする必要があり、運用管理が煩雑になる可能性があります。
また、DBのテーブルのカラム名もAIが理解しやすいような都合の良い列名になっていない場合も多いと思います。さらにAIの精度のことを考えると「この列はこういう内容のデータが入っているんだよ」等のコンテキスト情報も付与したくなります。
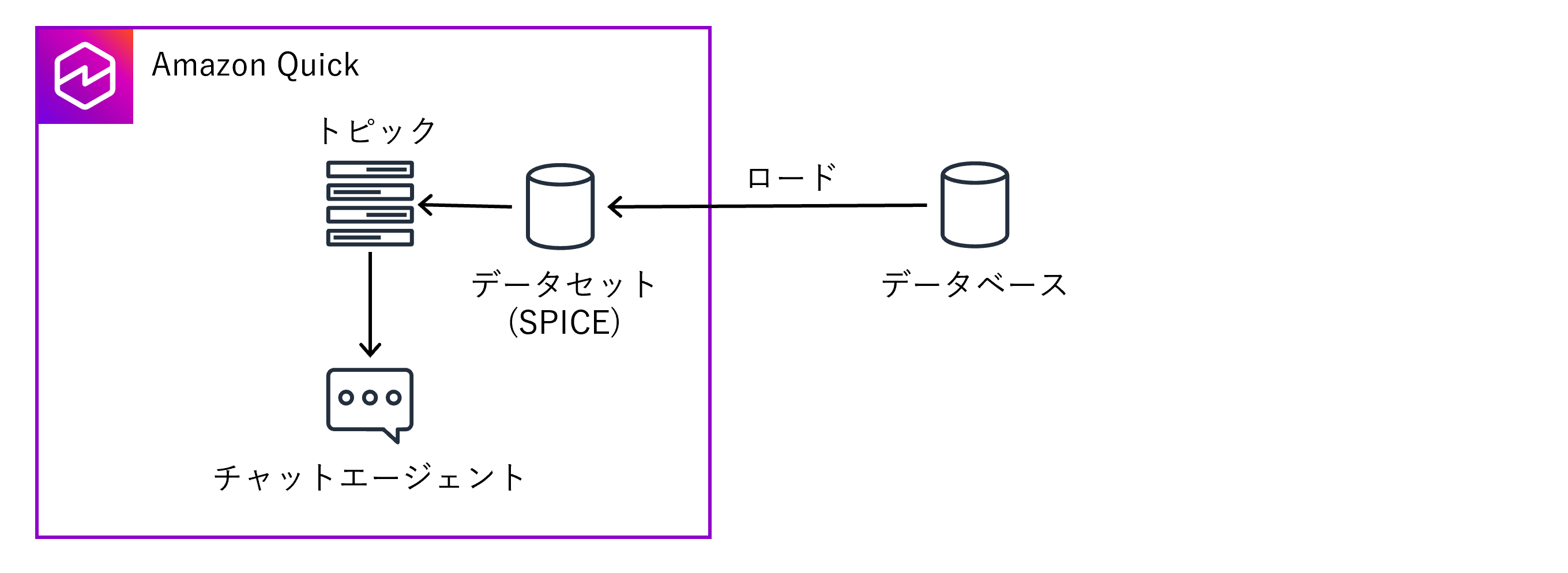
このような課題はAmazon Quick(Quick Sight)の「データセット」及び「トピック」機能を利用することで解決することができます。これらの機能を利用することで、データベースからテーブルデータを自動的に取得してQuickに保存、かつデータにコンテキスト情報を付与するといったチューニングまで実施することができます。
|
|
本ブログでは上記のような実践的な仕組みを構築する方法をご紹介します。
※本ブログでは手順を省略しますが、Amazon QuickのVPC接続設定がされている前提となります。
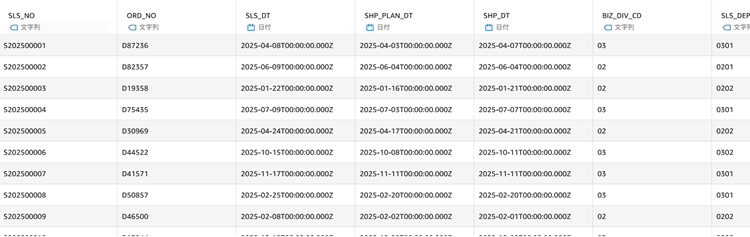
まず、トランザクションテーブルとしてT_SLS_DTLテーブルを用意しました。
|
|
カラム名を見ていただくと「BIZ_DIV_CD」など、どういう情報が入っているか推測しづらい名前になっています。(実際には「事業部コード」を意味しています)
また、正規化されているので、このテーブルだけだとたとえ「事業部コード」だとAIが読み取れたとしても、事業部名はわかりません。
マスターテーブルとして以下の6つのテーブルを用意しています。例えば事業部名も利用したければ、M_BIZ_DIVテーブルとトランザクションのT_SLS_DTLテーブルをJOINする必要がありますね。
| テーブル | 件数 | 内容 |
|---|---|---|
| M_BIZ_DIV | 3件 | 事業部(01=家電, 02=アパレル, 03=食品) |
| M_SLS_DEPT | 6件 | 営業部門(各事業部×東京/大阪) |
| M_SLS_REP | 10件 | 営業担当者(田中太郎〜加藤由美) |
| M_PROD_CAT | 9件 | 商品カテゴリ(テレビ, 冷蔵庫, メンズ, 飲料 等) |
| M_PROD | 14件 | 商品(4K液晶テレビ, メンズジャケット, 冷凍餃子 等) |
| M_STS | 4件 | ステータス(10=受注, 20=出荷済, 30=売上計上, 90=返品) |
まずは「データセット」機能を利用して、Amazon QuickとMySQLを連携させます。
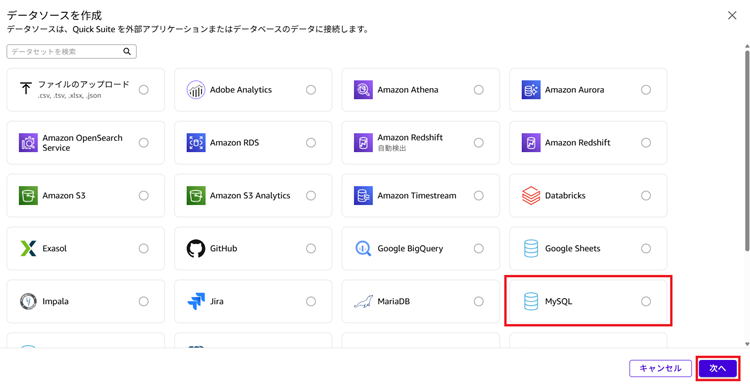
1. Amazon Quickにログインし[データセット]-[データソース]-[データソースを作成]をクリックします。
|
|
|
|
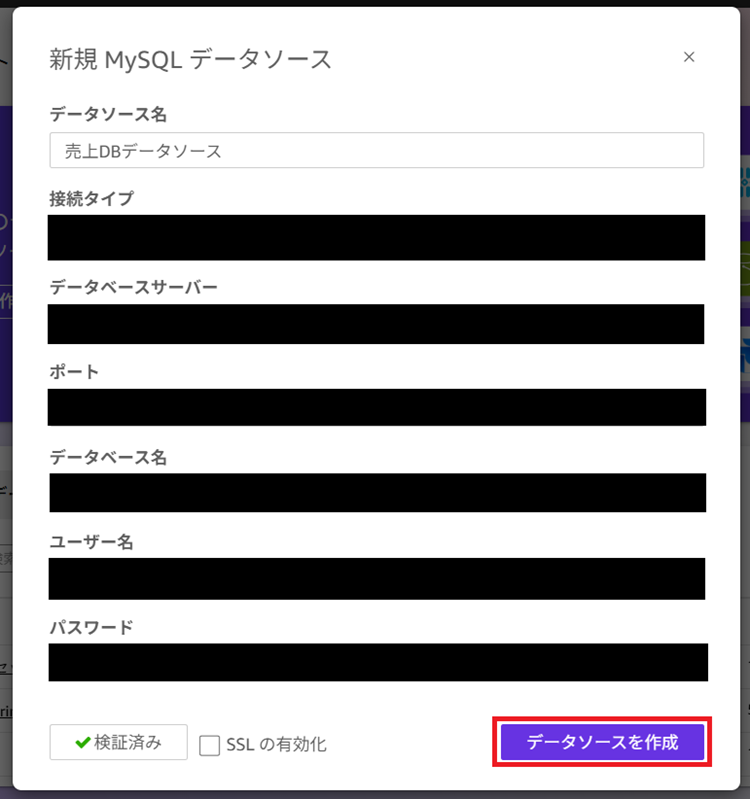
3. 接続先情報を入力し[データソースを作成]をクリックします。
※事前に左下の[接続を検証]をクリックし、エラーにならないことを確認してください。
|
|
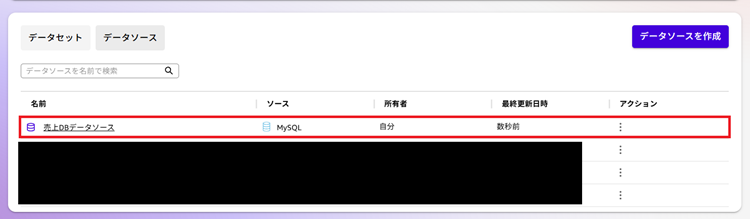
4.データソースが作成(データソースの情報が登録)されました。
|
|
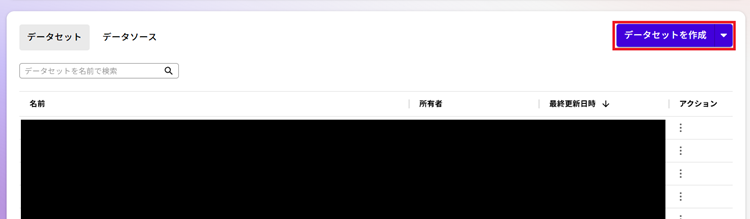
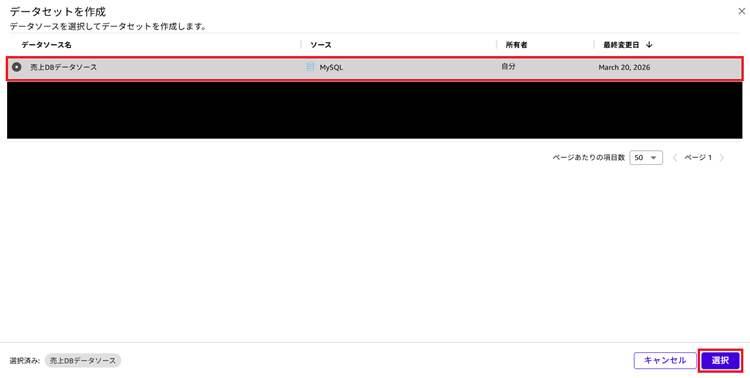
5. [データセットを作成]をクリックします。
|
|
6. 作成したデータソースを選択して[選択]をクリックします。
|
|
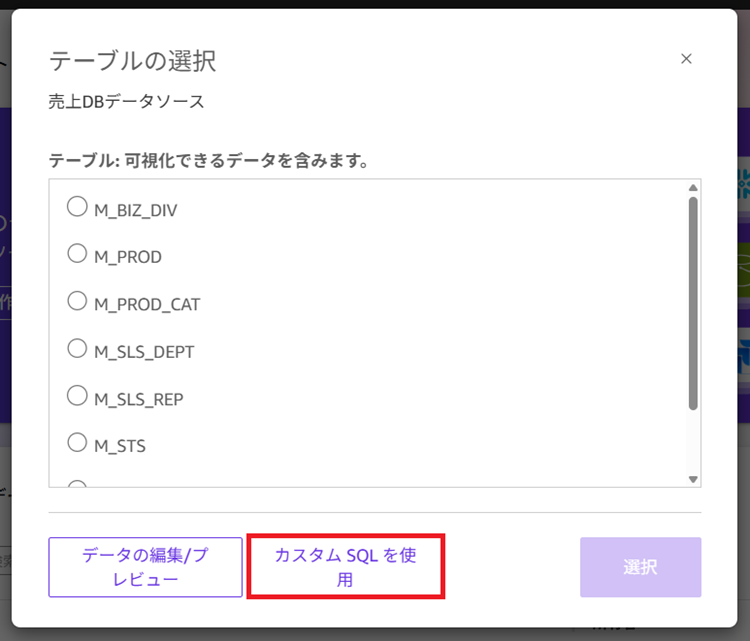
7. 利用可能なテーブル一覧が表示されます。今回はAIが利用しやすいように、トランザクションテーブルとマスタテーブルをJOINした状態のデータセットを作成したいので[カスタムSQLを使用]をクリックします。
|
|
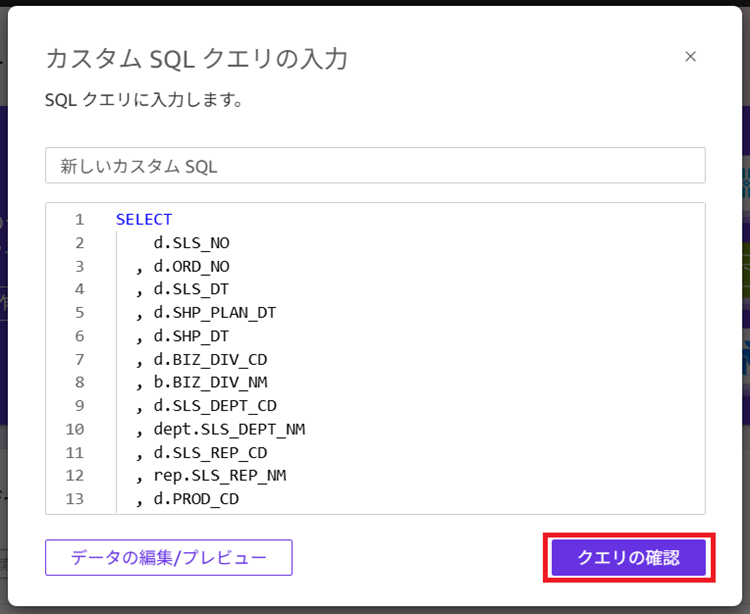
8. JOINしたい内容のSQLを記述して[クエリの確認]をクリックします。
|
|
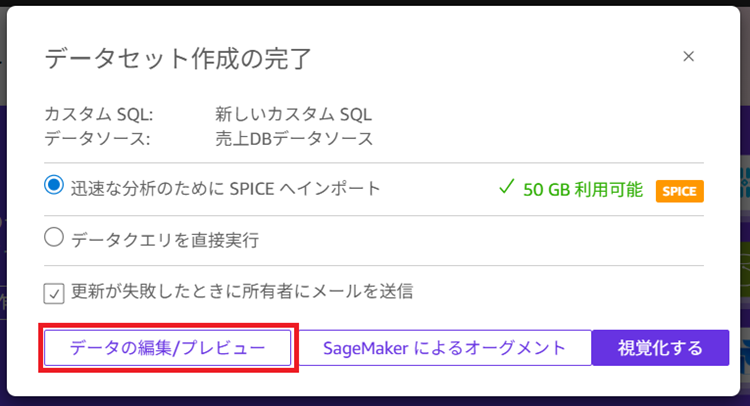
9. [データの編集/プレビュー]をクリックします。
※今回はSPICEへインポートを選択しています。SPICEはQuickのインメモリDBのような領域です。SPICEを選択することで毎回DB本体にクエリを実行する必要がなくなるため、DBへの負荷軽減やレスポンス向上が期待できます。
|
|
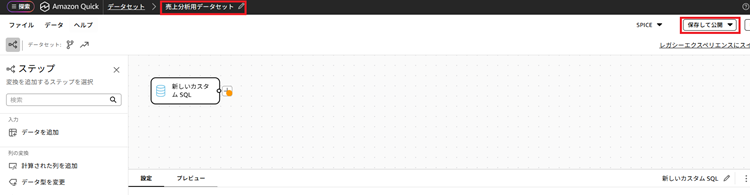
10. 画面左上の「カスタムSQL」となっている部分を任意の名前(今回は「売上分析用データセット」)に変更し、画面右上の[保存して公開]をクリックします。その後パンくずリストの「データセット」をクリックします。
|
|
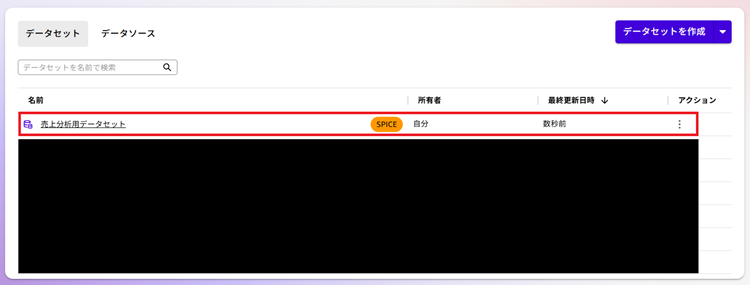
データセットが作成されました。
|
|
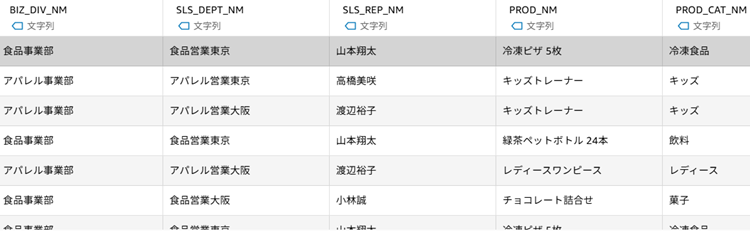
現状のデータセットはJOINされているので「BIZ_DIV_CD」といったコードではなく「BIZ_DIV_NM」のように実際の部門の情報が入っています。しかし、実際にユーザーがAIに質問する際は「BIZ_DIV_NM毎の売上合計金額を教えて」ではなく「事業部毎の売上合計金額を教えて」といった内容になるかと思います。最近のAIの性能であれば、データの中身を見て「この列は事業部列だな」と判断してくれる可能性はありますが、より精度を上げるためにはAIが理解しやすい情報に変換したり、追加の情報=コンテキストを与えることが重要です。「トピック」機能を利用するとこれらの設定を実施することができます。
|
|
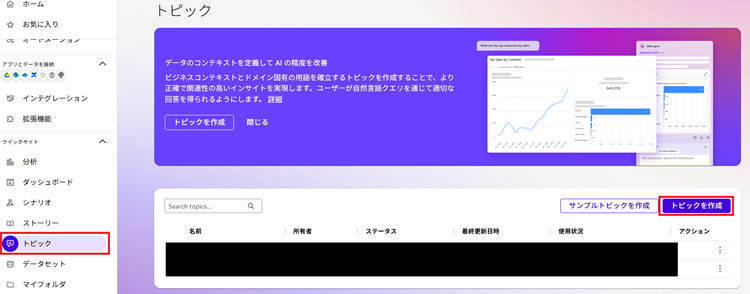
1. [トピック]-[トピックを作成]をクリックします。
|
|
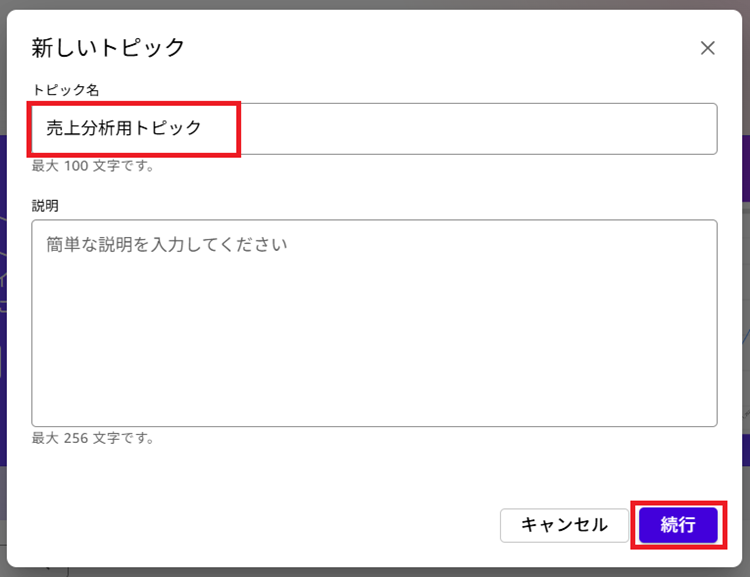
2. 任意のトピック名(今回は「売上分析用トピック」)を入力し[続行]をクリックします。
|
|
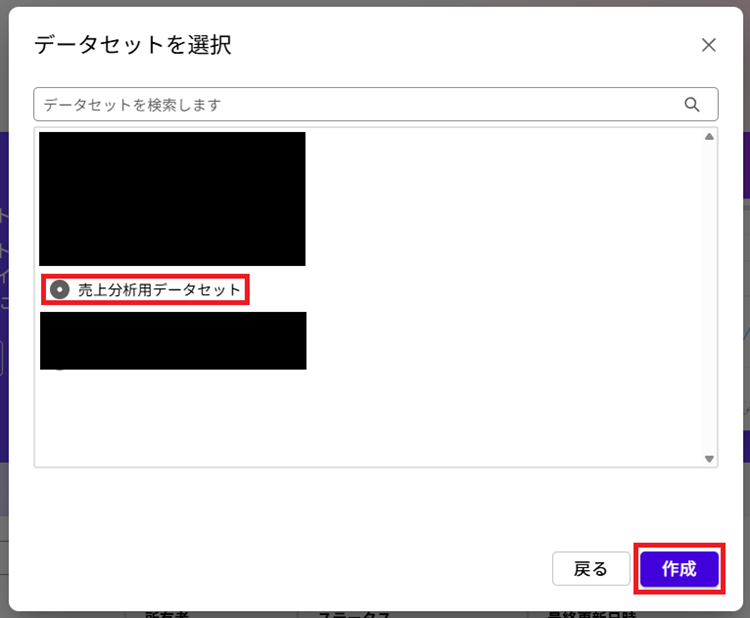
3. 先ほど作成したデータセットを選択し[作成]をクリックします。
|
|
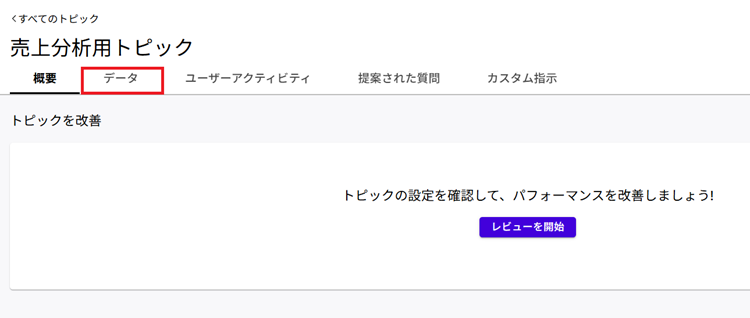
4. しばらくするとトピックの作成が完了します。続いて[データ]をクリックします。
|
|
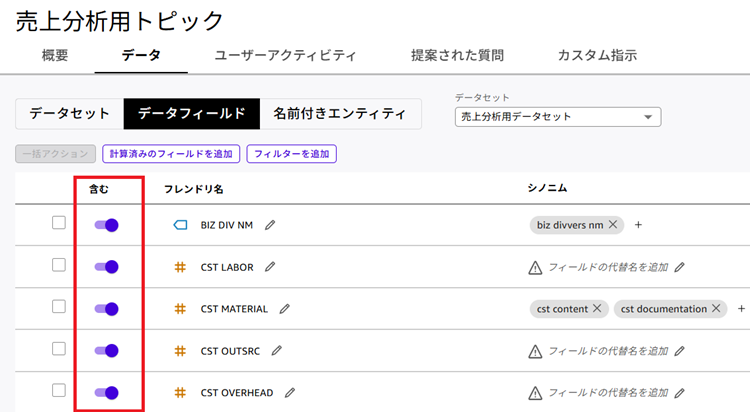
5. この画面でAIが理解しやすいデータにコンテキストを与えていきます。まず「含む」を設定します。「含む」でAIの検索対象に含めるか否かを選択します。管理コードなど分析に利用しないことが予想されるデータは対象から除外することでノイズを除去できます。今回は全ての列を検索対象にしたいので「含む」に加えておきます。
|
|
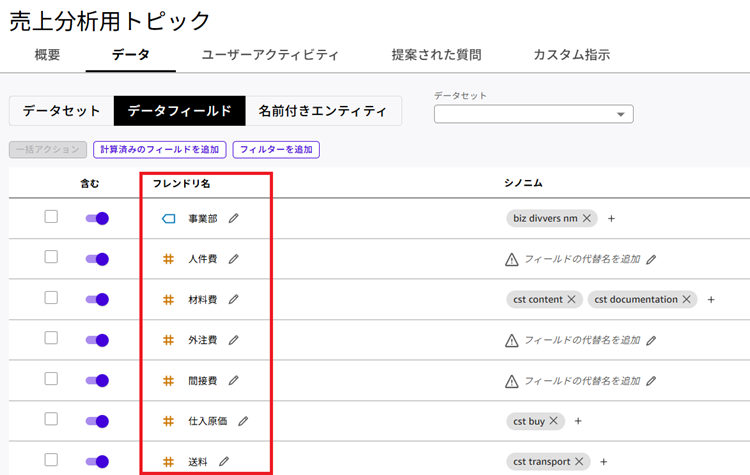
6. 続いて「フレンドリ名」を設定します。フレンドリ名は「AIや人間にとって理解しやすい名前」を付ける場所です。日本語のわかりやすい名前に変更します。
※ここでは手順は省きますが、私はKiro CLIを使って「データの内容を見てわかりやすいフレンドリ名をつけて」とお願いしました。列名が多いときに手動で変更するのは大変なのでAIに頼ると楽です。
|
|
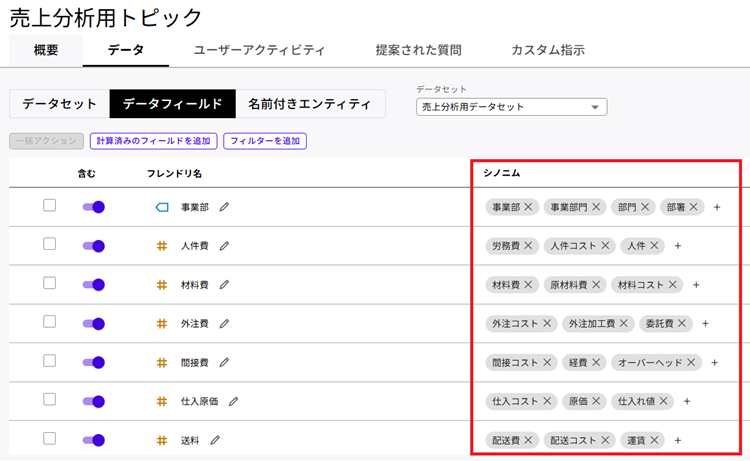
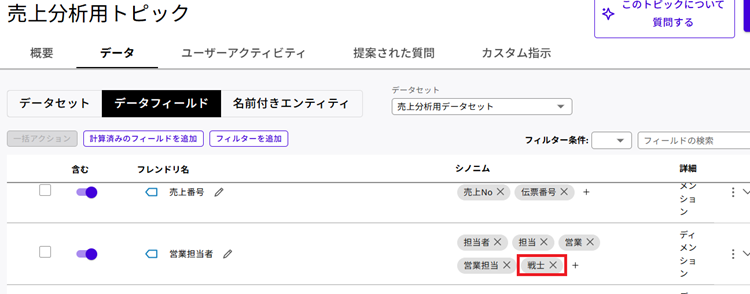
7. 続いて「シノニム」を設定します。シノニムは「別名」です。例えば「営業担当」と言う列があったとして、自社では「MD(マーチャンダイザー)」と呼ぶ人もいるような場合は、営業担当列のシノニムに「MD」と設定します。こうすることで「売上トップ10のMDを教えて」と質問した際にAIは「売上トップ10の営業を答えればいいんだな」と解釈できます。
|
|
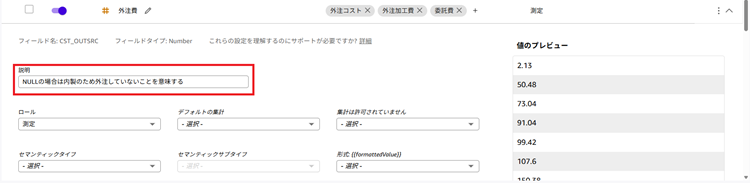
8. 最後に「説明」を追加します。説明を追加したい列をクリックすることで入力欄が表示されます。例えば「外注費」列に「NULLの場合は内製のため外注していないことを意味する」といった内容を入力します。このようにAIがテーブルの情報を見ただけではわからない補足情報を記載することで精度向上が期待できます。
|
|
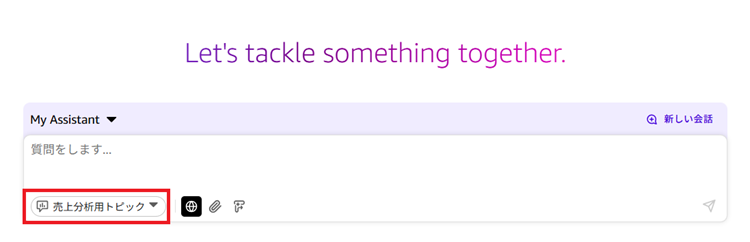
準備ができたので、実際にチャットエージェントで検索をしてみます。
チャットエージェントを開きます。「売上分析用トピック」が選択されていることを確認します。
|
|
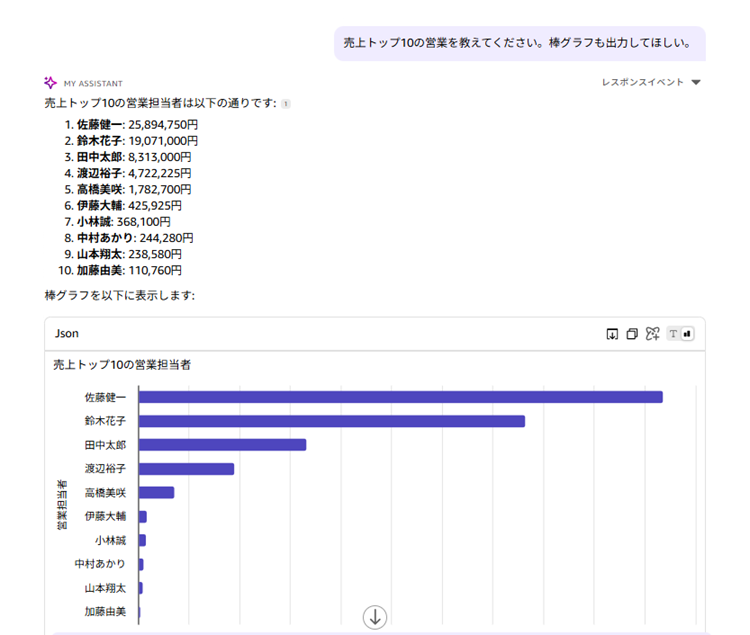
「売上トップ10の営業を教えてください。棒グラフも出力してほしい。」と聞いてみます。
|
|
期待通りの結果が出力されていることが確認できます。
|
|
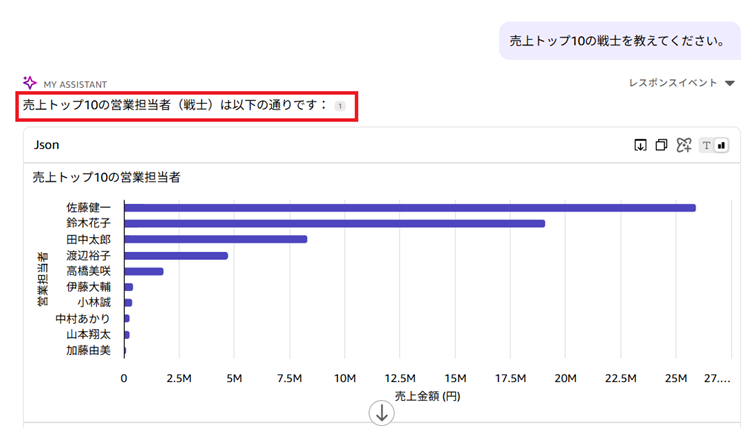
次にシノニムの効果を確認してみましょう。例えばこの企業では営業のことを「戦士」と呼ぶ人もいると仮定します。そこで「売上トップ10の戦士を教えてください。」と聞いてみます。
※念のためですが、弊社ではそのような文化はありません
|
|
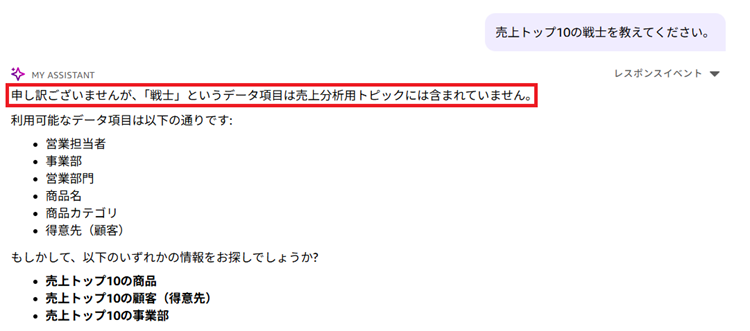
さすがに戦士=営業担当者とは理解できず、戦士と言う項目はない旨の回答がありました。
|
|
次にトピックで「営業担当者」のシノニムに「戦士」と入れて試してみます。
|
|
再度実行すると戦士=営業担当者と理解して、正しい回答を出力してくれました。
|
|
データセット機能を利用することで、データベースのデータをAmazon Quickのチャットエージェントで利用できるようになる具体的な手順をご紹介しました。今回は省きましたがデータセットにはスケジュール更新機能があるので「データベースのデータをQuickに日次で自動ロードする」といった処理もQuickの中で完結することができます。また、トピック機能を利用することでデータベースの情報だけでは理解しきれないコンテキストを付与する手順もご紹介しました。トピックには今回ご紹介しきれなかった機能が他にもありますので、活用すればさらなる精度向上が期待できます。

|
|---|
2008年新卒入社。eラーニング製品、MySQL、Verticaなどのエンジニアを経て、 2019年から2年間限定で採用活動を担当。2021年に技術職に戻り、AWSに関する支援や研修の提案に従事している。...show more
|
|
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します

この記事では「AWS Control Towerとは?マルチアカウント管理を自動化する仕組み」をご紹介します

この記事では、Amazon Bedrockを使って問い合わせメールを解析・JSON形式に構造化し、S3×Lambda×Google Chat連携で自動通知する「生成AIによる業務効率化・自動化」の実践方法を解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

