

- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
アシストの笠原です。
暖かくなってきて、春を感じる日が多くなってきました。
さて、Oracle Exadata Database MachineにおけるSQLチューニングの基本的なプロセスについてご紹介する、全3回の内の2回目です。
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(Smart Scan 編)
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(パラレルクエリー編) ★本記事★
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(ハッシュ結合編)
第1回は、Exadataの最も代表的な機能といえる Smart Scan によるSQLチューニング手法をご紹介しました。
第2回の今回は、パラレルクエリーを使ってさらに性能を引き上げる方法をご紹介します。
Exadataとパラレルクエリーは非常に相性が良い組み合わせです。どれくらい効果があるのか、検証結果も記載していますのでぜひ最後まで御覧ください。
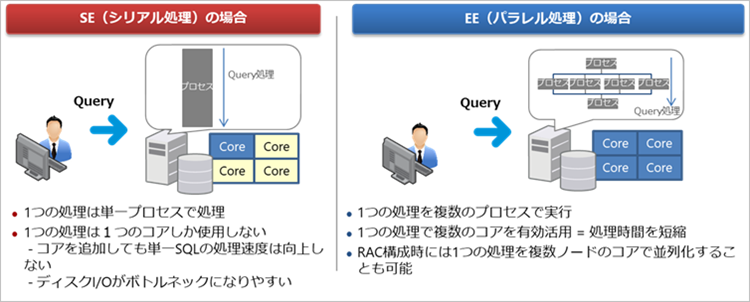
パラレルクエリーはSQLを複数のプロセスで並列処理する仕組みです。
|
|
プロセスを処理するExadataの搭載CPUですが、Intelの最新CPUが搭載されています。
X9M-2 では第3世代XeonプロセッサであるXeon 8358 processors (2.6 GHz) 32コアが2つです。
パラレルクエリーの機能そのものはEEの標準機能ですが、Exadataに搭載されている複数のCPUを有効活用し、更にSmart Scanと併用し最大の効果を得ることができます。
Exadataでは、大量データのクエリーにはパラレルクエリーを前提としてチューニングします。
複数CPUコアで一つのSQLを並列処理するパラレルクエリーですが、並列度を闇雲に大きくすればよいというわけではありません。多すぎる並列度は、多数のスレーブプロセスの生成、OSメモリの枯渇を引き起こし、システム全体がスローダウンする危険性があります。
並列度は以下の指針を基準にすることをお勧めします。
| オブジェクトサイズ | 指針 |
|---|---|
| 小: 200MB以下 | 並列化対象外 |
| 中: 200MB~5GB | 並列度2-4 |
| 大: 5GB以上 | 並列度4以上(2の累乗) |
パラレルクエリーを実装する方法は以下の4通りがあります。同時に設定した場合は、上から順に優先的に採用されます。
SQLにPARALLELヒントを付与することで、SQL単位でパラレルクエリーを強制することができます。
パラレルクエリー化したいSQL本数が少ない場合に望ましい方法です。
文レベルで並列度を指定する場合 SQL> SELECT /*+ PARALLEL(<並列度>) */ … FROM …; オブジェクト毎に並列度を指定する場合 SQL> SELECT /*+ PARALLEL(<テーブル名> <並列度>) */ … FROM <テーブル名> ;
オブジェクトレベルで並列度の設定が困難な場合は、セッションレベルで並列度を指定したパラレルクエリーを強制することを検討してください。
SQL> ALTER SESSION FORCE PARALLEL QUERY PARALLEL <並列度>;
無効化したい場合は、下記SQLを実行します。
SQL> ALTER SESSION DISABLE PARALLEL QUERY;
オブジェクト定義にPARALLEL属性を設定し、並列度を明示的に指定することができます。
該当のオブジェクトにアクセスするクエリーがパラレルクエリーとなります。
アプリケーションの改修が不要な反面、新規のSQLやOLTP系でパラレルで動かしたくないSQLがある場合に対応が難しいという面があります。
OLTP系の処理が含まれないDWHや分析系のオブジェクトでの設定が望ましいです。
表への並列度の設定方法は下記のように行います。
SQL> CREATE TABLE <テーブル名> PARALLEL <並列度>; もしくは SQL> ALTER TABLE <テーブル名> PARALLEL <並列度>;
パッケージソフトをお使いの場合など、上記3つのパラレル設定が難しい場合はパラレルクエリの実行と並列度をOracleに判断させる「自動並列度設定」機能を使用することができます。
ただ、この機能はデータベース管理者による並列度の制御が難しいため、弊社ではあまりお勧めしていません。多数の処理が同時に実行される本番環境では、重要な処理で並列度が確保できず処理遅延が起きる、といった事例がいくつもあります。あくまで他の方法が難しい場合に初期化パラメータ parallel_degree_policy=AUTOによる自動並列度設定を検討することになります。
それでは、実際にパラレルクエリーの効果を見ていきたいと思います。
検証にあたって用意したデータは Smart Scan編と同様の構成です。
約7億件のデータを持つテーブルで検証を実施しています。
TABLE_NAME NUM_ROWS TBL SIZE(GB) ----------------- -------------- ---------------- ORDER_ITEMS 716651816 5.38645935
Smart Scan で140秒を7秒にチューニングしたSQLを、更にヒント句でパラレルクエリー化してみました。同じ条件で、7億件のテーブルの中から1割未満のデータを参照するSQLを実行してみます。
SQL> select /*+ PARALLEL(4) NO_INDEX(order_items) */
count(return_date) from order_items
where dispatch_date between to_date('2012/03/01','yyyy/mm/dd') and to_date('2012/03/15','yyyy/mm/dd');
COUNT(RETURN_DATE)
------------------
1773628
Elapsed: 00:00:03.76 ←SQLの処理時間は処理時間 3.76秒
Execution Plan ←SQLの実行計画
----------------------------------------------------------
Plan hash value: 661298821
-------------------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | TQ |IN-OUT| PQ Distrib |
-------------------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 8 | 54666 (3)| 00:00:03 | | | | | |
| 1 | SORT AGGREGATE | | 1 | 8 | | | | | | | |
| 2 | PX COORDINATOR | | | | | | | | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | 8 | | | | | Q1,00 | P->S | QC (RAND) |
| 4 | SORT AGGREGATE | | 1 | 8 | | | | | Q1,00 | PCWP | |
| 5 | PX BLOCK ITERATOR | | 716M| 5467M| 54666 (3)| 00:00:03 | 1 | 32 | Q1,00 | PCWC | |
|* 6 | TABLE ACCESS STORAGE FULL| ORDER_ITEMS | 716M| 5467M| 54666 (3)| 00:00:03 | 1 | 32 | Q1,00 | PCWP | |
-------------------------------------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
6 - storage("DISPATCH_DATE">=TO_DATE(' 2012-03-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DISPATCH_DATE"<=TO_DATE('
2012-03-15 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
filter("DISPATCH_DATE">=TO_DATE(' 2012-03-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DISPATCH_DATE"<=TO_DATE(' 2012-03-15
00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
Note
-----
- dynamic statistics used: dynamic sampling (level=5)
- Degree of Parallelism is 4 because of hint ←ヒント句で並列度4が設定されている
Statistics
----------------------------------------------------------
22 recursive calls
0 db block gets
701724 consistent gets
700631 physical reads
6452 redo size
554 bytes sent via SQL*Net to client
542 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
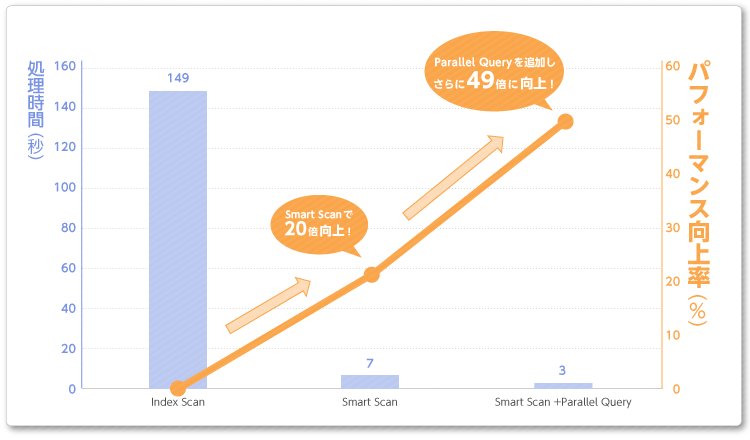
実行時間は3.76秒。前回の Smart Scan で 7.52秒にチューニングした処理を更に高速化できました!
|
|
ポイントは、実行計画に出てくる「PX …」 で始まるアクセスパスです。
これは、内部でスレーブプロセスを複数生成し、並列処理を行っていることを表しています。
Id 6 の「TABLE ACCESS STORAGE FULL」は Smart Scan 対象の操作です。
その前段の Id 5 ではスレーブプロセス毎に表データを範囲分割しています。
プロセスを複数生成し並列実行させることで、複数のCPUコアでSQLが処理されます。
Id 4 では、下位の実行結果を受け取って、集計操作を実施します。この部分も並列で実行されます。
Exadata固有機能である Smart Scan と、最新のIntel CPUを最大限活用して大容量データのスキャンとデータの集計処理を高速に処理するというわけです。
第2回の記事はいかがでしたでしょうか。Exadata+パラレルクエリーの効果について理解が深まれば幸いです。
次回は、表の結合に関するExadataのセオリーを紹介する予定です。お楽しみに。

|
|---|
2003年入社。10年以上Oracle Databaseの技術サポートに従事したのちフィールドエンジニア部隊に配属。Exadata X7、X8、X8M、Exadata Cloud at Customer(ExaCC)を使用した基幹システムのリプレースプロジェクトに携わる。お客様の要件にそった設計、最適化、運用支援、データ移行、DB・SQLチューニングまで幅広く対応。...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

