












- Snowflake
AI×BIの使い分けと最適解 - なぜ今、Snowflakeユーザーに「Sigma」が選ばれるのか? -
【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。
![]()






|
|
2026年1月20日、Snowflake合同株式会社のオフィスにて、セミナー「Agentic AIと実現するデータドリブン」を開催いたしました。Snowflakeの生成AI機能を活用し、組織の意思決定を高度化する「次世代データ活用基盤」の構築方法について、検証結果を交えてご紹介しました。
セッションレポート後編となる本記事では、「Agentic AI」の具現化にフォーカスします。
構造化データを扱うCortex Analystと、非構造化データを扱うCortex Search。これらをいかに組み合わせ、精度の高いアウトプットを引き出すのか。検証結果をもとに、エンジニアが知っておくべき実装の勘所と「エージェント化」のリアルをお届けします。
Index
Snowflake CortexでビジネスをAIに理解させるための検証結果をご紹介します。
Snowflake Intelligence、Cortex Agents、Cortex Analyst、Cortex Searchのアーキテクチャはこちらの記事でご紹介しておりますので、こちらもあわせてご確認ください。
検証は、次の2つです。
検証項目は次の通りです。
非構造化データ
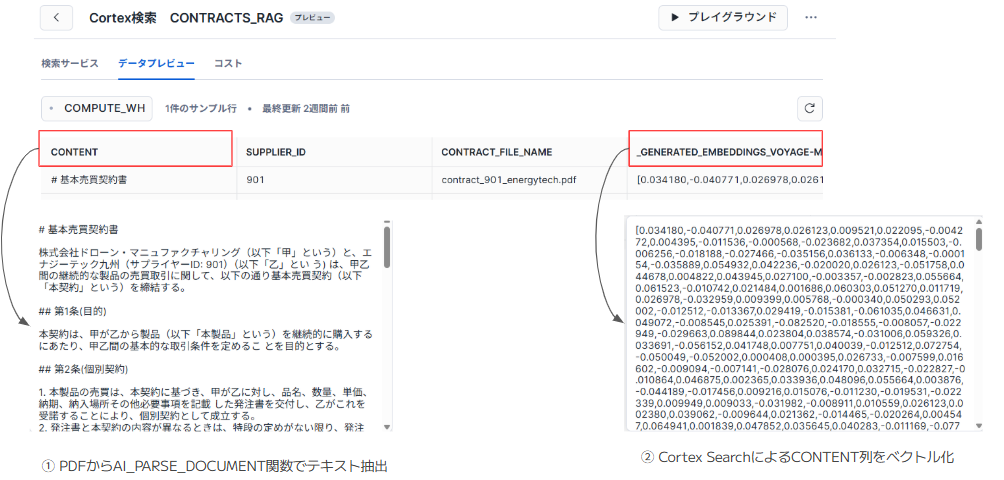
PDF形式のサンプルの契約書をSnowflake Cortex Searchを用いてRAG化し、納期が遅延した場合に契約書に記載されている内容に基づいた回答を実施できるかを検証します。
契約書の第12条に納期に遅延した場合の違約金に関する文言を含めています。
|
構造化データ
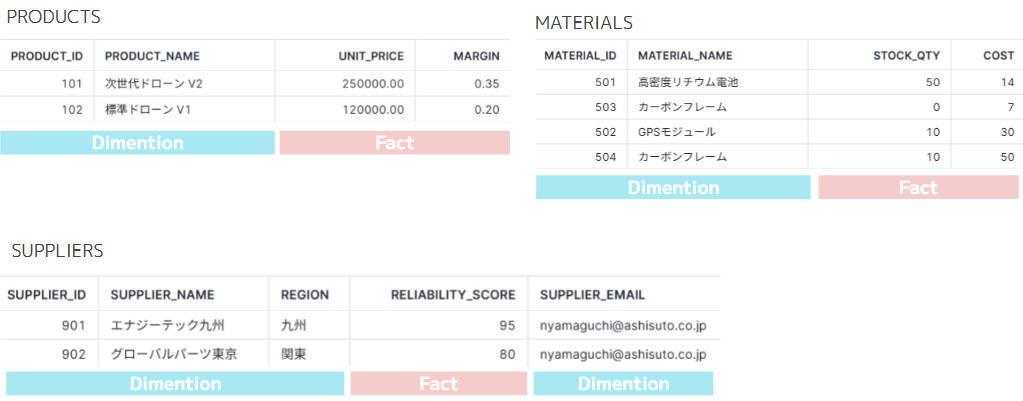
完成品(PRODUCTS)、部材(MATERIALS)、サプライヤー(SUPPLIERS)は次の通りです。
|
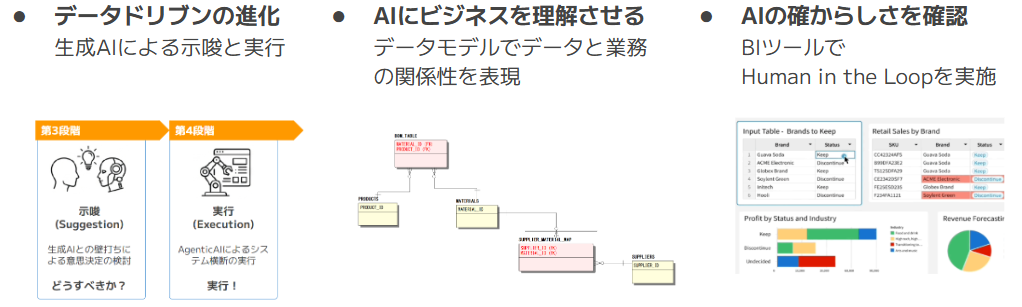
完成品(PRODUCTS)、部材(MATERIALS)、サプライヤー(SUPPLIERS)における業務を説明したデータモデルです。
|
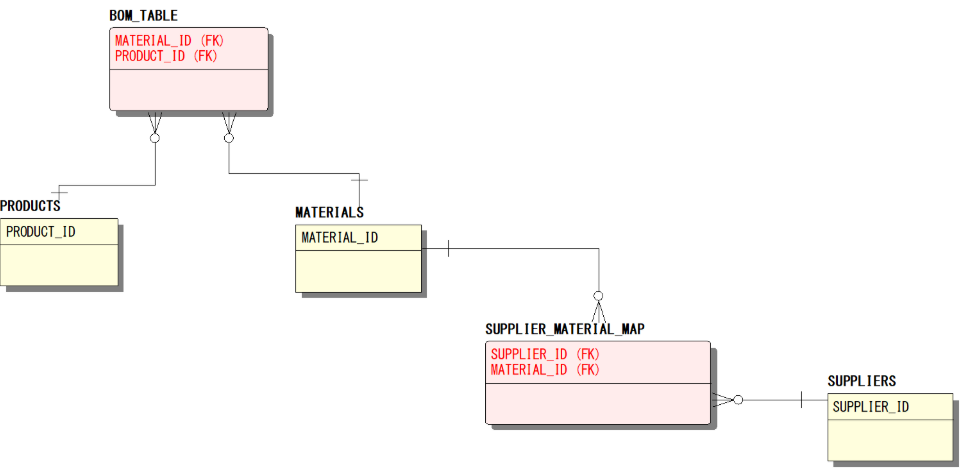
完成品(PRODUCTS)、部材(MATERIALS)、サプライヤー(SUPPLIERS)のそれぞれの関係性を表現したテーブルです。
BOM_TABLEテーブルは、どの完成品にどの部材が必要なのかが確認でき、SUPPLIER_MATERIAL_MAPテーブルは、そのサプライヤーからどの部材を仕入れているのか、を確認できます。
|
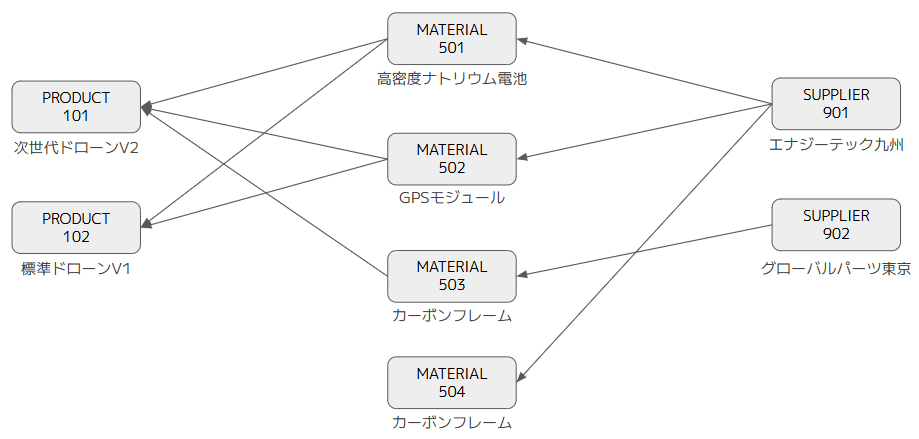
これらの5つのテーブルから次のように表現できます。
|
セマンティックモデル実装(Cortex Analyst)
構造化データについて、SnowflakeのSnowsight上からセマンティックビューとして実装しています。それぞれ画像13,画像14にあるテーブルの各列項目をディメンション、ファクトの項目として実装します。
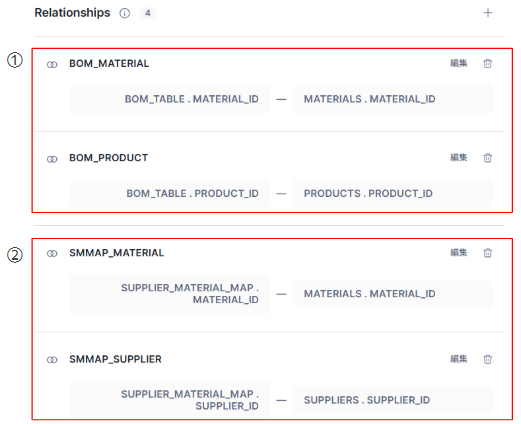
ポイントは、画像5の各テーブルの関係性をリレーションシップで実装しています。
画像16の①が完成品(PRODUCTS)と部材(MATERIALS)の関係の定義、②が部材(MATERIALS)とサプライヤー(SUPPLIERS)の関係を定義しています。
|
RAG実装(Cortex Search)
画像12のサンプル契約書(PDF)をCortex SearchでRAGの実装を行います。
|
AIエージェント実装(Cortex Agents)
Cortex AnalystとCortex Searchが実装できましたので、それをCortex Agentsに登録します。今回は、サプライヤーにメール送信させるために、事前に作成しているメール送信のプロシージャをカスタムツールに登録しています。
|
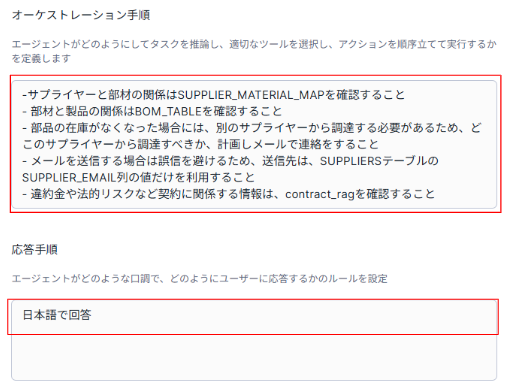
また、Cortex Agentsのオーケストレーションで、データモデル関係性とサプライヤーにメール送信する場合の指示を指定しています。
|
最後に作成したCortex AgentsをSnowflake Intelligenceに登録して完了です。
次の4つのプロンプトをSnowflake Intelligenceから実行しました。
※本内容は2026年1月時点の検証結果に基づいています。
生成AIモデルの進化やアップデートにより、現在とは結果が異なる可能性がある点をご了承ください。
プロンプト①:関東からの供給がストップした場合に影響を受ける製品は?
関東のサプライヤー(グローバルパーツ東京)を特定し、供給している部材(カーボンフレーム)から影響する製品(次世代ドローン)を特定しているため、業務を理解して回答できています。
|
プロンプト②:カーボンフレームの供給が停止した場合の影響と、その対策は?
カーボンフレームのサプライヤーと影響する完成品を特定しています。供給が停止した場合の影響として、別サプライヤーから供給するように示唆してきています。
|
プロンプト③:九州で大規模な停電が発生した。これによる影響、および納期遅延による損害への対応は?
九州のサプライヤーを特定し、そのサプライヤーから供給している部材、その部材を使用している完成品を特定しています。
また、納期遅延した場合の影響をサンプル契約書にある情報を提示しており、Cortex Agentsがツールを使い分けていることが確認できます。
|
プロンプト④:(MATERIALSテーブルのカーボンフレームの在庫数をゼロにしてから)在庫状況を確認して
Cortex Agentsのオーケストレーション手順で在庫がなくなった場合、サプライヤーに連絡することを指示しているため、現在の在庫状況を分析し、指示したアクションを実施できるかを確認しました。
結果としては、在庫数から連絡する必要性があると判断し、カスタムツールで設定しているメール送信プロシージャを実行し、メール送信を実施しています。
|
プロンプト①から④の結果を受けて、データモデルを理解して必要な示唆を提示していると判断しました。また、Cortex Agentsに登録したCortex Analyst、Cortex Search、カスタムツールを必要に応じて呼び出して実行しています。
しかし、今回利用したデータモデルは簡単な構造であったため、より複雑な構成の場合の挙動確認が必要です。また、Cortex Agentsで指定したオーケストレーション手順もより適切な表現が必要になったり、プロンプトの量が増加するとその分、コストにも影響するため、よりスマートな実装方法が必要になるケースも出てくるだろうと考えています。
検証1ではAIエージェントの自律的なアクションを確認しました。続く検証2では、人間(BIツール)とAIがどのように協調して意思決定を行うのかを検証します。
検証2では、Snowflake社ハンズオンのデモデータで、各部門の横断的な分析をSnowflake IntelligenceとBIツールを用いてデータドリブンを実施していきます。
BIツールはSigmaを利用しています。SigmaはSnowflakeで作成したセマンティックビューを利用することができるため、同じデータに対して分析を行うことが可能です。
テーブル構成は次の通りです。ディメンションテーブルは数が多いため割愛させて頂きます。
上記のテーブルに対して次のセマンティックビューを作成しています。
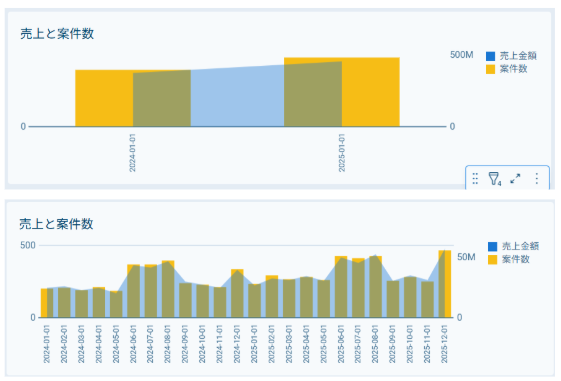
Sigmaで2024年と2025年の売上と案件件数をみると2025年の売り上げが好調であることがわかりますが、その原因がまだ不明です。
|
Snowflake Intelligenceに次のプロンプトを投げた結果、データよりマーケティング効果を示唆する結果を得ることができました。
プロンプト①「2024年と比較して2025年の売上が増加している原因は?」
|
Snowflake Intelligenceでは、推論している内容を画面上から確認できますが、投入されたプロンプトに対して、回答するために必要なデータに対してアクセスし、その結果をさらに分析し、データに対してアクセスする、とまさにデータドリブンを実施していることがわかります。
|
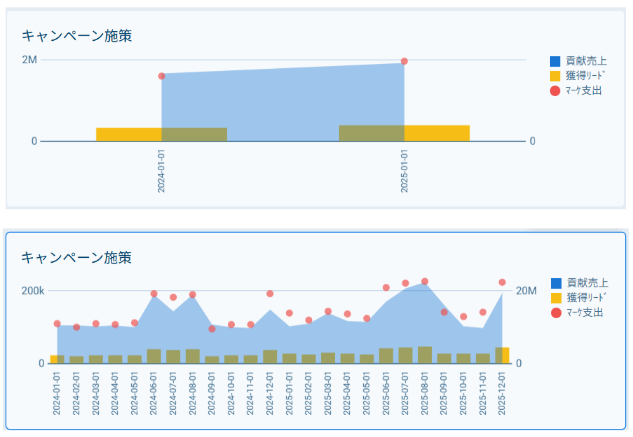
ここで、本当にマーケティングの支出が影響しているのか、Sigmaで確からしさを確認したところ、画像27の上のグラフから確かに支出と獲得リードの相関は見受けられました。
|
さらにSigmaでグラフをドリルダウンしたところ、画像27の下のグラフのように6月、7月、8月、12月が明らかにマーケ支出が高くなっていることがわかりました。
この理由について、Snowflake Intelligenceで確認したところ、次のような分析した結果を得ることができました。
プロンプト②「6月,7月,8月,12月にマーケティングの支出が高い理由は?」
|
|
自然文で問い合わせる際にその用語の正しさなどの確認にもSigmaの利用は役に立ちます。
Snowflake IntelligenceとSigmaを往復して分析することで、全体を俯瞰して傾向に気づくことや、グラフ化していない項目や期間も考慮して分析が可能となり、有益な分析を実施することが可能です。AIによるデータドリブンと、人がBIでデータドリブンを交互に繰り返して実施していくことが大切であることがわかりました。
また、Sigmaでグラフを作成する際にもSnowflake Intelligenceの結果を利用することで、レポート作成時間の短縮につながりました。
今回の検証を通じ、生成AIがデータドリブンを真に「進化」させる姿をお届けしました。
ポイントは、データモデルによって業務をAIに深く理解させることと考えます。自社に特化した文脈でAIが思考し、独自の示唆を得られる環境が、他社には真似できない競争優位性を生み出します。
Snowflake Intelligenceは、自律的にデータを探索し、私たちに新たな視点を与えてくれるAgentic AIの先駆けです。
「AIによる示唆」と「人間によるBIでの深掘り」を往復し、双方の強みを融合させること。
上記が複雑なビジネス環境において正しい意思決定と実行を導き出す、次世代のデータドリブンの姿であると考えています。
|
この記事が役に立ったら、ぜひX(旧Twitter)などでシェアしてください。
#SnowflakeIntelligence #AgenticAI #Snowflake
▼セッションレポート前編もご覧ください。
|

|
|---|
1998年入社。Oracle Databaseエンジニアを経て、Hadoopビジネス検討立ち上げや、パートナーとVMware、Nutanixなど仮想基盤の提案、提供を実施。その後カスタマーサクセスを...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。

【初心者向けの解説記事】Snowflakeは何がすごいのか、Snowflake Squadの認定スペシャリストが特長やアーキテクチャをわかりやすく説明します。

データ活用は「予測」から「アクション」へ。Snowflake×アシストが共催したセミナーの模様をレポートします。AIにビジネスを正しく理解させる鍵となる「セマンティックモデル」の重要性や、Snowflakeを用いた実装戦略など、当日語られた核心部分を凝縮して解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

