





- Snowflake
AI×BIの使い分けと最適解 - なぜ今、Snowflakeユーザーに「Sigma」が選ばれるのか? -
【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。
![]()






|
|
Snowflakeは、単なるデータウェアハウス(DWH)という役割だけでなく、蓄積されたデータを最新の生成AIを利用して、データドリブンを実現できるデータ活用プラットフォームです。シンプルな操作によって、生成AIを駆使しながらデータにアクセスして、インサイトを得ることができるようになりました。
本稿では、そのSnowflakeの生成AI の魅力をお伝えします。
なお、Snowflake Intelligenceの機能は多岐にわたるため、本記事(PARTⅠ)と次回のPARTⅡの2回に分けて、基礎から実践的な構築までを余すところなくご紹介します。
【全2回】本記事は、全2回にわたるシリーズ記事の前変(PARTⅠ)です。
▼PARTⅡはこちら
Index
6月にサンフランシスコで開催された Snowflake Summit 2025において、Snowflakeの設計思想として、「SIMPLICITY(シンプルさ)」が掲げられました。複雑性はリスクを生み、コストを生み、摩擦を生む、というメッセージです。
複雑さを排除し、誰もがデータから価値を引き出せるようにするといったこのメッセージは、まさにSnowflakeによってデータを統合し、活用するためのプラットフォームを表していると共感しました。このSIMPLICITYの設計思想はSnowflakeの生成AI機能にもしっかりと反映されています。
なぜSnowflakeの生成AI機能はシンプルなのか?その3つの理由をご説明していきます。
生成AIを利用する場合、セキュリティ面、コスト面をしっかりと管理する必要があります。生成AIの活用手段として、自社の情報を生成AIに処理させることで、自社固有の情報をもとに資料を作成したり、新たな洞察を得ることがあります。その場合、自社のデータが外部に流出する危険性の確認が必要です。
Snowflakeは、生成AIのモデルをSnowflakeの基盤上にホスティングしているため、自社のデータがSnowflake基盤外に流出する危険性がありません。また、勝手に学習データとして利用されないため、安心して生成AIを利用できます。
コスト管理については、Snowflakeのクレジット機能に統合されているため、今まで実施しているSnowflakeのクレジット管理の仕組みがそのまま利用できます。
Snowflake AI Trust and Safety FAQs
生成AIの利用を開始する場合、いずれかのサービスに契約して、APIキーの発行を行い、LangChain、Difyなどを用いて開発していくため、Pythonの知識や新しいツールの習得が必要になりますが、Snowflakeでは、SQLの中にプロンプトを埋め込むだけで利用することが可能です。
LangChainでプログラミングした場合とSnowflakeのSQLで同じことを実装した場合、これだけのステップを簡素化することが可能です。
Snowflakeはより直感的に生成AIを活用できることをご理解いただけたかと思います。
LangChainの場合
from langchain.llms import OpenAI
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
import os
# OpenAIのAPIキーを設定(環境変数で)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key-here"
# プロンプトテンプレートを作成
prompt = PromptTemplate(
template="次のトピックについて日本語で分かりやすく説明してください: {topic}")
# LLMインスタンス化
llm = OpenAI(temperature=0.7)
# LLMChainを作成
chain = LLMChain(llm=llm, prompt=prompt)
# 実行
response = chain.run("snowflake")
print(response)
Snowflakeの場合
select ai_complete('claude-4-sonnet','Snowflakeについて分かりやすく説明してください');
生成AIの機能は、すべてSQLで操作することが可能です。また、データ移動が不要で生成AIとデータのガバナンスも統一されています。煩雑なデータパイプラインを構築することなく、データが生成AIのインプットとしてすぐに利用することができます。
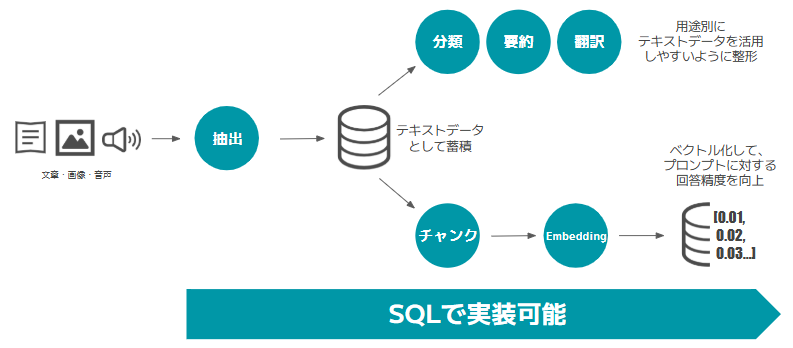
Snowflakeならば、文章、画像、音声といったそれぞれの非構造化データから特徴をテキストデータとして抽出、テーブルに格納することが簡単に実現できます。
テキストデータ化できれば、分類、要約、翻訳といった自然言語タスクを実行することもできますし、ベクトル化してRAGのシステムとして実装することができます。
|
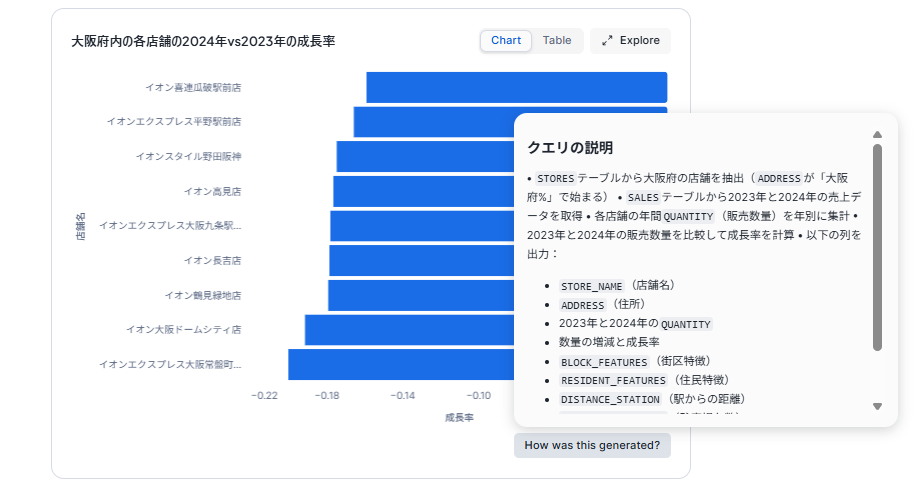
画像1:生成AI機能によるデータ活用
ここからは具体的にSnowflakeの生成AIについてご紹介していきます。まずは、有益な情報が含まれているPDFや画像の情報をデータベースに取り込む機能をご紹介します。
AISQL関数※1 は、SQL文中で利用することができるAI機能が実装された関数です。現在も多くの関数がリリースされており、最近では、非構造化データから個人識別情報(PII)を検出し、編集するAI_REDACT関数がプレリリースされましたので、これからもビジネス要件にあった関数がリリースされていくと想像しています。
※1:AISQL関数は、2025年12月から「AIFunctions」に名称が変更されます。
| 関数名 | 機能 | 対応フォーマット |
| AI_COMPLETE | プロンプトにより汎用タスクを実行するLLM | テキスト / 画像 |
| AI_CLASSIFY | ユーザーが指定したラベルに分類 | テキスト / 画像 |
| AI_FILTER | 入力に対して True/Falseの判定を実施 | テキスト / 画像 |
| AI_AGG | プロンプトによりグループのインサイトを出力する集計関数 | テキスト |
| AI_SUMMARIZE_AGG | グループの要約を出力する集約関数 | テキスト |
| AI_EMBED | データのベクトル化を実施 | テキスト / 画像 |
| AI_SIMILARITY | 2つの入力のコサイン類似度を出力 | テキスト / 画像 |
| AI_TRANSCRIBE | 音声データのテキスト化や話者識別を実施 | 音声 |
| AI_PARSE_DOCUMENT | ドキュメントからテキストを抽出(OCR/レイアウト) | テキスト / ドキュメント / 画像 |
| AI_EXTRACT | 入力データからプロンプトに従いデータを抽出する | テキスト / ドキュメント / 画像 |
| AI_SENTIMENT | 入力データの感情分類を実施 | テキスト |
| TRANSLATE | テキスト翻訳を実施 | テキスト |
| EXTRACT_ANSWER | テキストからプロンプトに従い回答を抽出 | テキスト |
| SUMMARIZE | テキスト要約を実施 | テキスト |
| AI_REDACT | PII情報をマスキング | テキスト |
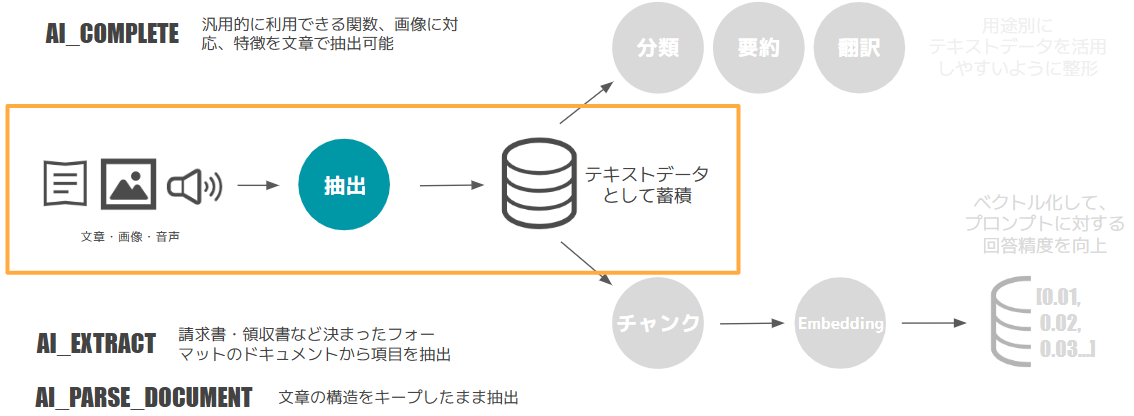
今回はその中から次の3つのAISQL関数をご紹介します。
|
画像2:3つのAISQL関数
「AI_COMPLETE関数は、最も汎用的な AISQL 関数です。関数の引数に生成 AI モデルとプロンプトを直接指定することで、その結果を得ることができます。」
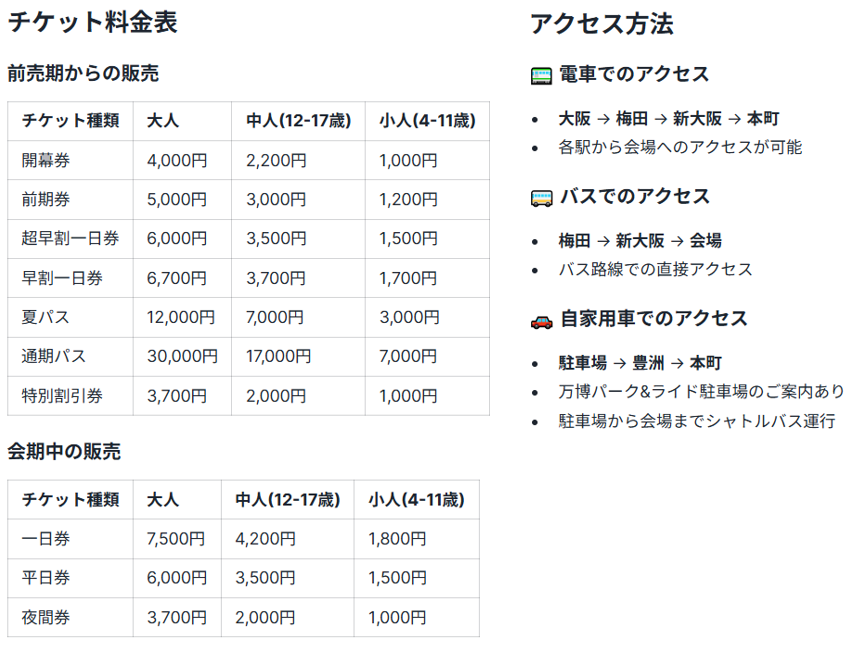
次のようなチラシの中には、沢山の情報が存在しています。この中から、チケット料金の情報や、会場までのアクセス方法を情報として抽出したい、といった要望をよく伺います。最近の生成AIモデルは、このような画像から記載されている情報を正しく読み取る能力が向上しています。
|
画像3:サンプルリーフレット
こちらのチラシはあらかじめ内部ステージを作成し、画像ファイルにして配置しておきます。
早速AI_COMPLETE関数を実践してみますが、次のSQLで必要な情報を抽出することが可能です。
alter account set CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION';
select ai_complete(
'claude-sonnet-4-5',
prompt('画像{0}から次の情報をMarkdown形式で整理してください
- 表形式の情報を抜き出してください
- アクセス方法をわかりやすく表現してください',
to_file('@DEMO_AISQL_IMAGE_STAGE','leaflet.jpg')));
より最新の生成AIモデルを利用したいため、1行目でクロスリージョン推論を有効にしています。
AI_COMPLETE関数では、第一引数で利用したい生成AIモデルを指定し、第二引数でPROMPT関数を用いながら、生成AIモデルに渡したいプロンプトを記載しています。
プロンプトには、表形式の情報とアクセス方法について、Markdown形式で抽出するように指示をしています。
また、PROMPT関数では、内部ステージに配置している画像ファイルを指定しています。
結果はこちらです。
|
画像4:サンプルリーフレットから抽出した結果をMarkdownで表現
こちらは、Streamlitで表示した結果ですが、Markdown形式で出力させたため、きれいに表示され、情報もしっかり抽出できていることがわかります。
AI_COMPLETE関数は、ChatGPTなどで入力するようなプロンプトを実行することができる汎用的な関数と言えます。
AI_EXTRACT関数は、領収書や見積書、請求書といった定型フォーマットにある項目を指定して、データを抜き出すことを得意としている関数です。
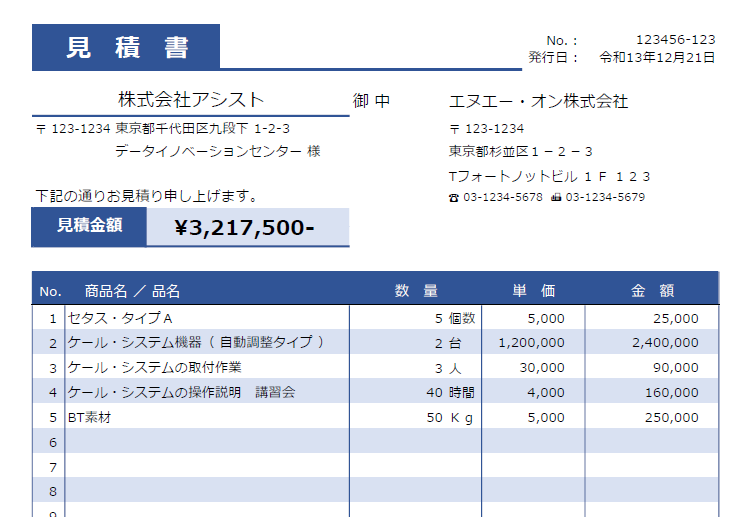
次の見積書を例にして、項目を抽出する方法を考えます。
|
画像5:サンプル見積書
AI_EXTRACT関数では、抽出する項目をそのまま指定する方法と、プロンプトで抽出する項目を指示することができます。
この見積書では、No、発行日、商品名/品名は項目名だけで指定することでそれぞれ抽出することができました。
2つの社名がありますが、これらには抽出するための項目名が存在していないため、どこにあるのか、位置を指定することで抽出することができました。こちらがそのSQLです。
select ai_extract(file =>
to_file('@internal_image_stage','sample_estimate.pdf'),
responseFormat =>['No','発行日','商品名/品名',
['見積金額','見積もり金額を数値型に変換した値は?'],
['見積先社名','見積もり書左側の社名は?'],
['見積元社名','見積もり書右側の社名は?'],
['数量','数量列にあるそれぞれの値は?'],
['単価','4列目にあるそれぞれの値を数値型に変換した値は?'],
['金額','5列名にあるそれぞれの値を数値型に変換した値は?']]);
そして、こちらがその出力結果です。JSON形式で出力されます。
{
"response": {
"No": "123456-123",
"単価": [
"5000",
"1200000",
"30000",
"4000",
"5000"
],
"商品名/品名": [
"セタス・タイプA",
"ケーブル・システム機器(自動調整タイプ)",
"ケーブル・システムの取付作業",
"ケーブル・システムの操作説明 講習会",
"BT素材"
],
"数量": [
"5 個数",
"2 台",
"3 人",
"40 時間",
"50 K g"
],
"発行日": "令和13年12月21日",
"見積元社名": "エヌエー・オン株式会社",
"見積先社名": "株式会社アシスト",
"見積金額": "3217500",
"金額": [
"5000",
"2",
"3",
"40",
"50"
]
}
}
このように定型フォーマットのドキュメントからピンポイントで抽出が必要な場合に有効な関数といえます。
AI_PARSE_DOCUMENT関数は、技術文章、論文など文章データの構造を保ったままデータ化することが得意な関数です。
※検証用データとして、こちらの論文「Revealing the Numeracy Gap: An Empirical Investigation of Text Embedding Models」(https://arxiv.org/pdf/2509.05691)に含まれる表形式の情報を参照(引用)しました。論文内のデータをサンプルとして引用し、検証を行います。
|
画像6:論文抜粋 出典: H. Wang et al., "Revealing the Numeracy Gap: An Empirical Investigation of Text Embedding Models", arXiv:2509.05691 (2025)
実行したSQLはこちらです。
with a as (select ai_parse_document(
to_file('@internal_image_stage',
'Revealing the Numeracy Gap An Empirical.pdf'),
{'mode': 'LAYOUT' , 'page_split': true}) as json_data)
select pages.index,pages.value:content::varchar as text
from a,
lateral flatten(input => a.json_data, path => 'pages') as pages;
AI_PARSE_DOCUMENT関数でMODEにはLAYOUTとOCRを指定することができますが、LAYOUTを指定すると文章の構造を保ったまま、Markdown形式で抽出することができます。
JSON形式で出力されるため、Flatten関数を使って構造化して出力しています。
その結果がこちらです。
|
画像7:AI_PARSE_DOCUMENT関数実行結果抜粋
このようにページ単位で行毎に分割されて出力されています。また、INDEXの5番目にあたる元のドキュメントのページは表が書かれていますが、Markdownで表示した結果がこちらになります。
|
画像8:AI_PARSE_DOCUMENT関数で抽出したデータをMarkdownで表現
このように元のドキュメントの表の構成を保ったまま、抽出することが出来ています。
今回、非構造化データからテキストを抽出してSnowflakeに格納する方法として3つのAISQL関数をご紹介しました。その他にも音声データをテキストとして抽出するAI_TRANSCRIBE関数などもあり、生成AIがSnowflakeの基盤の一部として活用しやすく提供されています。
次は、Snowflakeに蓄積したデータをいかに活用していくのか、どのようにデータドリブンに貢献していくのか、についてご紹介します。
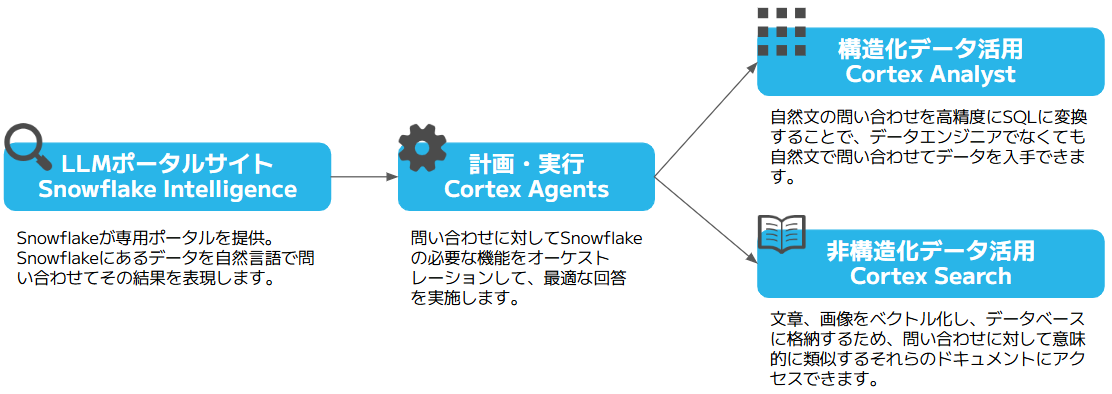
CortexはSnowflakeに蓄積しているデータに対して自然言語で検索したり、文章、画像をビジネスに活用するために必要な基盤を提供しています。
|
画像9:Snowflake Cortex全体像
今回はSnowflakeに蓄積した非構造化データを活用するために、Snowflake Intelligence、Cortex Searchをご紹介します。
Cortex AgentsとCortex Analystは次回ご紹介します。
Snowflake Intelligenceは、ChatGPTやGeminiのUIのようなSnowflakeが提供するチャットベースUIで、ついに10月にGA(一般提供開始)となりました。
利用者は自然言語で問い合わせることで、Snowflakeに格納しているデータにアクセスすることが可能です。
Snowflake Intelligenceからのすべてのアクセスは、Snowflakeのユーザーの認証情報(ロール、行アクセスポリシー、マスキングポリシー)が適用されるため、Snowflakeでセキュリティ設定を一元管理することが可能です。
|
画像10:Snowflake Intelligence画面
|
画像11:Snowflake Intelligence出力画面
Snowflake Intelligenceを利用するには、必要なCortex Agentsを登録することで、そのAgentsに関係付けされた様々な機能を利用することが可能です。
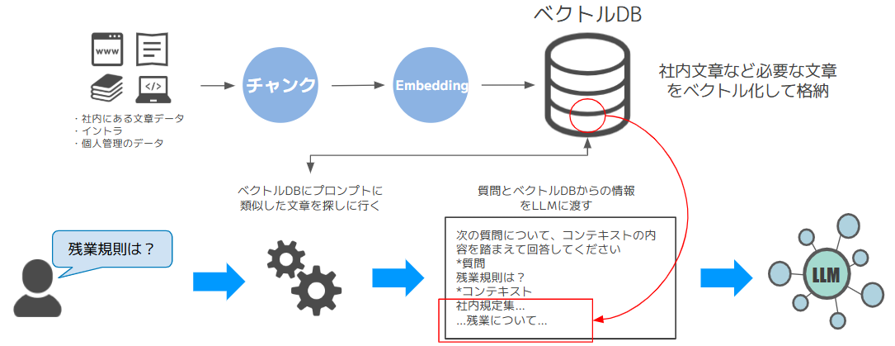
Cortex SearchはSnowflake上でRAGを簡単に実装することが可能な機能です。RAGは生成AIモデルが学習していない社内ドキュメントなど非共有の情報を生成AIで有効に活用することができるアーキテクチャです。
社内にあるような文章をベクトル化してデータベース化しておきます。利用者からのプロンプトを元にして意味の近い文章を検索し、その結果を元々のプロンプトとともに生成AIモデルに渡すことで、その文章も利用しながら回答を考えることができます。
|
画像12:RAGアーキテクチャ
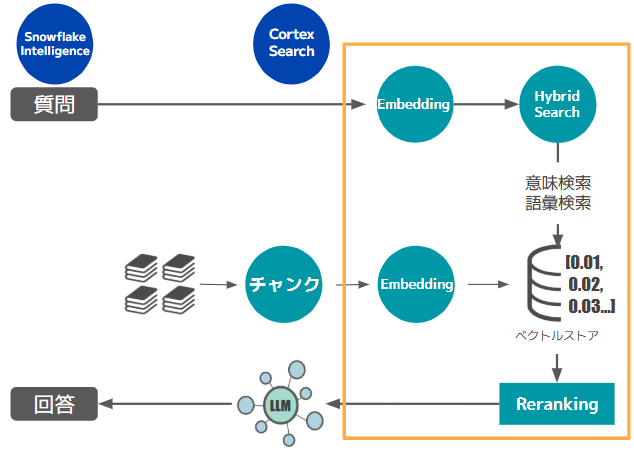
Cortex SearchはこのRAGアーキテクチャにおける、文章データのエンベディングとベクトルデータのメンテナンス、利用者からのプロンプトとベクトル化されたデータの検索時のチューニング、インデックスの更新を実施するマネージドサービスです。
|
画像13:Cortex Searchアーキテクチャ
今回は、Snowflake Intelligenceがどんな役割を果たすのか体感していただくため、Cortex Knowledge Extension (CKE)の中から、誰でも利用できるように公開されているSnowflake DocumentationをSnowflake Intelligenceに登録していきます。 まずは、Cortex Knowledge Extensionについて少しご紹介します。
Cortex Knowledge Extension(CKE)は、Snowflake Marketplaceで共有されているCortex Search Serviceです。従来Marketplaceで公開されているデータは、構造化されたデータで、利用するためには、自社のデータとリレーションを定義して関係づける必要がありました。CKEは、公開されているCortex Search Serviceを自社のCortex Agentsに関係付けすれば、自然言語で公開されているデータに対してアクセスできるようになるため、データ活用がより容易に実現することが可能になりました。
|
画像14:Cortex Knowledge Extension
今回はSnowflakeから提供されているSnowflake Documentationを利用できるようにします。
Snowflake Documentationは、公式のSnowflakeドキュメントの内容をCortex Search Service として提供されているため、チャットボットや生成AIアプリケーションに簡単に統合することが可能です。
|
画像15:Snowflake Documentation紹介画面
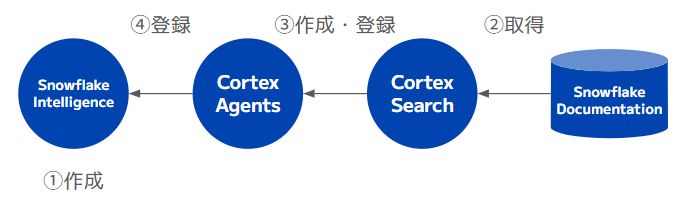
それでは、CKEで公開されているSnowflake DocumentationをSnowflake Intelligenceから利用するアーキテクチャを構築していきます。
構成は次の通りです。
MarketplaceからSnowflake Documentationを取得し、順番に作成・登録をしていきます。
|
画像16:構築フロー
Snowflake Intelligenceオブジェクトを作成し、そのオブジェクトにエージェントを登録していくことで、Snowflake Intelligenceからそのエージェントを利用することが可能になります。
最初にSnowflake Intelligenceオブジェクトを作成しておきます。Snowflake Intelligenceオブジェクトは、アカウント内でSnowflake Intelligenceで使用されるすべてのエージェントを管理するための単一のオブジェクトです。アカウント内に作成できるSnowflake Intelligenceオブジェクトは1つだけです。
そのため、まずはSnowflakeのトライアル環境などで新規に作成して検証することをお勧めします。
次のSQLで作成します。
また、Snowflake Intelligenceは、現在は国内リージョンでは対応していない生成AIモデルを使用するため、クロスリージョン推論を有効化しておきます。
use role accountadmin;
-- Snowflake Intelligenceオブジェクトの作成
CREATE SNOWFLAKE INTELLIGENCE SNOWFLAKE_INTELLIGENCE_OBJECT_DEFAULT;
-- クロスリージョン推論を有効化
ALTER ACCOUNT SET CORTEX_ENABLED_CROSS_REGION = 'ANY_REGION';
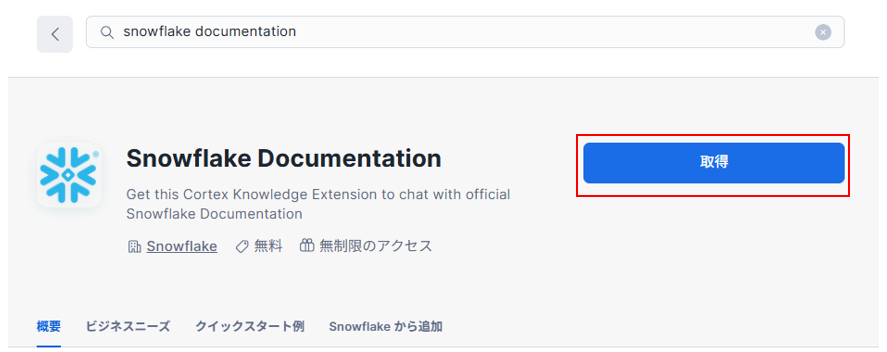
まずは先ほどのSnowflake Documentationを取得します。
MarketplaceからSnowflake Documentationを検索して「取得」をクリックします。
|
画像17:Snowflake Documentation取得画面
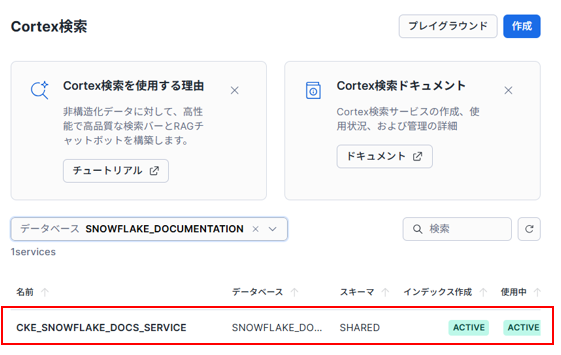
取得が完了したら、データベースエクスプローラから「SNOWFLAKE_DOCUMENTATION」のデータベースが共有されているはずです。また、Cortex Searchの画面から確認することも可能です。Snowsightの左ナビゲーションから「AIとML」>>「Cortex検索」を選択し、データベースから「SNOWFLAKE_DOCUMENTATION」を選択してください。
「CKE_SNOWFLAKE_DOCS_SERVICE」が存在していれば、設定できています。
|
画像18:Cortex Search確認画面
次にCortex Agentsを作成します。
Cortex Agentsはデータベースオブジェクトですので、格納する任意のデータベースとスキーマを作成してください。ここでは、「cortex_db」と「agents_sc」としておきます。
use role sysadmin;
create database cortex_db;
create schema cortex_db.agents_sc;
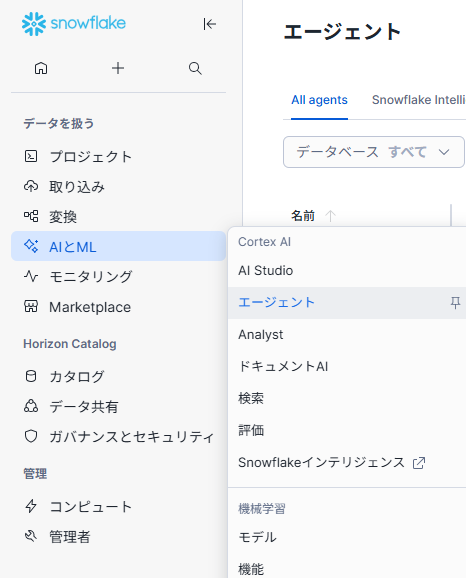
次にSnowsight上の左ナビゲーションメニューから「AI&ML」>>「エージェント」を選択します。
|
画像19:Cortex Agents画面
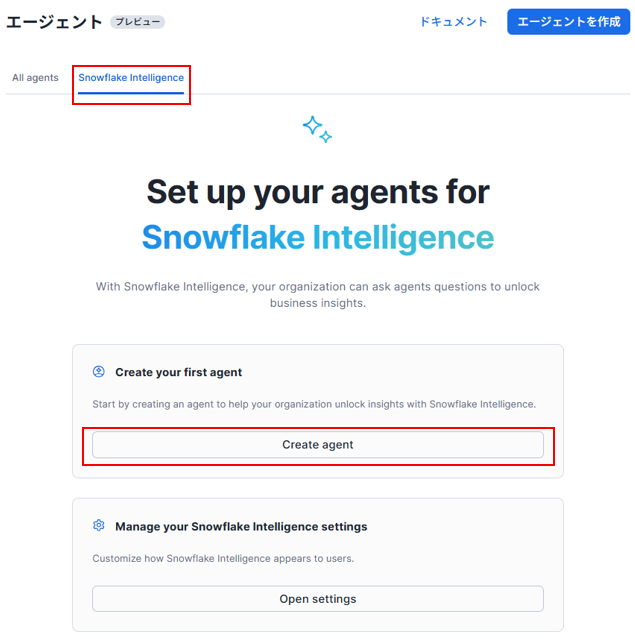
画面右側にエージェントの画面が表示され、その中の「Snowflake Intelligence」のタブを選択し、「Create agent」をクリックします。Snowflake Intelligenceオブジェクトがまだ存在していない場合には自動的に作成されます。
|
画像20:Snowflake Intelligenceにエージェントを追加
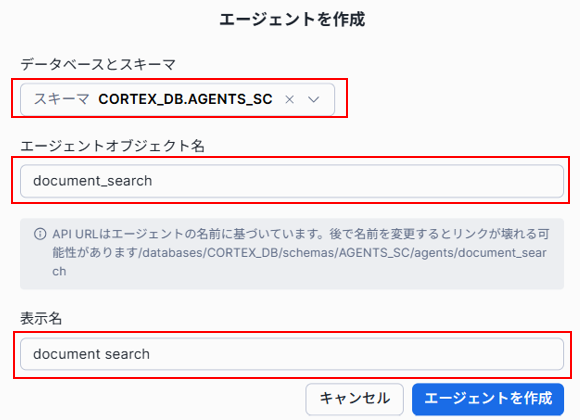
エージェントの作成では、「データベースとスキーマ」から先ほどエージェント用に作成したデータベースとスキーマを選択してください。表示されない場合、使用しているロールの確認を行ってみてください。ここでは先ほど作成した、「CORTEX_DB.AGENTS_SC」としています。
エージェントオブジェクト名と表示名も任意の文字列を指定してください。表示名は後からでも変更可能です。
|
画像21:エージェント作成
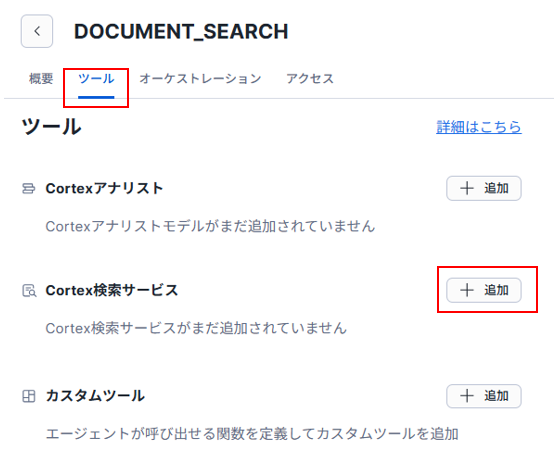
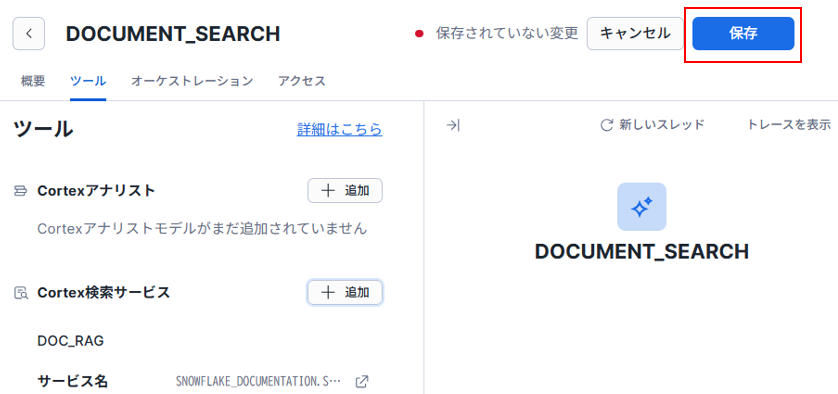
引き続き作成したエージェントの設定が可能ですので、「ツール」タブをクリックして、次の画面で「Cortex検索サービス」の「追加」をクリックしてください。
|
画像22:エージェントにCortex Searchを追加
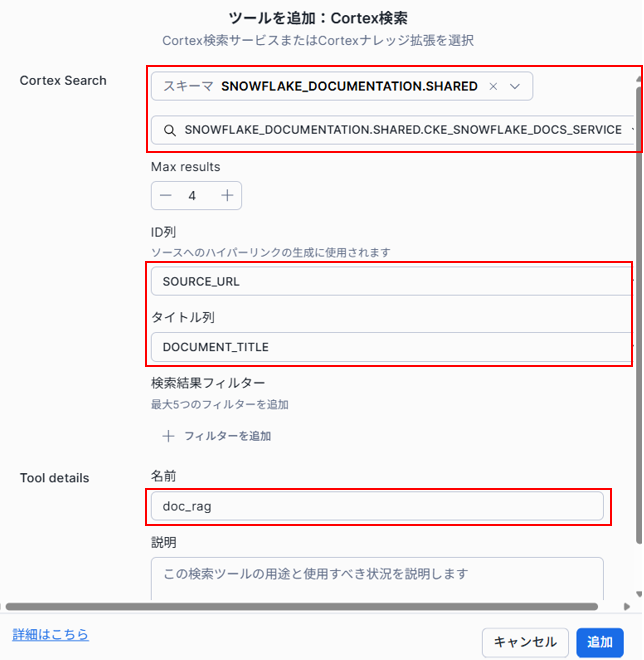
追加するCortex Search Serviceの情報を登録していきます。今回はCKEのSnowflake DocumentationのCortex Search Serviceを登録していきますので、スキーマは、「SNOWFLAKE_DOCUMENTATION.SHARED」を選択します。
スキーマの選択が正しい場合、その下のCortex検索サービスには、「SNOWFLAKE_DOCUMENTATION.SHARED.CKE_SNOWFLAKE_DOCS_SERVICE」が選択できるようになっているはずです。
ID列、タイトル列は今回は任意で設定してください。名前も任意の名前を設定してください。
|
画像23:追加するCortex Search情報を登録
設定が終わったら、Cortex検索サービスのところに追加したサービスが存在していることを確認し、必ず画面右上の「保存」をクリックしてください。この操作は忘れがちなので、気を付けてください!
|
画像24:登録したツールをCortex Agentsに保存
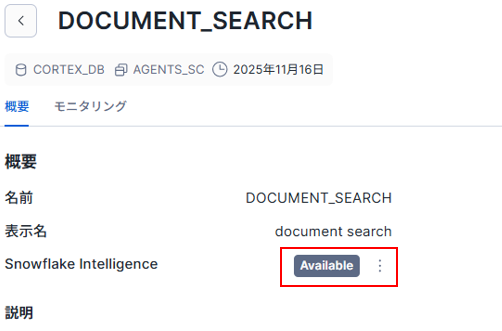
保存した後、同じ画面のエージェント名の左の 「<」をクリックするか、エージェント画面から作成エージェントを選択して、次の画面の「Snowflake Intelligence」のステータスが、「add agent」だった場合はクリックして、「Available」としてください。
|
画像25:Snowflake Intelligenceでエージェントを有効化
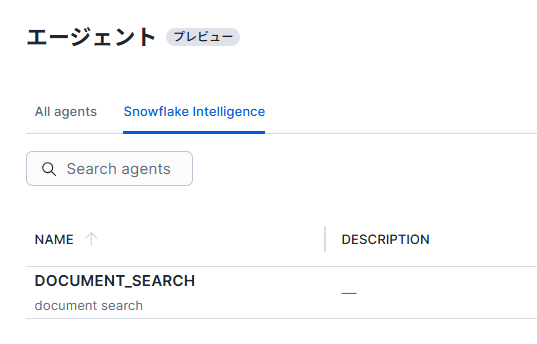
エージェントの画面に戻り、「Snowflake Intelligence」のタブをクリックして、作成したエージェントが表示されている場合、Snowflake Intelligenceにエージェントを登録できている状態です。
|
画像26:エージェント登録の確認
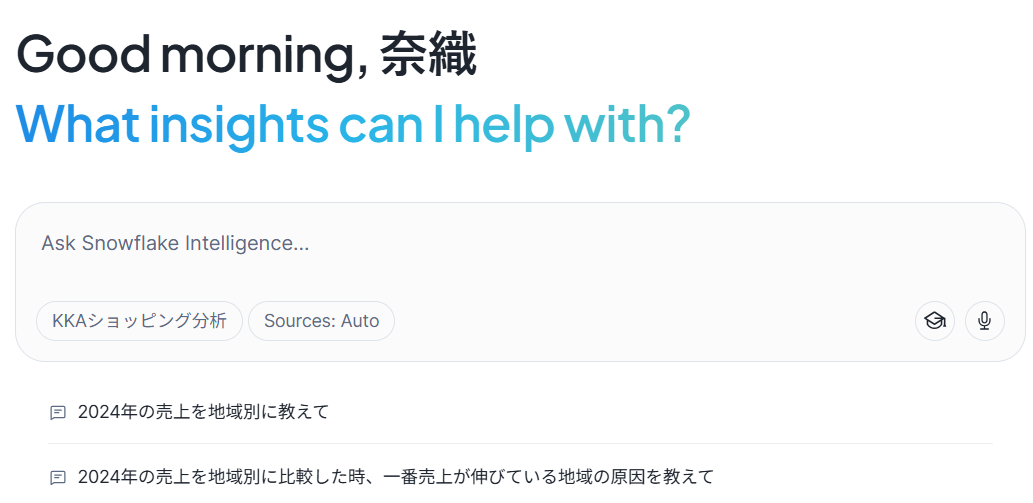
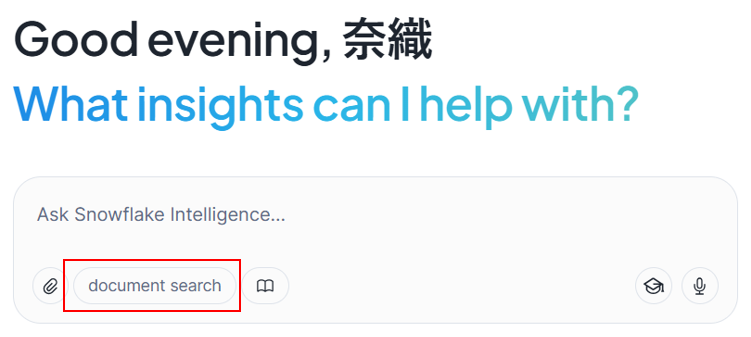
いよいよSnowflake Intelligenceを利用してみます!
Snowsightの左メニューから「AIとML」>「Snowflakeインテリジェンス」を選択してください。
再度ログインを実施し、スタート画面に先ほど作成したエージェント名が表示されていれば成功です!
|
画像27:Snowflake Intelligence問い合わせ画面
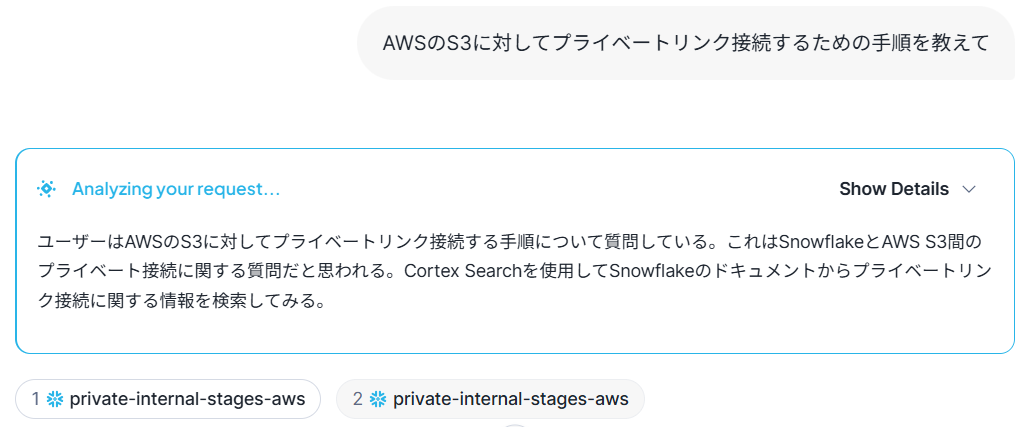
Snowflakeに関する問い合わせを実施してみると、Cortex Searchを利用する、となっていました。
|
画像28:Snowflake Intelligence思考画面
今回は、Snowflakeの生成AIの機能として、AISQL関数と、Snowflake Intelligence、Cortex Searchをご紹介しました。
Snowflakeの環境があれば、いかに簡単にデータを活用できるのかご理解いただけたかと思います。しかし、生成AIはあくまでも手段ですので、どこにその手段を活用していくと効果が得られるのか、ビジネスの課題と手段を紐づける必要があります。弊社では、お客様が描く基盤の姿を整理させていただき、その時のアーキテクチャをベースとした基盤作りのご提案をワークショップという形でご提供しております。
次回は、Snowflakeの残りの機能と弊社サービスも合わせてご紹介します。
【全2回】本記事は、全2回にわたるシリーズ記事の前編(PARTⅠ)です。 後編もご覧ください。
▼PARTⅡはこちら
弊社ではお客様のご要件や目指したいゴールに合わせて、Snowflakeの最適な活用方法をご支援し、伴走いたします。Snowflakeの導入をお考えのお客様は、ぜひ弊社までお気軽にご相談ください。以下のページより30日間の無料トライアルを開始いただけます。

|
|---|
また弊社では、データ活用業務を担うユーザー部門向けにSQLの入門講座を用意しています。多くの練習問題を通して実用的なSELECT文を学べるため、ユーザー部門の方はもちろん、SQLを一から学びたいIT担当者の方にもおすすめの講座です。DWHからのデータ抽出について学びたい方は、ぜひお申し込みください。

|
|---|

|
|---|
1998年入社。Oracle Databaseエンジニアを経て、Hadoopビジネス検討立ち上げや、パートナーとVMware、Nutanixなど仮想基盤の提案、提供を実施。その後カスタマーサクセスを...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。

【初心者向けの解説記事】Snowflakeは何がすごいのか、Snowflake Squadの認定スペシャリストが特長やアーキテクチャをわかりやすく説明します。

データ活用は「予測」から「アクション」へ。Snowflake×アシストが共催したセミナーの模様をレポートします。AIにビジネスを正しく理解させる鍵となる「セマンティックモデル」の重要性や、Snowflakeを用いた実装戦略など、当日語られた核心部分を凝縮して解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

