






- Snowflake
SoRとSoIで考えるデータ基盤の作り方 ― AI Readyを目指すためのセミナー見どころ紹介!
2026年7月24日開催のセミナー「AI活用の前に整えるべきデータ活用基盤とは」では、SoR(守り)とSoI(攻め)を分離し、既存の基幹系を生かしてAI Readyな基盤を構築する方法を解説。OracleとSnowflakeの役割分担や製品選定のヒントを知りたいデータベース技術者・アーキテクト必見です。
![]()






|
|
【全2回】本記事は、全2回にわたるシリーズ記事の後編(PARTⅡ)です。
前編では基礎となるアーキテクチャや設定方法について詳しく解説しています。本記事(PARTⅡ)の内容をより深く理解いただくために、まずは前編からご覧いただくことをおすすめします。
▼前編はこちら
前回は、Cortex Knowledge Extension で公開されている Snowflake Documentation を Cortex Search に登録して SnowflakeInteligence から、自然文で問い合わせする方法をご紹介しました。
今回はSnowflakeから自然文でデータに問い合わせをする方法をご紹介します。
Index
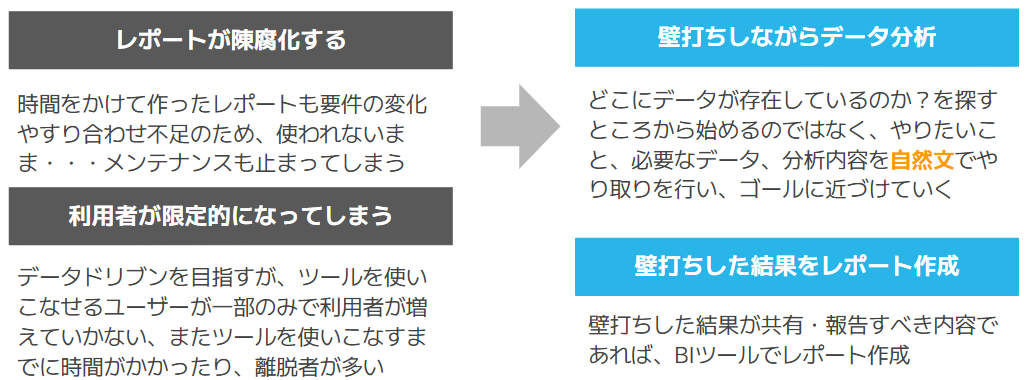
データ分析基盤の役割は、データを収集・蓄積するだけでなく、そのデータからビジネスにフィードバックして初めて価値が生まれます。そのためには、利用者が意思決定に必要な情報を抽出する必要がありますが、現状、次のような課題をお聞きします。
・レポート作成のリードタイムと陳腐化
利用者の多くはSQLスキルを持ち合わせていないため、IT部門が要件をヒアリングしてレポートを作成します。しかし、ビジネスの変化は激しく、時間の経過とともに陳腐化し、使われないレポートが蓄積されてしまうケースが散見されます。
・ツールの利用が一部のヘビーユーザーに偏る
分析ツールが「分析が得意な人」や「ITリテラシーが高い人」だけのものになり、全社的なデータ活用が進まないという課題もよくお聞きします。
このような課題に対して、いきなり分析ツールを提供してレポート作成から始めるのではなく、ChatGPTやGeminiのようなチャットベースのUIを入口として、日常会話の延長でAIと壁打ちをしながら分析を深堀し、要件が固まった段階でIT部門に依頼してレポートを作ってもらう。
このサイクルを回すことで、より利用者の範囲を広げつつ、利用者主導で「真に必要なレポート」の具体化が進むため、データドリブンの裾野を確実に広げることができると考えています。
|
画像1:データ分析の課題と解決策
この時、自然言語をデータベースが理解できる言語であるSQLに変換する必要がありますが、これを「text to SQL」と呼びます。以前から存在していた技術ですが、生成AIを活用することで、性能が飛躍的に向上しています。
このように、text to SQL は、ゲームチェンジャーになりうる非常に強力な技術ですが、個人的に次の2点が気になりました。
これらは、後ほど紹介するセマンティックモデルやエージェントの機能によって実現されています。
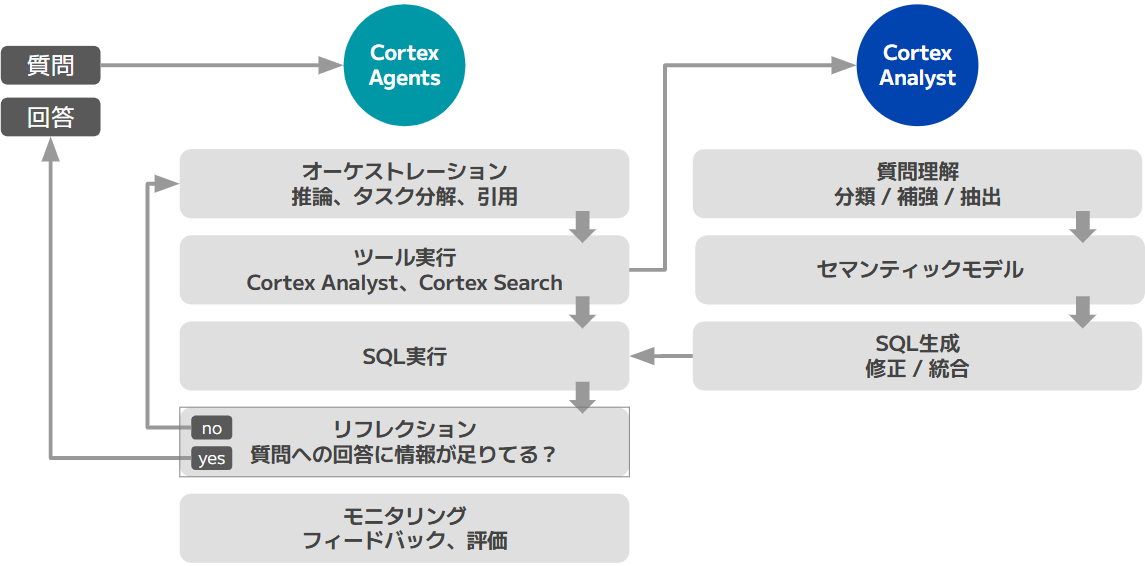
PARTⅠでもSnowflake Cortexの全体像をご紹介しましたが、Cortex Analystが、自然文をSQLに変換する役割を担います。Cortex Agentsと組み合わせることで、より品質が高く、利用者にとって有益なSQLを作り上げてくれます。ここでは、Cortex AgentsとCortex Analystを組み合わせて考えています。
|
画像2:CortexAgentsとCortex Analystの連携
Cortex Agentsは、Snowflake Intelligence、もしくはStreamlitなどからREST API経由でリクエストを受け取ることが可能です。
Cortex Agentsは、次の4つのプロセスを実行していきます。
ここでは、1.オーケストレーション、2.ツール実行、3.リフレクションの3つのプロセスのふるまいを確認していきます。
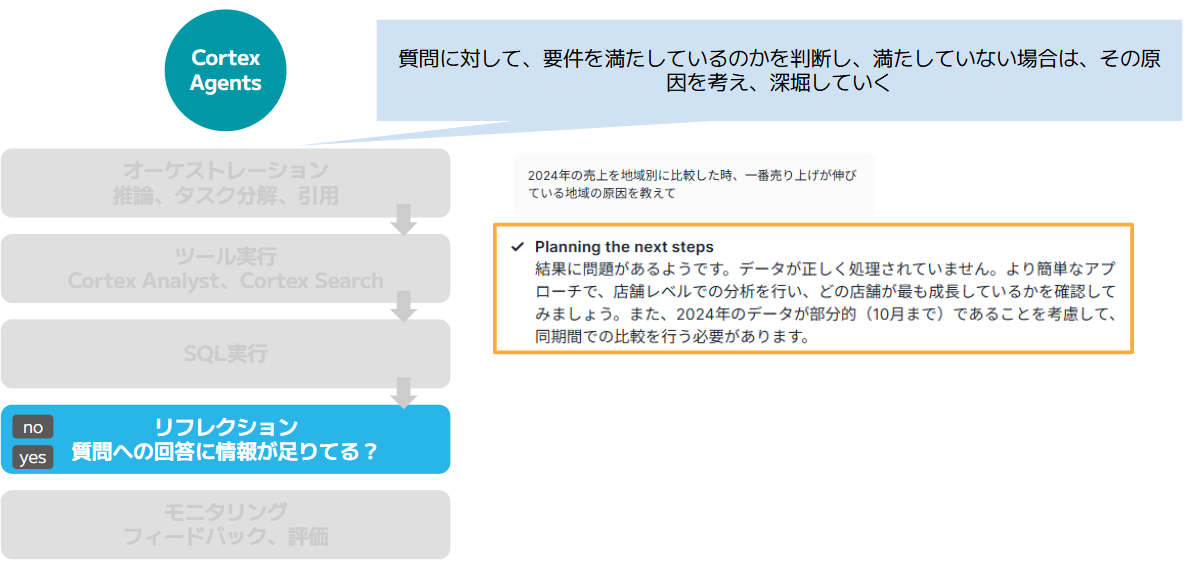
まず最初に受け取った問い合わせを解析して、その問い合わせを解決するためにいくつかのタスクに分解し、それぞれのタスクを解決するために必要なツールを検討します。
下の画像では、「2024年の売り上げを地域別に比較し、一番売り上げが伸びている地域の原因を教えて」とリクエストを投げていますが、それに続く文章を確率的に言葉を並べて作り上げるだけでは、利用者の求めている回答にはなりません。
Cortex Agents は、そのリクエストに答えるために、4つのステップに分解し、その中でデータにアクセスする必要があるタスクに対して、セマンティックモデルを利用してデータベースからデータを取得する、と計画を立てていることがわかります。
|
画像3:Cortex Agentsによるオーケストレーション
計画を立てた後に、タスクを解決するために必要なツールを実行していきます。
Cortex Agentsでは、現在、3種類のツールを登録することが可能です。
・Cortex Search:非構造化データ検索(PARTⅠでドキュメント検索に使用)
・Cortex Analyst:構造化データ検索(SQL生成)
・カスタムツール:事前に作成したストアドプロシジャーやUDF
Cortex SearchはPARTⅠでCKEにあるSnowflake DocumentationのCortex Searchを登録しました。カスタムツールは事前に作成しておいたストアドプロシージャとユーザー定義関数を利用することが可能です。
今回はCortex Analystを登録しているため、登録されているCortex Analystにリクエストを渡して、Cortex Analystで生成されたSQLがCortex Agentsに返されます。Cortex AnalystはSQLを生成するだけで実行しないため、Cortex AgentsでSQLを実行し、データベースにアクセスを行っています。Cortex Analystの処理内容は後ほどご紹介します。
|
画像4:Cortex Agentsによるツール実行
タスクが完了すると、Cortex Agents自身がリクエストの要件を満たしているのか、答え合わせを行います。問題なければその内容で返信を行い、問題があれば、再度推論を繰り返します。このリフレクションによって、回答の品質を向上させています。
|
画像5:Cortex Agentsによるリフレクション
このようにCortex Agentsは、リクエストを受け取り、リクエストをタスクに分解し、それぞれのタスクを解決するためのツールを実行し、最後に自分自身で答え合わせを行って、品質の高い回答を生成することができます。
|
画像6:Cortex Agents処理フローまとめ
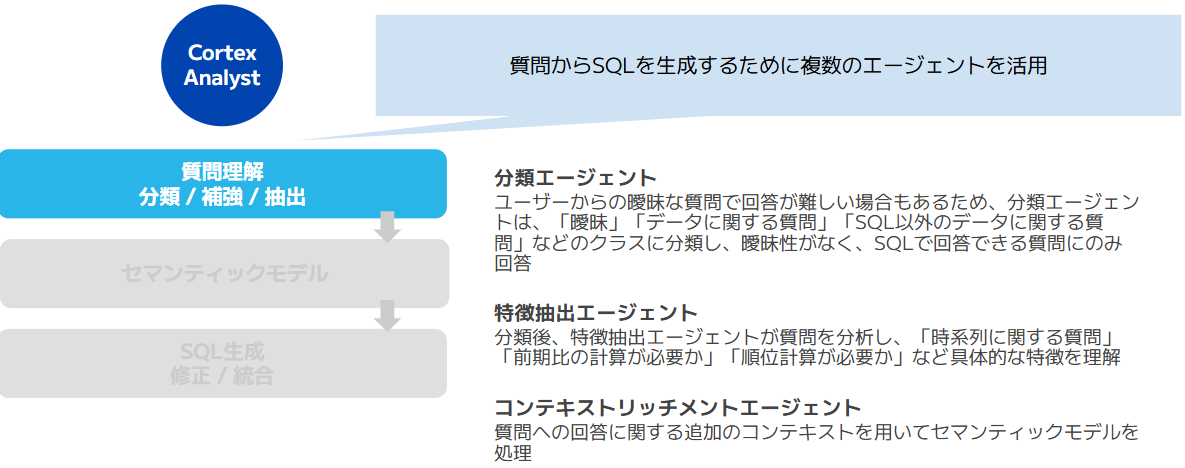
Cortex Analystは、自然言語でデータベースに問い合わせすることができる機能で、内部で様々なエージェントによってSQLを生成します。Cortex Agentsが利用者からの問い合わせをタスク分解し、Snowflake内のデータにアクセスが必要と判断されるとCortex Analystにその処理が渡されて、SQLを生成します。
Cortex Agentsから受け取ったリクエストからSQLを生成するために複数のエージェントによってリクエストを解読していきます。
SQLでの回答が難しい内容が含まれていないか、どのような特徴を持つクエリか(集計、フィルタリングなど)を特定し、SQLを生成するために必要な情報を抽出していきます。
|
画像7:Cortex Analystによる質問の理解
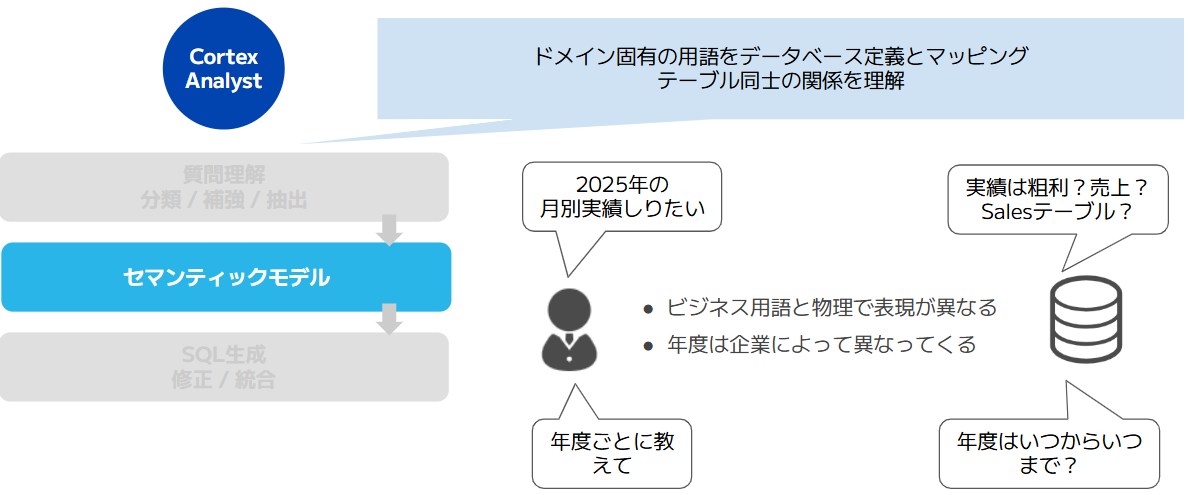
リクエストからSQLの生成計画を立てたとしてもどのデータにアクセスすれば要件をみたすのかを特定する必要があります。しかし、ユーザーは、データベースオブジェクトの名称を理解しているわけでないため、ユーザの言葉とデータベース内の定義との乖離を埋めたり、テーブル同士の関係性を考慮するプロセスが必要です。
|
画像8:セマンティックモデルの役割
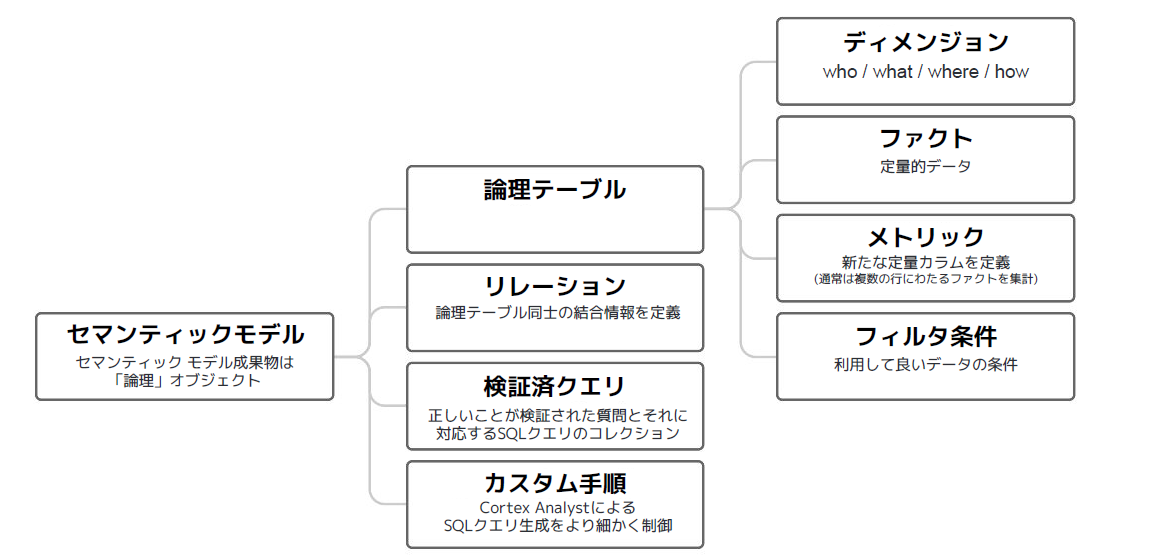
セマンティックモデルは、ディメンションテーブルとファクトテーブルが持つ「データの意味」や、「テーブル同士の関係性(リレーション)」を定義したものです。このセマンティックモデルとリクエストを生成AIに渡すことで、生成AIがデータモデルを意識しながら、SQLを生成することが可能です。
セマンティックモデルは、AIのための辞書としての役割を持ち、今後AI Readyを進めていくためには必要不可欠なモデルと言えます。
|
画像9:セマンティックモデル構成
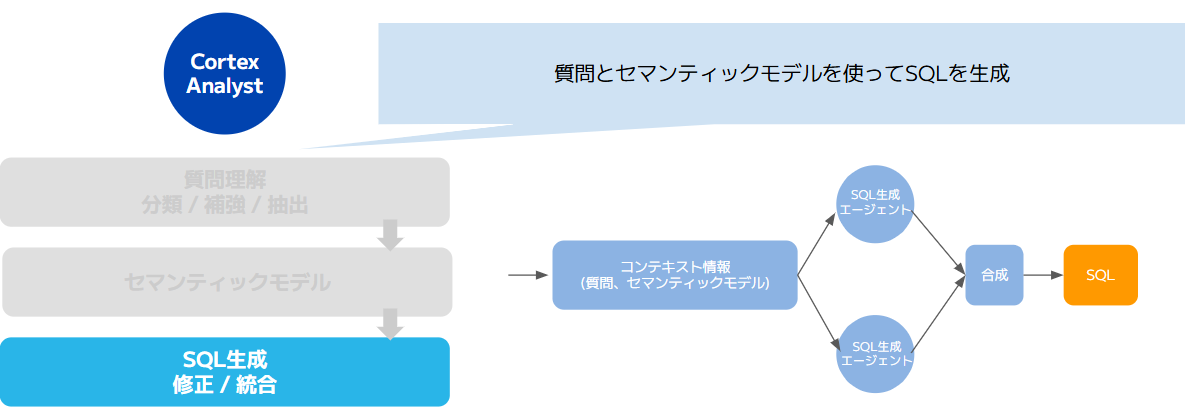
ここまでの工程で洗練されたリクエスト内容とセマンティックモデルを使って、複数の生成AIがエージェントとして、SQLを生成します。生成AIによってそれぞれ得意とする領域があるため、複数のエージェントが生成したSQLをマージすることで、堅牢なSQLが期待できます。
|
画像10:Cortex AnalystによるSQL生成
2回にわたって、Snowflake Intelligenceの魅力をお伝えしました。Snowflakeはデータレイク、データウェアハウスとしての役割だけでなく、蓄積されたデータを生成AIで「使える情報」に変えるプラットフォームへと進化しています。とはいえ、「社内にある課題をどうシステム化すべきか」「どこから着手し始めていくべきかわからない」、といったケースも多いかと思います。
弊社では、お客様のあるべき姿をヒアリングしたうえで、その課題がSnowflakeと生成AIによってシステム化できそうか、どこからPoCを始めていくべきか、を言語化するサービスも提供しております。
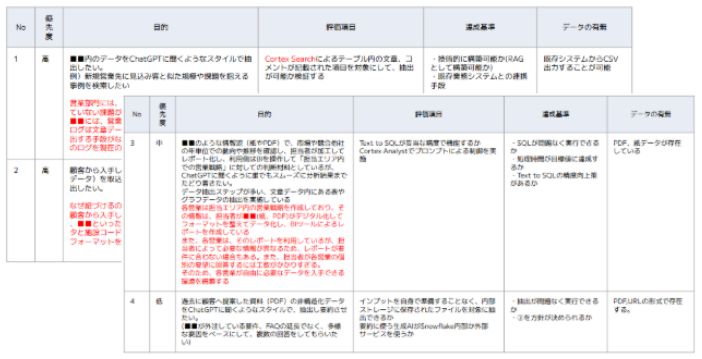
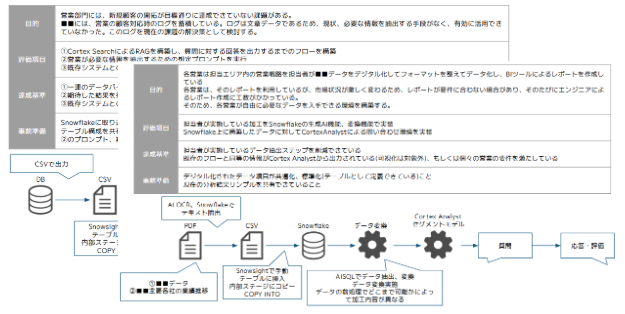
1:要件定義
最初にお客様が実現したい内容を記載頂き、目的、評価項目、データの所在などをブレストを行いながら明確にしていきます。中には、実装が困難なケースもありますので、この作業で、実現可能性も判断することができます。
|
画像11:課題整理シート
2:データフロー設計
明確にした項目ごとに、Snowflakeでどのように実装できるのかを簡単なデータフローを作成し、お客様に具体的な実装のイメージを共有することで、PoCでの実施内容が明確になります。
|
画像12:PoC要件整理図
Snowflakeの生成AIに関するPoC支援や、データ活用基盤の「あるべき姿」を策定するワークショップも提供しております。 Snowflakeを中心とした基盤作りにおいて課題をお持ちでしたら、ぜひお気軽にお問い合わせください。
本記事で解説したSnowflake Intelligenceを、実際のビジネス環境でどう活用するのか?
その実装論をセミナーで深掘りし、みなさまと一緒に「Agentic Analytics基盤」のあり方を考えるイベントを開催します!
Snowflakeとシームレスに連携する分析インターフェースを組み合わせ、「人間とAIが対話しながら意思決定する」新しいアーキテクチャについて、実演を交えてご紹介します。 アーキテクチャ選定に悩む方や、Snowflake Intelligenceの具体的な活用イメージを掴みたい方は必見です。
|
|
弊社ではお客様のご要件や目指したいゴールに合わせて、Snowflakeの最適な活用方法をご支援し、伴走いたします。Snowflakeの導入をお考えのお客様は、ぜひ弊社までお気軽にご相談ください。以下のページより30日間の無料トライアルを開始いただけます。

|
|---|

|
|---|
1998年入社。Oracle Databaseエンジニアを経て、Hadoopビジネス検討立ち上げや、パートナーとVMware、Nutanixなど仮想基盤の提案、提供を実施。その後カスタマーサクセスを...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

2026年7月24日開催のセミナー「AI活用の前に整えるべきデータ活用基盤とは」では、SoR(守り)とSoI(攻め)を分離し、既存の基幹系を生かしてAI Readyな基盤を構築する方法を解説。OracleとSnowflakeの役割分担や製品選定のヒントを知りたいデータベース技術者・アーキテクト必見です。

【初心者向けの解説記事】AIとBIの違いと使い分けを解説。AIが得意な分析・予測と、BIが担う検証・意思決定支援の役割を整理し、SnowflakeとSigmaで実現できるデータ活用の進め方を紹介します。

【初心者向けの解説記事】Snowflakeは何がすごいのか、Snowflake Squadの認定スペシャリストが特長やアーキテクチャをわかりやすく説明します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

