



















- AWS
AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説
この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します
![]()






|
|
~ 坂本プロが現地からお届けします ~
毎年数多くの新機能が発表される、AWSのre:Inventが今年も実施され全ての日程が終了しました!
弊社(アシスト)の社員も、イベント会場であるラスベガスへ飛んできました。現地から仕入れたばかりの新機能情報の速報をデータベースとデータ分析系を中心にお届けする、今回は2回目です。
執筆は、2022 APN AWS Top Engineersにも選出された坂本雄一が担当します。
※2回目は後半(現地11/30、12/1)で入手できた情報の範囲を対象としています。
[連載一覧] re:Invent参加レポート
・速報!AWS re:Invent 2022で発表されたデータベース&データ分析系新機能まとめ(Vol.1)
・速報!AWS re:Invent 2022で発表されたデータベース&データ分析系新機能まとめ(Vol.2) ★本記事
・AWS re:Invent 2022参加レポート(番外編)
|
|
Index
PostgreSQLには、独自開発したスクリプトを拡張機能として組み込む機能が備わっています。しかし、Amazon RDS、Amazon AuroraのPostgreSQLでは、独自開発の拡張機能は組み込むことは出来ず、事前に用意された拡張機能だけが利用可能でした。本新機能のリリースによって、データベース管理者は拡張機能をインストールするユーザーとそれを実行するアクセス許可を制御できるようになり、アプリケーション開発者は自ら作成した拡張機能を組み込むことが可能となりました。
※アジアパシフィック (東京、大阪)共に利用可能です。
公式)
https://aws.amazon.com/jp/blogs/aws/new-trusted-language-extensions-for-postgresql-on-amazon-aurora-and-amazon-rds/
|
|
Amazon DocumentDBは、MongoDB互換のフルマネージメント型ドキュメントデータベースです。今回リリースされたElastic Clustersでは、スケールアウトによる書込み/読込み性能の向上、およびペタバイト規模のストレージ拡張が可能です。通常のクラスタでは、スケールアップのみ実施可能かつストレージサイズの上限が64TBでした。Elastic Clustersを利用することで、スケーリング時のアプリケーション影響の最小化や大規模ワークロードへの対応が期待できます。
※本記事記載時は、アジアパシフィック (東京、大阪)は未対応です。
公式)
https://aws.amazon.com/jp/blogs/aws/announcing-amazon-documentdb-elastic-clusters/
|
|
データベース自体の新機能ではないのですが、脅威検出サービスであるGuardDutyの保護対象に、RDSが加わったためご紹介します。
本機能を有効化すると、GuardDutyはデータベースへのログインアクティビティを監視し、独自の機械学習アルゴリズムに基づき疑わしいログインを検出します。現在検出対象にできるデータベースはAuroraのみですが、今後その他のRDSに対応することも楽しみです。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-guardduty-rds-protection-preview/
|
|
DWH(データウェアハウス)サービスであるAmazon Redshiftも、数多くの新機能が発表されました!
そちらについては、以下の「データ分析系新機能」にてまとめてご紹介します。
RDSで提供されていたマルチAZ機能が、ついにRedshiftでも提供されます。2020年に発表された「クラスタ再配置」機能は、Redshiftが稼働しているAZに障害が発生した場合に自動的に異なるAZでRedshiftクラスタを再起動してくれるものです。ただし、一からクラスタの起動を行うため、AZの切替完了までに時間を要しました。今回のマルチAZ機能はActive-Active構成のRedshiftクラスタを稼働させ、どちらのクラスタからもRead-Writeが可能、かつ1つのクラスタがダウンしても残りのクラスタで継続して処理を行うことができます。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-multi-az-preview-ra3-clusters/
|
|
従来Amazon Redshiftにデータをロードするためには、何かしらのツールを必要としていました。しかし、本機能を利用すると、指定したAmazon S3にファイルを配置するだけで自動的にデータをAmazon Redshiftにロードできるようになりました。シンプルですが、以前から要望の多かった機能です。今回のre:Inventでは「zero-ETL」というAWSの方向性が示されましたが、本機能のリリースもその一環と言えそうです。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-supports-auto-copy-amazon-s3/
|
|
ユーザーがRedshift内の機密データへSQL処理した際、データをマスキングして返すことが可能となりました。Redshift内のデータやSQLそのものに変更を加えることなく、設定ポリシーに従って見せたくないデータを自動的にマスキングできます。Redshiftは、列レベルのセキュリティ保護機能等は既にサポートされていますが、実装が簡単で便利な機能がさらに1つ追加されました。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-support-dynamic-data-masking-preview/
|
|
Redshiftには、複数クラスタ間でデータを共有するdata sharing機能があります。data sharing機能を利用し数多くのクラスタ間でデータを共有すると、誰がどのデータにアクセスしているかの追跡が困難になるという課題がありました。しかし、AWS Lake Formationを用いてRedshiftのdata sharingを使った複数クラスタのデータを一元的に管理し、きめ細かなアクセス制御を行えるようになりました。今後、data sharingによるデータ共有がさらに進むと思われますが、その際の運用、セキュリティ維持コストを大きく削減する機能として期待できます。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-data-sharing-centralized-access-control-lake-formation-preview/
|
|
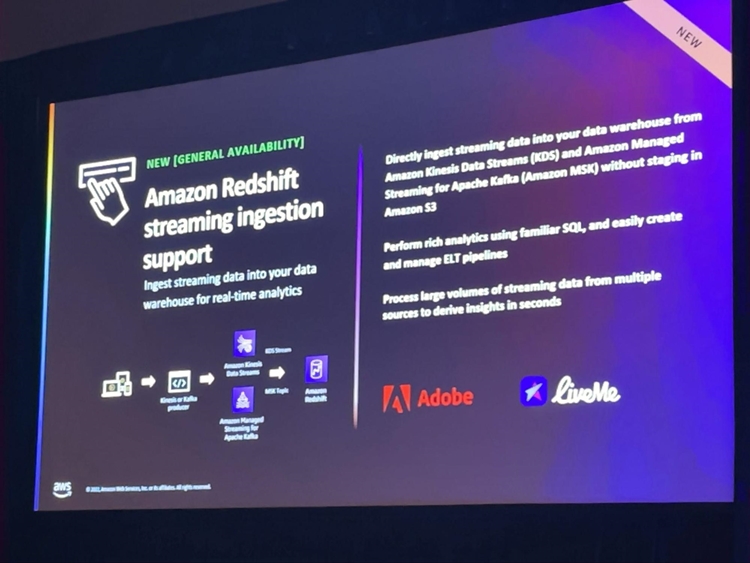
これまで、Amazon Kinesis Data Streams (KDS) やAmazon Managed Streaming for Apache Kafka (MSK) のストリーミングデータをRedshiftに取り込むには、S3に一旦データを配置してデータロードを行う必要がありました。しかし、今回の新機能によって毎秒数百メガバイトのストリーミングデータをRedshiftに直接取り込むことが可能となりました。これによって、Redshiftへの取り込みフローが簡素化されることはもちろん、ストリーミングデータをすぐにクエリ分析できるようになりました。
※アジアパシフィック (東京、大阪)共に利用可能です。
公式)
https://aws.amazon.com/jp/about-aws/whats-new/2022/11/amazon-redshift-real-time-streaming-ingestion-kds-msk/
|
|
Amazon Athenaは、データベースではなくS3等のデータにSQL処理できるサービスです。本新機能がリリースされたことで、SQLだけではなくAmazon AthenaでJupyter Notebookを利用し 、PySparkのアプリケーションを構築、実行できるようになりました。Sparkの設定、管理はAmazon Athenaで行われるため、管理負荷なくSparkで高速処理を実行できることが魅力です。
※本記事記載時は、アジアパシフィック (東京、大阪)は未対応です。
公式)
https://aws.amazon.com/jp/blogs/aws/new-amazon-athena-for-apache-spark/
|
|
今回のre:Inventでは、SageMakerの新機能が数多く発表されました。その中から代表して、Keynoteでも紹介された「Geospatial ML」をご紹介します。本機能によって、地理空間データを使ったML(機械学習)モデルの構築や学習、デプロイを簡単に行えるようになります。また、AWS上でオープンデータが提供されるため、そのデータを利用したテストも行えます。Keynoteでは、本機能を利用した「洪水発生時の災害予測」のデモを見せてくれたのが印象的でした。
参考)
https://aws.amazon.com/jp/blogs/aws/preview-use-amazon-sagemaker-to-build-train-and-deploy-ml-models-using-geospatial-data/
|
|
データレイクのデータ品質を保つことは非常に大変で、多くのコストがかかります。本機能は、そのコストを大幅に削減することを目的としています。本機能では、データレイク内の列に存在するNULL以外のデータや一意のデータ数の割合などを自動的に分析し、データ品質を保つルールを推奨してくれます。また、運用を開始するとルールに従ってデータ品質が保たれているかのチェックも自動的に行われます。現時点で対象となるデータソースは、S3です。データレイク内のデータ品質を低コストで保つ手段として、とても期待できる機能です。
公式)
https://aws.amazon.com/jp/glue/features/data-quality/
|
|
今年も盛大に開催されたAWS re:Invent。
最後を締めくくるのが、re:Playというパーティ(後夜祭)です。
有名DJによるメインステージの他、バンドによるライブ会場、ドッチボールのような参加型のアクティビティが目白押しで、とても楽しい時間を過ごすことができました。
ステップを最速で行った人が優勝というお遊びコーナー(お酒を飲んでいるとしんどいです)
|
|
メインフロアは大盛り上がり
|
|
ライブ会場も大盛り上がり
|
|
来年もまた来たいなぁ。。。祭りの後の淋しさを噛みしめる弊社社員。
|
|
ラスベガスでのre:Invent、世界中のAWS関係者が集う、とにかく熱い1週間でした。
また1年後に参加し、去年と比べて自分がどれだけ成長(技術力、英語力、コミュニケーション力)したかを試してみたい、そう感じさせてくれるのがこのイベントの一番の魅力なのかもしれません。
帰国の飛行場にて、来年のre:Inventに向けて心を新たにする筆者
(ラスベガスは飛行場にもカジノがあります。ラスベガスの乾燥とre:Inventの興奮に耐え切れず、最後の最後で鼻血を出しました)
|
|
|
|
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

この記事では「AWS Control Tower ランディングゾーンで実現する AWS Backup 統合管理:導入から有事のリストアまで徹底解説」をご紹介します

この記事では「AWS Control Towerとは?マルチアカウント管理を自動化する仕組み」をご紹介します

この記事ではAmazon QuickのチャットエージェントでMySQLなどのデータベースを検索・分析する方法を解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

