


- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
前回の記事ではOracle Cloud Infrastructure(以下、OCI)で提供されている生成AIサービスとGPUインスタンスを紹介しました。
本記事では、実際にOCI上でGPUインスタンスをデプロイして、インスタンス上でLLM(大規模言語モデル)アプリケーションの動作環境を構築する方法と、CPUインスタンスとGPUインスタンスにおけるアプリケーションのパフォーマンス検証の比較結果をご紹介します。
Index
インスタンスを構築する前に、どのLLMアプリケーションを利用するか、およびどのAIモデルをアプリケーション上で動かすかを検討します。
今回は以下のアプリケーションとAIモデルを用いて検証しました。
・LLMアプリケーション
LM Studio
https://lmstudio.ai/ (※LM Studioのサイトに移動します。)
・AIモデル
llama-3.2-1b-instruct-q8_0.gguf
Qwen2.5-Coder-7B-Instruct-Q4_K_M.gguf
cyberagent-calm2-7b-chat-dpo-experimental-q4_0.gguf
ELYZA-japanese-Llama-2-7b-fast-instruct-q4_0.gguf
※AIモデルの名前には、パラメーター数と量子化のフォーマット方式が含まれています。
1Bや7Bなどはパラメーター数を示します。(BはBillion、10億個のパラメーター)
「.gguf」の拡張子は、量子化のフォーマット形式を示します。
それでは、実際にGPUインスタンスを作成していきます。
今回はOCIの以下のシェイプおよびスペックでインスタンスを作成しました。
仮想マシンのインスタンスで選択できるシェイプについては、前回記事で紹介していますのでご参照ください。
OS:Windows Server 2022 Standard
シェイプ:VM.GPU3.2(12OCPU、180GBメモリの固定シェイプ)
ブートボリュームサイズ:300 GB
※GPUインスタンスはフレキシブルシェイプではないため、OCPU数とメモリは固定です。
|
インスタンスの構築完了後、OSへログインしてLLMアプリケーションをダウンロード、インストールします。
以下のリンクから対象のOSの最新版のLM-Studio-X.X.X-Setup.exeをダウンロードし、実行します。
URL:https://lmstudio.ai/ (※LM Studioのサイトに移動します)
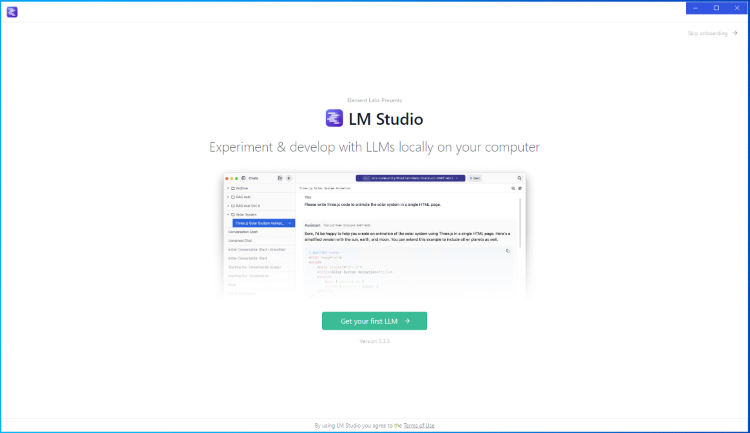
インストール完了後に以下の画面が表示されれば、インストール完了です。
|
インストール完了後の画面で”Skip onboarding”を選択し、以下の画面に遷移します。
|
画面の遷移後に、左側のメニューで虫眼鏡マークの”Discover”を選択するとAIモデルの検索画面に遷移します。
そこで目的のAIモデルを検索してダウンロードします。
|
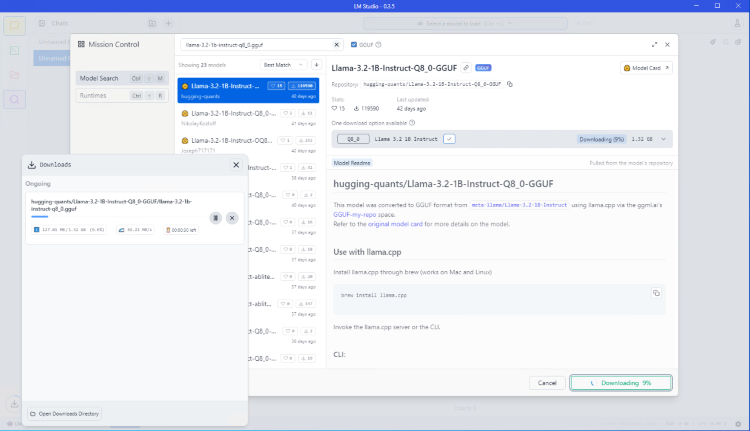
モデルのダウンロードおよび完了の状況は、ポップアップで確認できます。
|
AIモデルとチャットする方法は以下のとおりです。
先ほどのAIモデルダウンロード完了の画面で吹き出しマークを選択すると、チャットの画面に遷移します。
|
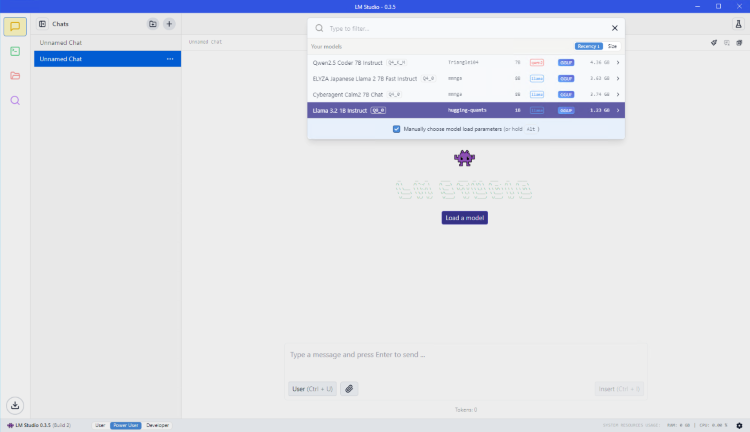
上部の”Select a model to load”を選択して読み込むAIモデルと利用するスレッド数などを選択し、”Load Model”を選択します。
|
|
|
今回AIモデルに問い合わせた質問は以下のとおりです。
① Please answer the following calculations and questions.
② Question 1
Please explain the overview of Oracle Database in 300 characters or less.
③ Question 2
3 + 5
④ Question 3
12345 + 67890
⑤ Question 4
Could you explain the types of database services offered by OCI.
⑥ thx
※今回利用したAIモデルのうち、"cyberagent-calm2-7b-chat-dpo-experimental-q4_0.gguf”と"ELYZA-japanese-Llama-2-7b-fast-instruct-q4_0.gguf”は日本語に対応しています。
日本語対応していないモデルと条件を揃えるために質問はすべて英語で実施しました。
上記の質問を実行したときの回答までに要する時間とパフォーマンスを、CPUインスタンスとGPUインスタンスで比較してみました。
取得したパフォーマンス情報はCPU使用率、GPU使用率、上位3つのプロセスのメモリ使用量(bytes)です。
※今回はAIモデルの評価ではないため、回答の正確性については言及していません。
質問を実行する際に処理のためのCPUリソース数(スレッド数)を指定できるため、今回の検証では2スレッド、4スレッドのパターンで試しています。
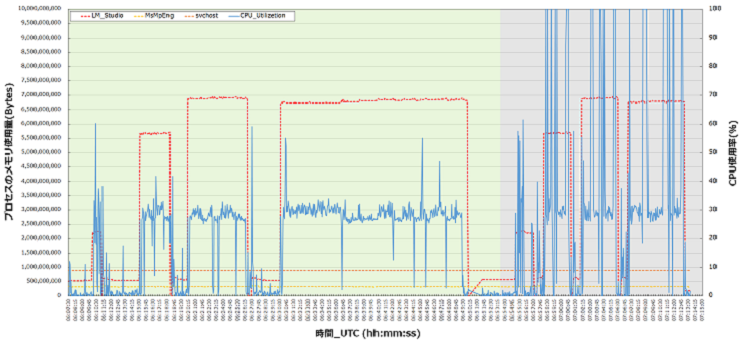
初めに、CPUのみが搭載された2OCPU 16GBメモリのインスタンス(以下CPUインスタンス)で実行した結果を図1に示します。
背景が緑のエリアが2スレッド、灰色が4スレッドで実施したデータです。
図1. プロセスごとのメモリ使用量とCPU利用率の推移 |
図1は、メモリ使用量(Bytes)とCPU使用率(%)の2軸のグラフになっています。
上位3つのプロセスは、RAMの使用量が大きいものからLM Studioとsvchost,MsMpEngです。このうち、svchostとMsMpEngに関してはWindows Defenderの実行プロセスファイルとWindowsシステムを構成する実行ファイルであり、プロセスの使用量もそこまで大きくはないことが分かります。
次に、多くのRAMを利用しているLM Stuidoを見ていきます。
LM Stuidoはプロセスの使用量に大きな波が8つあり、それぞれスレッド数とAIモデルが異なっています。
RAMの使用量が2GB~2.5GBの山は”llama-3.2-1b-instruct-q8_0.gguf”のAIモデルであり、他のモデルに比べてパラメーターが1/7であることから、RAMの使用量も小さいことが分かります。
その他の山はパラメーターが7BのAIモデルであり、モデル差はあるものの、おおよそ6GB~7GB程度のRAMを利用しています。
これにより全体RAM16GBのうちの4割ほどのRAMを利用していることが分かります。
また、この時のCPUインスタンスの質問の応答時間については以下のとおりです。
軽量な”llama-3.2-1b-instruct-q8_0.gguf”はどちらのパターンでもおおよそ1秒程度の応答でした。他のAIモデルの利用時は数十秒~数分の応答となりました。スレッド数を2倍にすると応答時間はおおよそ半分以下になり、2倍以上の性能向上が確認できました。
最後にCPUの使用率についてです。
CPUの使用率は、後半4つの山が4スレッド利用時のグラフです。
2スレッド時と比べて応答速度は速くなりましたが、質問をするタイミングで使用率がスパイクしています。このことにより、CPUを100パーセントの頭打ちまで使えていることが分かります。
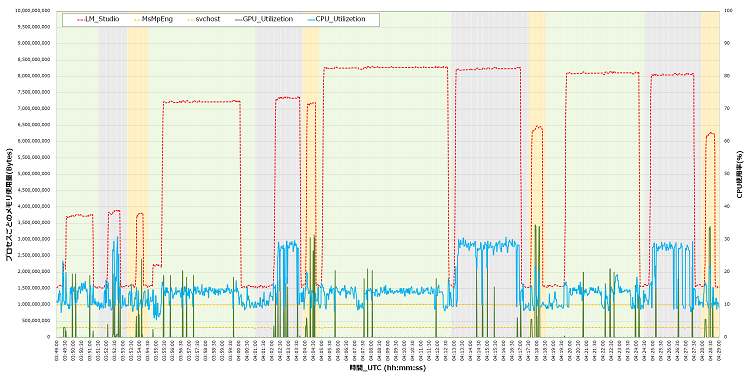
次に、GPUインスタンスで実行した結果を図2に示します。
GPUインスタンスでは、2スレッドと4スレッドに加え、利用できるリソースをフルパワーで利用した場合も計測しています。
CPUインスタンスと同様に、背景が緑のエリアが2スレッド、灰色が4スレッドで実施したデータです。リソースをフルパワーで利用したパターンは背景が黄色のデータです。
図2. プロセスごとのメモリ使用量とCPU利用率の推移 |
初めに、プロセスのRAMの使用量について見ていきます。
プロセス使用量は、CPUインスタンスと大きな差はないことが分かります。
また、LM StudioのRAMの使用量がCPUと比較して1GB程度増加しています。
次に、GPUインスタンスにおけるCPU使用率とGPU使用率についてです。
CPUの使用率は最大でも3割程度であり、CPUインスタンスと比較して使用率の逼迫は見られません。図1で見られたAIモデルに質問をしたときに、CPUの使用率がスパイクするような挙動も見られず、落ち着いて推移しています。
GPUの使用率は、質問をしたときのみGPUを一時的に利用していることが分かります。こちらも最大で34%程の使用率であり、CPUとGPUの両方でまだまだリソースに余裕があることが分かります。
また、このときのGPUインスタンスの質問の応答時間は以下のとおりです。
軽量な”llama-3.2-1b-instruct-q8_0.gguf”は、CPUインスタンスと同様におおよそ1秒以内の応答でした。他のAIモデルでは数秒〜1分程度の応答となり、CPUインスタンスと比較すると、GPUを搭載したことによる性能差が如実に表れています。
リソースをフルパワーで稼働させたときは、応答時間が200~10(ms)であり、非常に高速でした。
今回は、実際にGPUインスタンスをデプロイしてインスタンス上にLLM環境を構築してみました。
GPUインスタンスはCPUインスタンスと比較して高性能であり、様々な生成AIのワークロードで活用できることが分かりました。
クラウド上にGPUインスタンスを構築することで、柔軟にCPU数やスレッド数の増加やストレージ容量の追加が可能です。これにより、スモールスタートやワークロードの変化に柔軟に対応することができるメリットも得られます。
こうしたスケーラビリティやコスト面に優れたクラウド技術は、今後も生成AIの市場の発展に大きな影響を及ぼすでしょう。そして生成AIを実際に活用する企業のビジネスにイノベーションを起こし、競争優位性を高めることができるのではないでしょうか。
今後もOCIとAIに関する記事を執筆予定です。

|
|---|
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

