






- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
本記事では、Oracle Exadata Database Machine(以下Exadata)の最新モデル「X8M」がOracle Databaseの最上位基盤としてどのような進化を遂げたのか、その最新技術に触れつつ、弊社の検証で得たノウハウやTipsについて、記事をご覧の皆さんに共有したいと思います。
さて、最初にExadataについておさらいします。ExadataはOracle Databaseに最適化された最上位のEngineered Systemで、特長としては以下の5点があります。
1. プラットフォーム全体で標準化、最適化された事前導入構成
各コンポーネント(構成要素)の組み合わせは検証済で、Oracle Databaseを稼働させるためのベストプラクティスが反映されているアプライアンス製品です。
2. Oracle Databaseの性能を最大化する独自技術の搭載
Exadataには「Storage Server Software」という独自のソフトウェアが組み込まれ、Smart Scanに代表される、バッチ系SQLのパフォーマンス最適化を図る機能により最大限処理効率化を実現します。
3. 最新かつ先進のハードウェア
サーバとストレージは必要に応じてスケールアウト可能です。
4. すべてのデータベース・ワークロードに最適な環境を提供
データベース(DB)の統合基盤として、また、ミリ秒を争うオンライントランザクションシステム、大規模なデータワークロードが必要なDWHシステムなど様々なシステムの処理に最適な環境を提供します。
5. クラウドでも利用可能
Exadataはオンプレミスに加え、クラウドにも設置可能です。プライベートクラウドとしてお客様のデータセンターに設置するExadata Cloud at Customer、パブリッククラウドのExadata Cloud Serviceがありますが、いずれの場合でも最新モデルのX8Mが利用可能となっています。
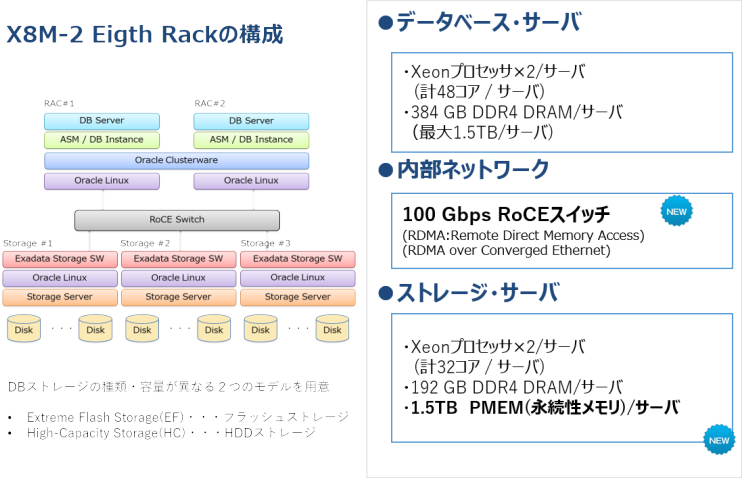
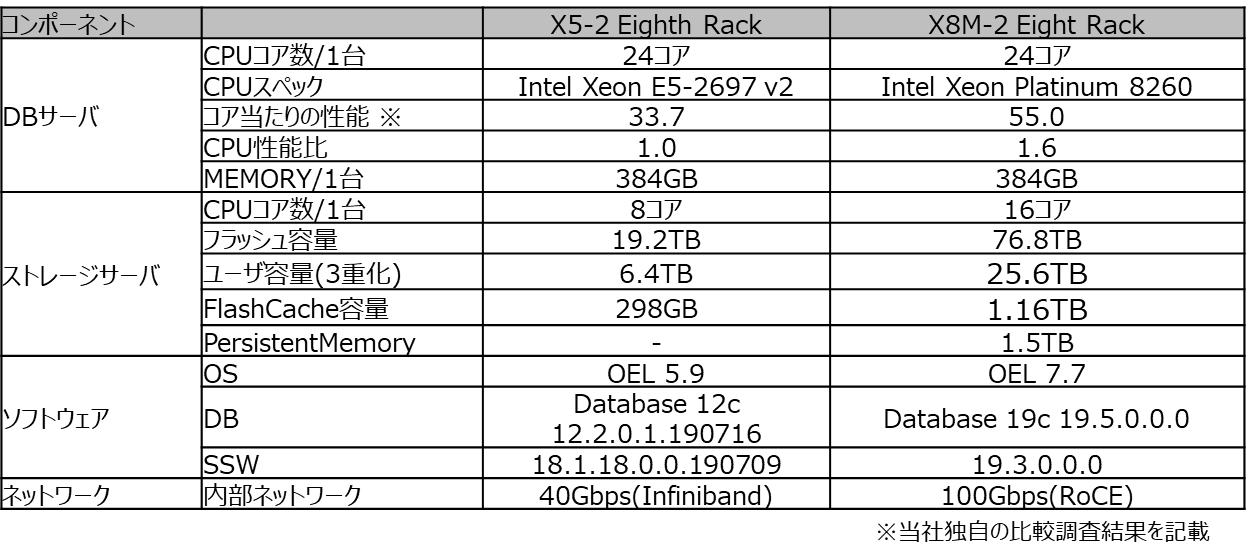
最新モデルであるX8M-2(2ソケットDBサーバを搭載)Eighth Rackの基本構成は、DBサーバ2台、DBのディスクを構成するストレージ・サーバ3台、そして内部ネットワークとしてRoCEスイッチがDBサーバとストレージ・サーバ間の接続を行います。
|
|
最新モデルでは、(1)オンライン系処理(OLTP)の高速化、(2)内部ネットワークの広帯域化の2点が大きな特長となっています。OLTPの高速化については、オンライン系のIOPS(Input/Output Per Second)が前モデルのX8と比較して2.5倍、レイテンシが10倍高速に、またREDOバッファの書き込み自体が最大8倍高速になっている、とメーカー側で公表しています。
また、内部ネットワークがInfinibandから100Gbpsの帯域を持つRoCEスイッチに置き換わることで、帯域として2.5倍に拡大したことに加え、内部ネットワーク通信にRDMA(Remote Direct Memory Access)を使って超高速にアクセスするよう置き換わっています。
これらの変更はすべて透過的になされていて、アプリケーションを書き換える必要はありません。
OLTPの高速化や内部ネットワークの広帯域化を実現するために、X8Mで導入された新技術を2つご紹介します。
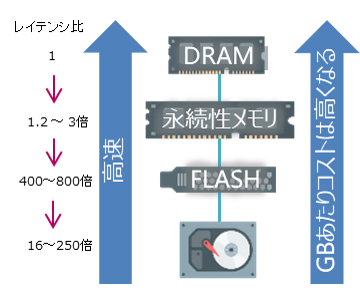
以下は一般的なハードディスク、フラッシュストレージ、永続性メモリ、DRAMを比較したものです。DRAMは高速処理が得意な半面、1GBあたりのコストが高いというデメリットがあります。これを解消するのが、高速処理が可能で大容量化を実現した永続性メモリです。
|
|
前モデルのX8ではDRAMとフラッシュの間に非常に大きな壁がありましたが、X8Mではこの永続性メモリ(Persistent Memory:PMEM)が登場し、DRAMに近いレイテンシでの処理が可能となったことに加え、DRAMに比べ大容量化がなされています。さらに、DRAMと違い、電源障害が発生しても書き込みデータが残っているため、電源供給が再開したら処理も再開できるという大きなメリットもあります。
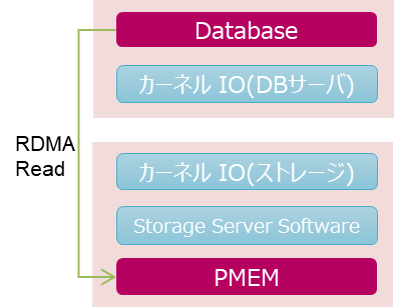
下の図を参照してください。上がDBサーバ、下がストレージ・サーバです。RDMAは、DBサーバからストレージ・サーバにデータを読み込むときに、DBサーバのOS、ストレージ・サーバのOSとStorage Server softwareをバイパスし、直接ストレージ・サーバ上のPMEMにアクセスします。これにより、CPU使用率を下げ、高いレイテンシを獲得できるという効果が期待できます。
|
|
検証にあたり、以下の3点に着目してテストケースを作成しました。
1. X8と比較しオンライン処理のIOPSが2.5倍、REDOが8倍高速になるといわれているが、実際にアプリケーションを動かして高速になるのか
2. 新機能が自動かつ透過的に実装されているというが、実際に設計などを施さずにアプリケーションが稼働するか、またアプリケーションに影響がないのか
3. X8以前のExadataと比較し、何か考慮事項があるか
また、上記のテストケースを実施するために、以下4点を検証項目として設定しました。
1. Exadata Smart PMEM Cache(PMEMキャッシュ)
PMEMキャッシュをオンすることでX8M、オフにするとX8相当になるため、オンまたはオフにして性能差や動作を確認する。
2. Exadata Smart PMEM Log(PMEM Log)
PMEMキャッシュ同様、PMEM Logをオンまたはオフに設定し、性能差や動作を比較する。
3. Exadata X5 vs X8M
リプレースを想定し、X5モデル、X8Mモデルの性能を比較する。
4. Oracle Database 19c Automatic Indexing
Oracle Database 19cの固有機能であるAutomatic Indexing(自動インデックス)を利用しX8M上で効果を確認する。
以降でPMEMキャッシュから順番に性能差や動作などの検証結果をお伝えしていきます。
PMEMキャッシュはストレージ・サーバ上にデータをキャッシュすることでディスクI/Oを削減する機能です。
|
|
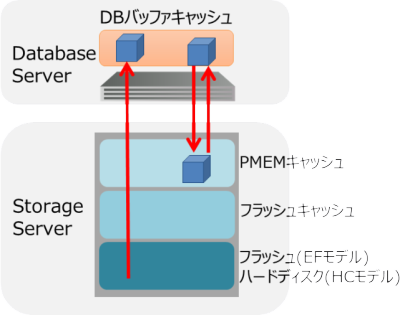
上がDBサーバ、下がストレージ・サーバを表していますが、PMEMキャッシュはストレージ・サーバ上でフラッシュキャッシュの前段に配置され、優先的に利用されるようになっています。ストレージ・サーバあたり1.5TBのPMEMキャッシュが搭載され、それが通常は3台あるため、合計4.5TBのメモリ容量として利用することができます。また、データはDBサーバ上のDBバッファ、ストレージ・サーバ上のPMEMキャッシュ、フラッシュキャッシュのいずれかに配置され、重複して保持されないように階層構造化されています。PMEMキャッシュから溢れたデータはフラッシュキャッシュに移動します。さらに、DBサーバからストレージ・サーバを読むときは、RDMAを使ってOS機能をバイパスし待機時間を大幅に削減しています。このように、PMEMキャッシュにホットなデータを保持することで、ディスクI/Oを削減することができます。
PMEMキャッシュのオン/オフについては、DBサーバ側で設定するのではなく、ストレージ・サーバ側で設定します。またDBごとにPMEMキャッシュの使用量を制限することもできます。
以下のような前提で検証を実施しました。
・SwingBench Simple Order Entry(SOE)を利用しOLTPワークロードのテストケースを1時間実行
・PMEMキャッシュをオン(X8M)またはオフ(X8相当)に設定
・スループットとAWRレポートで効果を比較
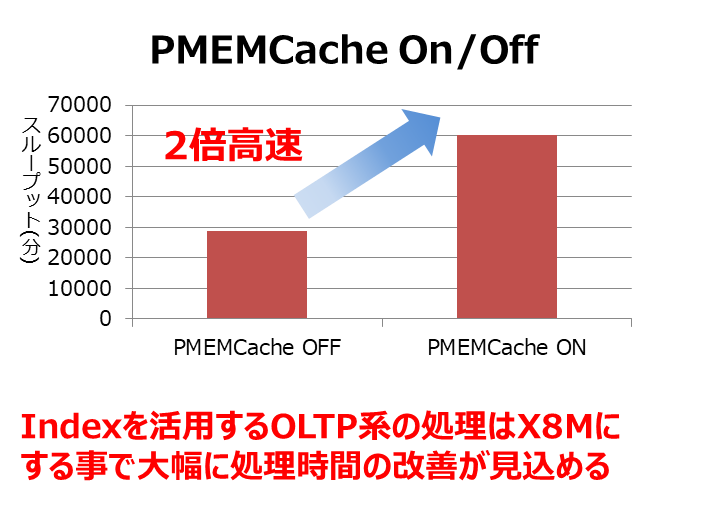
PMEMキャッシュをオンに設定した場合、オフの場合に比べ2倍の性能差になりました。特にインデックスを活用するOLTP系の処理では、X8からX8Mにすることで劇的な処理時間の改善が見込めます。
|
|
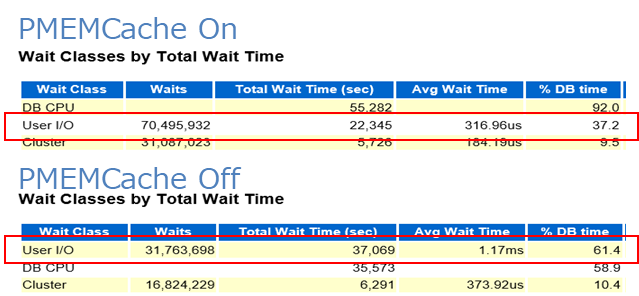
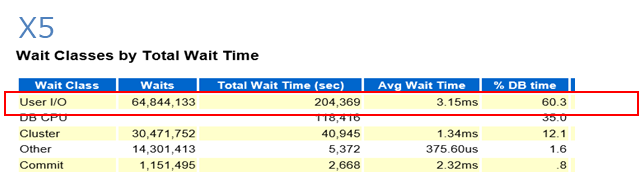
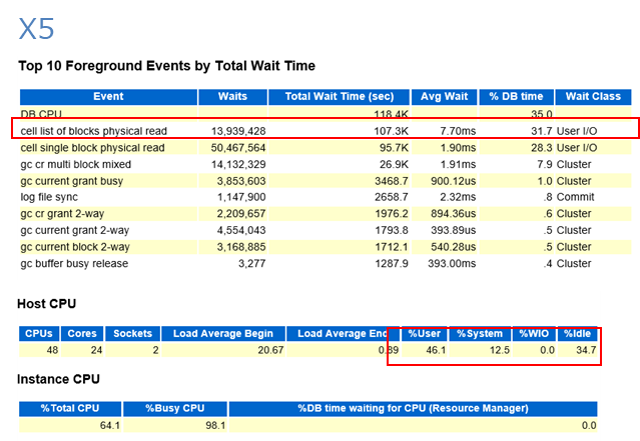
また、AWRレポートを確認したところ、PMEMキャッシュがオフのときはUser I/Oが最上位でこれがボトルネックになっている状態でしたが、PMEMキャッシュをオンにすると、I/O待機時間(Total Wait Time)が40%ほど削減され、CPU時間の割合が増えています。これによりスループットが大幅に向上していることが確認できました。
|
|
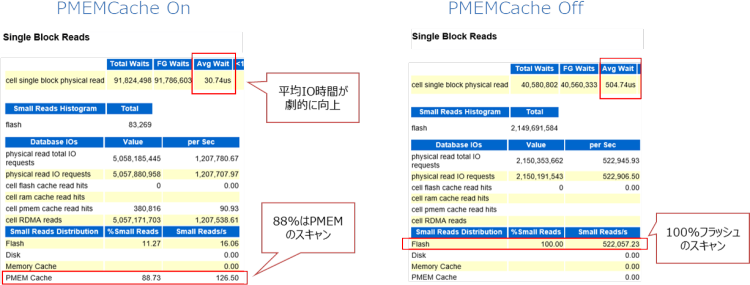
さらに、AWRレポートでExadata専用の統計セクションにある「Single Block Reads」という項目に着目しました。cell single block physical read待機イベントの合計があるのですが、Avg Wait(平均待機時間)はPMEMキャッシュがオンの場合に30.74us(マイクロ秒)、オフの場合は504.74usと、オン、オフでおよそ16倍の差が出ました。オンでは劇的にIO待機時間を改善していることがわかります。
|
|
この要因として「Small Reads Distribution」の「%Small Reads」に着目したところ、フラッシュからの読み取りではおよそ11%程度だが、88%はPMEMキャッシュから読み込んでいることが確認できました。PMEMキャッシュのヒット率としては88%、当然オフの場合はフラッシュから100%読み取っており、この結果がAVG Waitに反映されていることが確認できます。
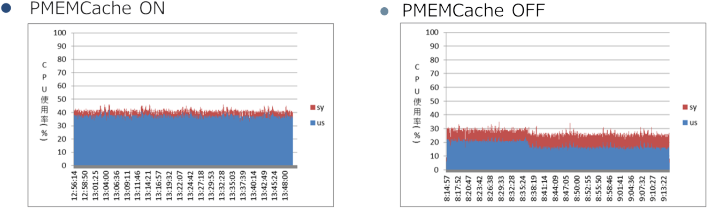
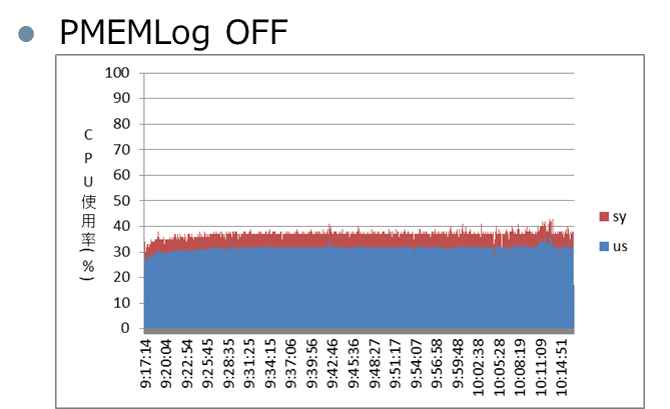
また、ExaWatcherのCPU統計から、CPU使用率の差異についても確認しました。左がPMEMキャッシュがオン、右がオフの場合です。
|
|
青がvmstatの%user、赤が%sysです。Oracle Databaseが使うCPU使用率は、PMEMキャッシュを使っているほうが高くなりますが、これはスループットの増加によりCPUのユーザー時間が増加していることを表しています。また、注目すべきは赤のOS側の使用率を示す%sysで、PMEMキャッシュをオンにすることで使用率を10%程度削減できていることが確認できました。これはRDMAによってOSの処理をバイパスしている効果が出ているものと思われます。
PMEMキャッシュをオンにすることで、データベース側で使うCPU使用率を抑える、つまりキャパシティを増やすことができるという効果を、上記からも確認できました。
PMEMキャッシュの活用ポイントを以下にまとめます。
1. IOの待機時間が短くなり性能が向上
これはDBバッファのヒット率が低い環境ほど効果を感じます。日中オンライン系の処理が流れ、夜間はバッチ処理が流れるといった、データの傾向が変わるようなときに、4.5TBのPMEMキャッシュにデータがあれば、バッチ処理の大幅な改善につなげられるのではないかと考えます。
2. OLTP系システムでSmart Scanをしている場合は、Index Scanに戻すことを検討
PMEMキャッシュ自体は8K単位のディスクアクセスといった、オンライン系の処理で活用されるからです。
3. 共有環境では特定ワークロードなどによりPMEMキャッシュが占有されないよう使用サイズを変更
PMEMキャッシュは4.5TBありますが、複数インスタンスの統合DB基盤ではPMEMキャッシュが共用バッファとして利用されます。そのため、特定のワークロードやインスタンスでの占有が心配であれば、性能安定化のために、I/O Resource Management(IORM)でPMEMキャッシュの使用サイズを変更しておきます。
4. PMEMキャッシュの使用量はDBA_HIST_CELL_GLOBALから確認
今回のワークロード実行時には152GB程度が割り当てられていました。
|
|
AWRレポートではストレージ・サーバ全体の統計になるので、DBごとの利用状況は上記のDBA_HIST_CELL_GLOBALで確認しました。
定期的にDBA_HIST_CELL_GLOBAL情報を収集
AWRレポートと同じタイミングで、定期的にこのDBA_HIST_CELL_GLOBALビュー情報も取得し、評価することをお勧めします。
OLTP系のブロック単位のI/Oで活用される傾向
統計では様々なIO傾向を確認できますが、例えば、上のように、OLTP系のブロックのIO量がどの程度あったのかもDBA_HIST_CELL_GLOBALビューから確認できます。
以上をまとめると、PMEMキャッシュのオン、オフにより、性能に大きく影響することがわかりました。また、DBごとのPMEMキャッシュ使用量を監視してサイズを設定することが、性能を安定化して運用するための重要なポイントになります。
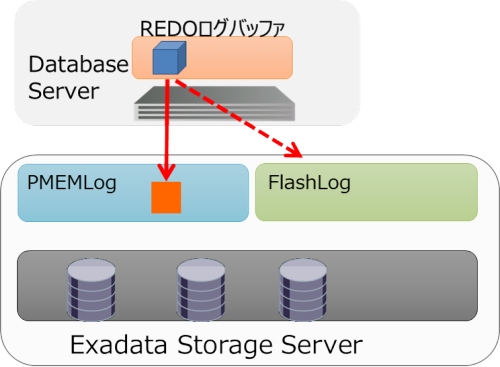
Exadataでは、REDOログの書き込みパフォーマンスを改善させる機能として、ストレージ・サーバ上のPMEM上に専用のバッファ「PMEM Log」を設けています。
|
|
具体的にはREDOログバッファの情報をREDOログに書き込む際に、ディスクに書き込まずRDMAを介してPMEM Logに書き込み、処理が終了したらアプリケーション側に処理を戻します。
PMEM Logが利用できない場合は、自動的にFlash Logに処理がバイパスされます。DBサーバ側では特別な設定が不要で透過的に利用されるものになっています。またストレージ・サーバのIORMでDBごとにオンまたはオフに設定することが可能です。
以下のような前提で検証を実施しました。
・SwingBench TPC-DSテストケースによるDWH系ワークロードを1時間実行
・PMEM Logをオン(X8M)またはオフ(X8相当)に設定
・スループットとAWRレポートで効果を比較
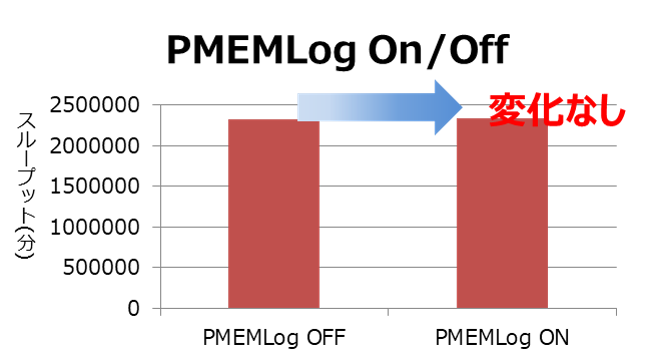
PMEM Logのオンとオフによるアプリケーションのスループットに大きな差異はありませんでした。
|
|
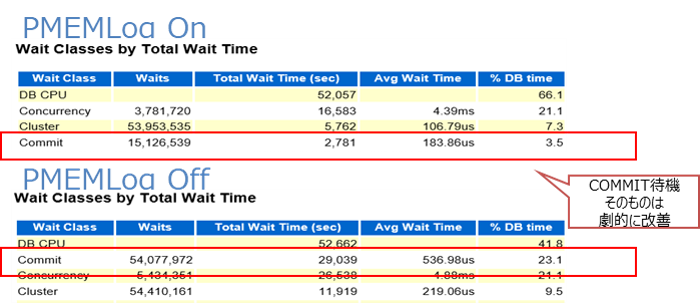
AWRレポートで参照したところ、CommitのTotal Wait Timeがオンの場合に90%程度削減されており、平均待機時間(Average WaitTime)も大幅に削減されていて、Commitの待機自体が劇的に改善されている傾向が見受けられました。
|
|
上記の通り、コミットがボトルネックになっていなかったため、スループットの改善効果にはつながらなかったものと思われます。
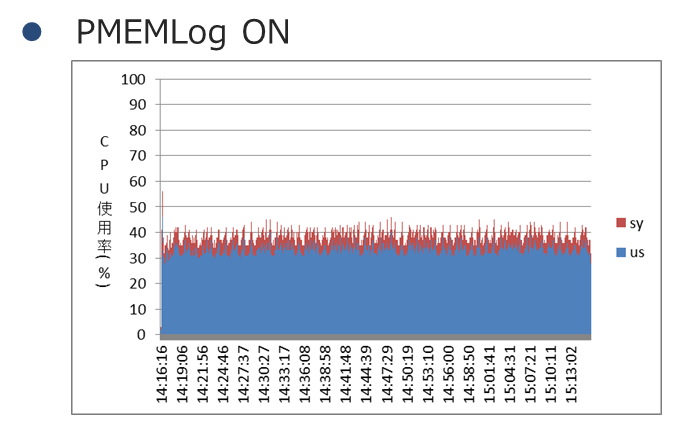
PMEMキャッシュ同様、PMEM LogでもCPU使用率の差異について確認しました。
|
|
|
スループットがほとんど変わらなかったため、青の「%user」に差異は見られません。赤のOS側の使用率を占める「%sys」が、PMEM Logがオンのときに数パーセント削減できていることがグラフから確認できました。PMEM LogについてもRDMAによるCPUの削減効果が確認できます。
1. PMEM Log機能はREDOバッファの書き込み性能に大きく寄与することを確認
2. 待機イベントはlog file syncの待機時間としてAWRレポートに反映
3. PMEM LogはインスタンスごとにIOバッファとして割り当てられ、バッファが不足した場合Flash Logにバイパス
4. 更新系処理でこの待機イベントがボトルネックになる環境では、X8Mにすることで(PMEM Logを利用することで)大幅な処理時間の改善が期待
5. REDOバッファの性能は、DBA_HIST_CELL_GLOBALビューやAWRレポートから確認
DBA_HIST_CELL_GLOBALビューでは、REDOログに関わるIO処理時間の統計を確認できます。
|
|
AWRレポートではlog file syncの待機イベントとしてオンとオフの差異が確認できます。
|
|
6. Exadata環境でのPMEM Logはデフォルト。このまま利用することを推奨
REDOログバッファはベストプラクティスの128MBで始め、そのままの設定になっている環境が多いと思います。PMEMキャッシュ自体が1.5TB、3ノードで4.5TBあるため、領域的な考慮はほとんど不要です。特にデメリットもないのでPMEM Log機能はデフォルトのままで使うことをお勧めします。
今回はExadataハードウェアのリプレースを想定し、弊社のテスト環境で、CPUコア数を同一としてX5-2)とX8M-2)を比較しました。また、DBについてはOracle Database 12cから19cへのバージョンアップを想定し検証しています。大きな差異としては、DBサーバのCPUスペックが大きく改善、ストレージ・サーバのフラッシュの容量も大きく、永続性メモリ(PMEMキャッシュ)の搭載が大きなポイントとなります。
|
|
・SwingBench Simple Order Entry(SOE)を利用しOLTPワークロードのテストケースを実行
・SwingBenchのクライアント数はDBサーバのCPU使用率を最大限稼働させる数に調整
・X5、X8Mでそれぞれ1時間ずつ実行
・スループットとAWRレポートで効果を比較
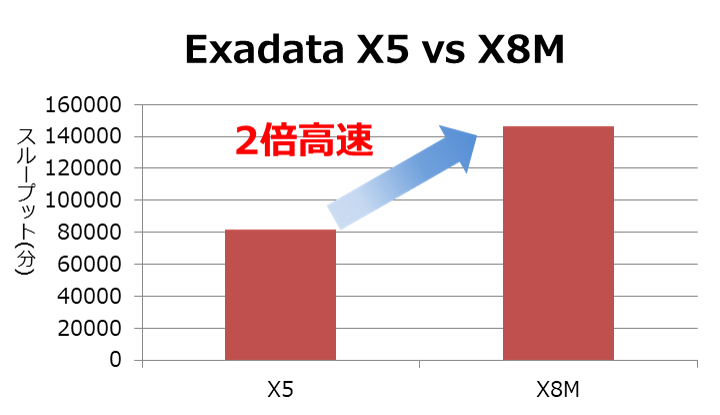
X5と比較しX8Mはスループットが2倍に向上しました。
|
|
また、I/O待機時間はX8Mでは1/3に減少、これは傾向としてはPMEMキャッシュのオン(X8M)・オフ(X8相当)の比較とほぼ同じ傾向となっています。永続性メモリによるIO待機時間の改善により、X8Mにアップグレードする事でCPU性能差以上の改善効果を見込めることが確認できました。
|
|
|
|
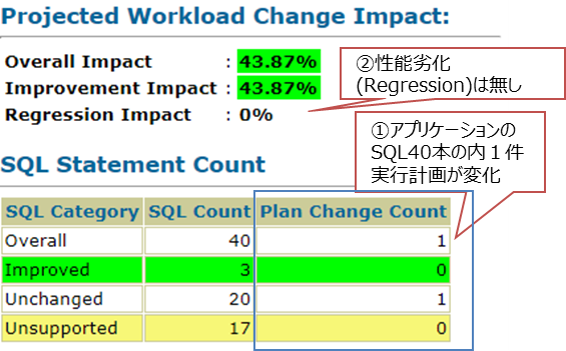
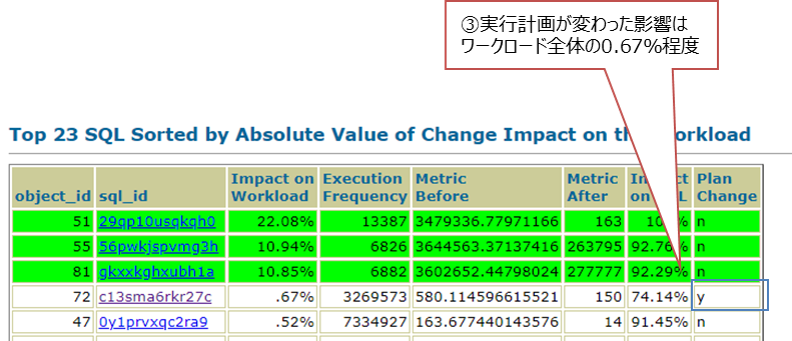
今回Oracle Databaseも12cから19cへとバージョンをあげて検証しました。実行計画の差異が大きく影響している可能性もあったので、今回の検証ではそこも確認しました。実行計画の差異は、Oracle Real Application TestingのSQL Performance Analyzer機能で簡単に確認できます。確認したところ、SQL CountをみるとSQL文の数自体は40個実行されており、実行計画が変わったものは1件ありますが(①)、性能劣化した割合は0%となっています(②)。実行計画が変わってしまったSQL(③)については全体ワークロードの内影響度は0.67%程度と性能劣化がないことが確認できます。また、今回の検証結果の差異は、データベースのソフトウェア部分ではなく、X8Mの改善効果によるところが大きいといえます。
|
|
|
|
もう少し結果を掘り下げてみます。
|
|
|
スループット自体は2倍の改善効果がありました。しかし、「テストケース1」のX8とX8Mの比較でも改善効果は同じ2倍だったので、古いモデルのX5であることを考えると、もう少し差異が出てほしかったというのが正直な感想です。
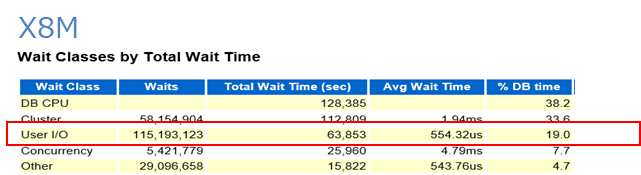
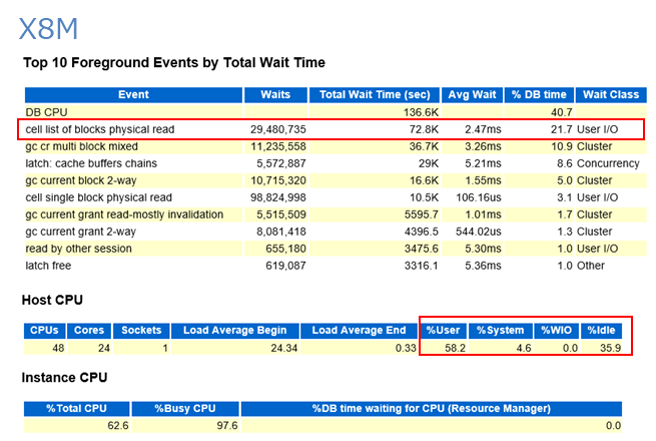
そこでAWRレポートで確認したところ、左側のX8MではUser IO系の待機イベントは大きく減少する一方、DBバッファの同一セッションで同一ブロックにアクセスする時に発生する待機イベント(gc系待機イベント、cahe buffer chains)が、X5と比べかなり増加しています。これがスループットが2倍でとどまる理由です。
今後X8Mにリプレースすると、ディスクIO自体は大きく改善します、その後新たな問題が発生することがあるかもしれず、今回のようなケースではアプリケーションのパーティショニング、パラメータのチューニングが可能であれば、それらの検討がリプレースに必要ではないかと考えています。さらに大きな改善効果を生むためには、そういった設計やチューニングが必要であるということが確認できました。
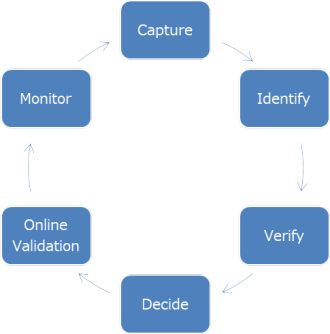
ExadataやOracle Database 19cでは、索引の作成をOracle Databaseに任せる自動チューニング機能が利用可能です。
1. SQLワークロード、実行計画を15分間隔で監視
2. 改善が見込まれる索引を特定し、アプリーションから見えない不可視索引として作成
3. 実際にSQLを実行して効果を確認
4. 全体敵に効果が見込める場合は可視化してアプリケーションから見えるようにする
5. 可視化後も検証を実施
6. 使用状況を監視し、使用されていないものは削除
|
|
まずは自動インデックスを有効化するスキーマの設定します。AutoIndexModeをインプリメントに変更し、インデックスを作成する表領域を指定します。これだけで、自動インデックス機能が使用できます。
|
|
|
|
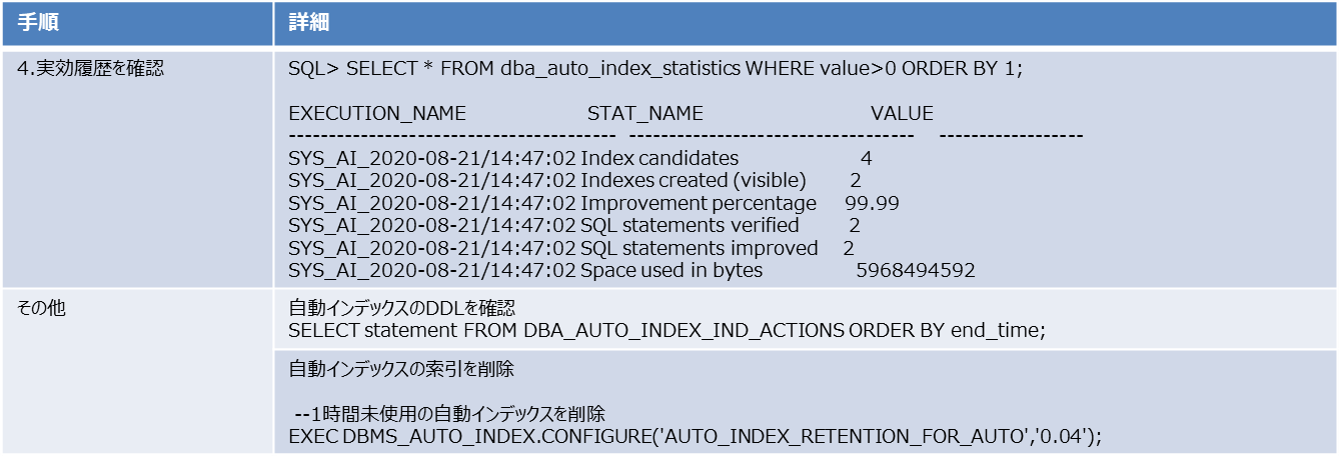
その後ワークロードを実行すると「3. 実行履歴の確認」に記載した通り、15分間隔でOracle Databaseで評価され、定期的に索引が作成されます。また「4. 実効履歴を確認」で書いた出力例のように、インデックスが作成され、改善効果や領域の使用量を確認したりできます。また作成された自動インデックスのDDL文を確認できたり、索引を削除するときには「その他」に書いてあるように一定期間未使用のインデックスを削除するということもできます。
・SwingBench Simple Order Entry(SOE)を利用しOLTPワークロードのテストケースを実行
・事前に非ユニークインデックスをすべて削除
・自動インデックスの実装有無でそれぞれ1時間ずつ実行
・スループットとAWRレポートで効果を比較
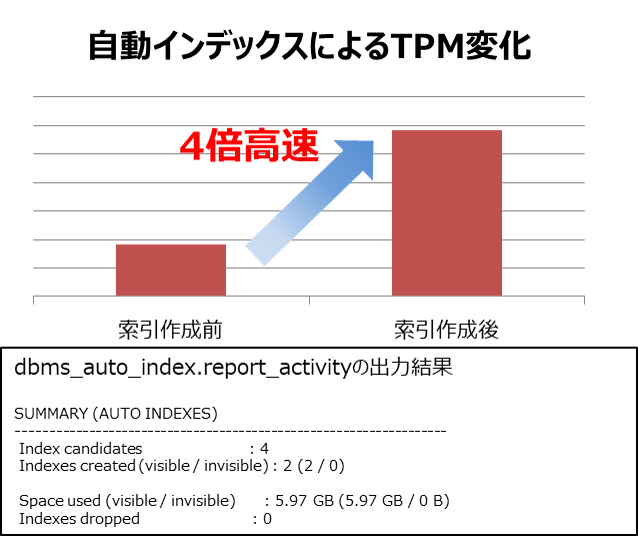
結果として、索引が2つ作成され、スループットとして最終的に4倍高速化されました。一定時間(15分)ごとに索引が自動作成され、PMEMと非常に相性がいい機能だと思います。
|
|
また、Exadataをお使いの場合、ユニークインデックス以外は作成しないという設計方針のお客様もいらっしゃると思います。X8MではPMEMを活用してパフォーマンスを改善するためにはインデックスチューニングは非常に重要なポイントです。自動インデックス機能を活用することで、コストを抑えて効果を確認・比較することができます。
自動インデックスというだけあって、索引のメンテナンスは完全にシステム任せになります。作成されたインデックスの削除は手動ではできません。また、ストレージの空きがなければ作成されないため、専用の表領域のサイジングも検討する必要があります。
このように、完全にシステム任せで制御が難しい機能になっているので、使い方としては検証フェーズ、テストフェースでワークロードを実行して自動インデックスを作成し、効果があった索引についてDDL文を確認するようにすれば、リスクやコストを抑えて本番環境に実装することができると考えています。
検証に関する結果報告は以上ですが、他にご紹介しておきたい機能として「Exadata I/O Resource Management」があります。
Exadata I/O Resource Management(IORM)は、複数DBを使用する場合、DBごとにPMEMキャッシュの割り当てサイズを制限する機能です。
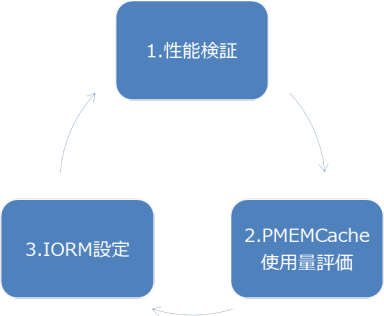
デフォルトは特別な設定なしのため、アプリケーションの利用状況によって各DBのPMEMキャッシュヒット率が変化します。しかし、特定のワークロードによりPMEMキャッシュが占有されて性能が出ない状況が発生することが想定されます。日頃から処理のピーク時のPMEMキャッシュの使用量を確認し、ストレージ・サーバ側でDBごとにIORMで指定しておくことをお勧めします。
以下はDBごとにPMEMキャッシュのサイズを設定するときのお勧めの流れです。
1. 性能検証として、本番相当のワークロードを複数のDBに対して実行する
2. DBA_HIST_CELL_GLOBALビューでPMEMキャッシュの使用量を確認し、ベースラインとなるサイズを確認
3. Cellcliコマンドで「pmemcachelimit」パラメータをベースラインのサイズに設定
|
|
上記のサイクルを繰り返し、PMEMキャッシュの使用量、それに伴う性能影響の有無を確認しながら徐々に値をチューニングしていくのがよいでしょう。
弊社にて検証した結果、以下の3点を確認できました。
1. X8MはX8と比較し、主にSingle Block ReadのIO速度が10倍以上向上し、スループットは2倍という大幅な性能向上を確認できた
2. 1番の向上要因として、ストレージ・サーバ側に実装されたPMEMキャッシュの存在が非常に大きく、効果は抜群。しかもDB側での設定は特に不要でX8Mに移行するだけで利用できた
3. PMEMキャッシュを最大限活用するためには、自動インデックス機能やIORMを適切に活用することが必要で、今回そのための設定方法や測定方法などの知見を得られた。
また、検証でみえたX8Mの強みを以下にまとめます。
1. オラクル社のふれこみ通りの実力を確認できた
レイテンシとして19マイクロ秒というトピックがあったが、今回の検証ではそこまで達することができなかった。しかしIO性能が大幅に変わる、改善することは確認できた。
2. Exadataは毎年モデルチェンジがなされ地道にハードウェアの性能改善が進んでいるが、永続性メモリーの採用はSmart Scanと並ぶ大きな進化。PMEMは使いやすく難しい設定は不要にも関わらず、大幅な性能向上が期待できる。
3. 今回の永続性メモリはDBサーバとストレージ・サーバの構成をとるExadataだから生きてくる機能。DB側で何も設定は行わず、ストレージ・サーバ側で機能を吸収している。他のデータベースやアプライアンスでは採用は難しい機能
4. 性能安定化にはIORMでPMEM最大使用量を設定する。これにより統合DB基盤としての信頼性を高められる。
5. 自動インデックスは気軽に性能向上を体験できる。テスト環境でチューニング候補のインデックスをリストアップし効果を確認。その後、本番環境に導入という使い方をすると有効活用できるのではないか。
結論として、X8Mを検証した結果、期待通りの実力を持っていたということを確認できました。また、今回の検証により性能安定化のためのTipsを得られたり、自動インデックス機能を確認できた点は非常によかったと思います。
検証結果やX8Mについてご不明な点があれば、是非アシストへお問い合わせください。
本記事に関連し、執筆者である笠原克俊と、同じくデータベース技術統括部の中村嘉宏がインテル株式会社様の取材を受けました。
▼内容はこちら(インテル株式会社様のホームページにリンクしています)
ttps://www.intel.co.jp/content/www/jp/ja/architecture-and-technology/optane-pmem-cache-oracle-exadata-x8m-paper.html
|
|
笠原 克俊
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

