

本記事では、データ活用基盤の変化と、Data Mesh(データメッシュ)、Modern Data Stackというデータ活用に関わる最新の概念をご紹介します。
データ活用に関する概念の変化
最初に、企業におけるIT化の変遷とデータ活用に関する概念がどのように変化してきたかを振り返ってみましょう。
企業におけるIT化の変遷とデータ活用の形
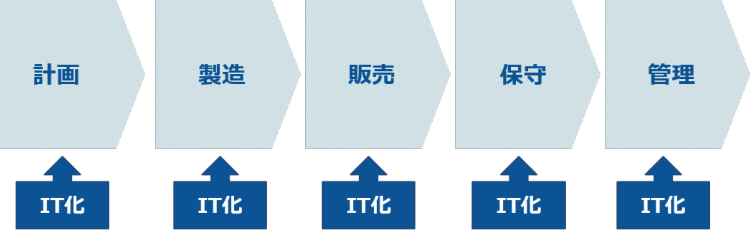
一般的に企業には、計画から管理まで、様々な機能・プロセスがあります。企業におけるIT化は、会計から始まり、それぞれの企業機能一つ一つに、時期や経緯が異なりながらもシステムが検討・導入されていくという、いわゆるサイロ化された状態で基幹システムの構築が進んでいきました。そして、ある程度企業全体のIT化が進んだ段階で、今度は企業横ぐしで長期にわたる分析を行うために、多くの企業がデータ活用のためのデータウェアハウス(DWH)構築に取り組まれています。
企業横ぐしで長期にわたる分析を行うためのデータ活用には、三つの形があると捉えています。

一つ目は、業務活動が入力された基幹システムから、ETLツールを利用して、DWHまたはデータマート(DM)にデータを蓄積して公開できる状態にしておき、それを主にビジネスインテリジェンス(BI)ツールを利用して、業務を振り返り是正していくという形です。この形は業務を振り返り、是正する、PDCAサイクルを回す普遍的な企業におけるデータ活用であると言えます。

また昨今、企業内にあるデータだけでなく、IoTデータやモバイル、外部データといった新しいデータを取り込んで活用していく動きが活発化しています。その中で注目されているのがデータレイクです。データレイクの構築はここ数年、各企業で進んでおり、筆者も当初は、データレイクのデータも一つ目の形と同様、DWHやDMに取り込まれ、BIツールで活用されているのではないかと考えていました。
しかしこれらの新しいデータの活用は、今まで見えてなかった文脈を探ったり、新しい仮説を見出そうとするのが目的です。またそれらは今後も活用し続けるかどうかも決まっていないことが多く、スピードの観点からもわざわざデータベースという器に入れない分析手法が好まれる傾向もあります。したがって、これは一つ目とは異なる、二つ目のデータ活用の形と捉えることができます。
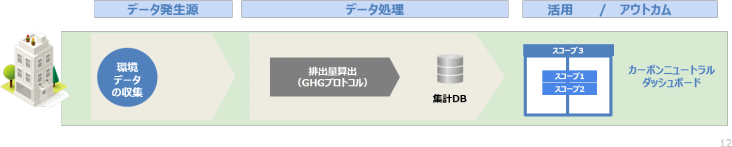
三つ目は、前の二つとは異なる観点でのデータ活用で、最近お客様を訪問する際によく話題となる「環境データ」に関するものです。SDGsをはじめ、各企業には環境への配慮が求められることから、新たに環境データの収集であるとか、これまで保持していたデータであっても標準のGHGプロトコルでCO2排出量という値に変換して蓄積し可視化する、つまり、カーボンニュートラルダッシュボードのようなものを出していく必要があるということです。今後、新しいデータ活用の形として検討されていくのではないでしょうか。
複数のデータ活用基盤
データ活用基盤も、環境の変化やニーズに応じて変化しています。前項「企業におけるIT化の変遷とデータ活用の形」でお伝えしたように、企業システムはシステム化時期の違いにより結果としてそれぞれサイロ化していました。そのため、従来のデータ活用基盤は、サイロ化したシステムのデータを物理的に一度統合し、目的別にDM化してBIやAIで分析するという形を採用していました。
しかし、情報活用のニーズが高まり様々な分析の観点がユーザーから求められるようになると、複雑な多くのETL処理や、多様なニーズに対応した大量のDM作成の必要が生じ、さらなる環境変化への追随が難しくなってきました。
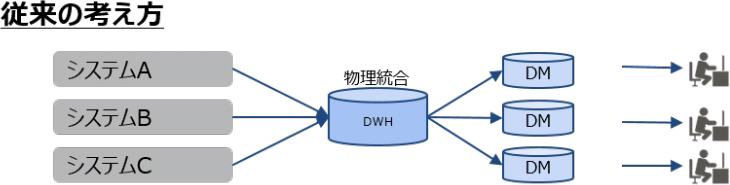
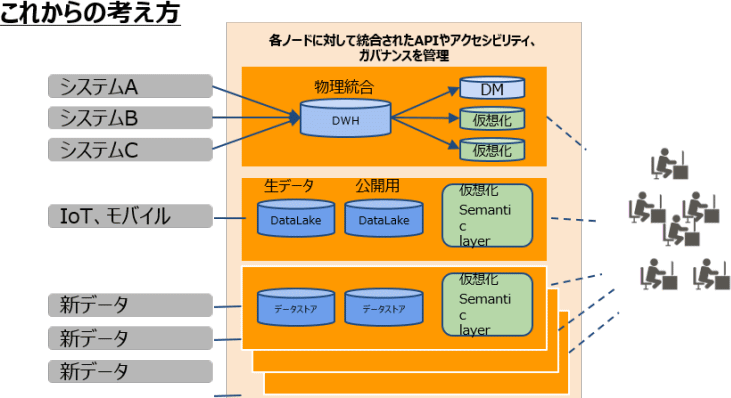
そういった中で注目されているキーワードが「分散」です。データ活用基盤が多様化する中で、業務の性質ごとに最適化された複数のデータ活用基盤はそのまま保持しつつ、相互のデータアクセスが可能な状態を作ることで、分散した状態でも統合的なデータ活用を可能にする考え方が一つの解決策として注目されています。アメリカではすでに「データメッシュ」という、分散型のデータ活用基盤に関する考え方が提唱されつつあります。
データメッシュとは?
テクニカルコンサルタントのZhamak Dehghaniが提唱したデータメッシュに関する二つの論文があります。
Zhamak Dehghaniの論文は、具体的なテクノロジーの提唱ではなく、テクノロジーに囚われないモデル追求という意味合いで、論理的アーキテクチャの方向性が概念的かつ抽象的に書かれているのが特徴です。先ほど、分散型のデータ活用基盤について触れましたが、このデータメッシュはそのガイドの一つとして捉えていただくのがよいかと思います。
Zhamak Dehghaniが提唱する「データメッシュ」のポイントは二つ
二つの論文の内容は概念論であり、言及されている範囲も非常に多岐にわたるのですが、アシストでは、ポイントは以下の二つであると捉えています。
(1)DWHやデータレイクのようなデータ活用基盤では変化に追随できない
従来型のセントラルDWHを中心としたデータ活用基盤に加え、10年ほど前から、半構造や非構造データも含め多様なデータも対象とした「データレイク」という概念が出てきて、多くの企業が少なからず投資を行ってきました。しかし、情報活用のニーズは多様化する一方で、これらは非常にモノリシック、つまり、一つの大きな硬い岩盤のようなものとなってしまい、変化への追随が困難な状況になったという反省が、Zhamak Dehghaniがデータメッシュを提唱するきっかけとなりました。
具体的には、様々なシステムからのデータを一度DWHに物理的に統合するので、パイプラインが複雑化し、新しいデータが活用可能になるのに時間がかかる、また、変更が発生してもすぐに対応できない状況になっていました。これに加え、企業によっては、パイプラインのETLジョブやプログラムを構築するデータエンジニアが専門職として存在しなければならず、彼らが業務内容やエンドユーザーの要望からは遠く離れた存在になっているという課題も生じました。
(2)ドメインを主軸とした分散アーキテクチャを提唱
そこでZhamak Dehghaniは、解決手段の一つとしてドメインを主軸とした分散アーキテクチャを提唱しました。論文の中で、ドメインがどういう単位かは明確に定義されていないのですが、一般的に言うと、企業の業務の大きな括り、例えば、「業務機能」と捉えるとよいかもしれません。この括りについては、各企業の業務内容や組織形態によって変わってくるかと思います。
そして、ドメインを主軸に考えながら、基幹業務でのドメイン駆動設計やマイクロサービスに代表されるような分散アーキテクチャの考え方を、データ活用基盤にも適用してはどうかという提唱をしました。
ただ、過去のように新たなサイロ化をもたらすものではなく、ドメイン同士がお互いに連携し合うものを構築しようという提唱です。
データはプロダクトであり、その顧客はエンドユーザー
Zhamak Dehghaniが提唱するもう一つ重要な概念が、プロダクトとしてのドメインデータという考え方です。実際に販売する商品のようなイメージでデータをプロダクトとして提供し、それを活用するエンドユーザーやデータサイエンティストのようなデータ消費者が顧客であるという概念です。つまり、企業として提供しているデータで、顧客が笑顔にならなければなりません。
また、プロダクトとしてのドメインデータに求められるものは、以下の五つです。
検索・アクセスがしやすいこと(データカタログや標準的な命名規則なども必要)
データ品質が高く、信頼性が高いこと
ドメイン間でのデータ結合・集約が標準化されていること
セキュアなアクセスが提供されていること
クロスファンクショナルチームであること
最後のクロスファンクショナルチームについて補足すると、先ほど紹介した「データエンジニアが専門職化することによって、データの意味やそのニーズから隔離されたところに置かれる」といった反省からZhamak Dehghaniが提唱したものです。データエンジニアを独立した職種として置くのではなく、一つのドメインの中で、データの責任者であるデータプロダクトオーナー、データエンジニア、インフラエンジニアが連携してドメインデータを作るべきであるとしています。
また、プロダクトとしてのデータに求められる性質(データの品質やマスターデータの一意性など)はどれもデータマネジメントの観点からは当たり前のように見えますが、やらねばならないことをやり切ることがどれだけ難しいかは、皆さんにもご経験があるかと思います。Zhamak Dehghaniが提唱した「プロダクトとしてのドメインデータ」という考え方により、顧客に本当に喜ばれているデータかどうかを改めて振り返る機会になります。
求められるパラダイムシフト
Zhamak Dehghaniの提唱内容から、データ活用基盤についての考え方をどのように転換させていったらよいかを下の図にまとめました。
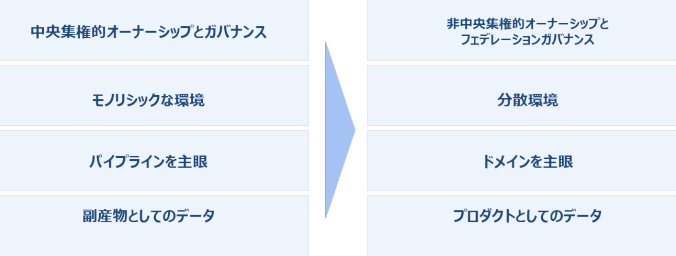
(1)モノシリックから分散へ、中央集権から非中央集権へ
従来、モノリシックな環境で中央集権的に管理していたものを、ドメインとして分散させ、ドメインがお互い連携する形で連邦自治のようにガバナンスします。
(2)主軸はパイプラインからドメインへ、データは業務の副産物ではなくプロダクトという考え方へ
データの加工やパイプラインではなく、分散環境を起点とし、ドメインを主眼に置きます。またデータは業務の過程で生み出される副産物ではなく、顧客が喜ぶプロダクトであるという考え方へ変えていく必要があります。
データをプロダクトとして捉えた場合、品質はもちろんですが、販売先である顧客のことを考える必要があるという点が重要であると気付かされます。
アーキテクチャのまとめ
実際の論文にもアーキテクチャに関する図がありますが、それを参考にまとめたものがこちらになります。
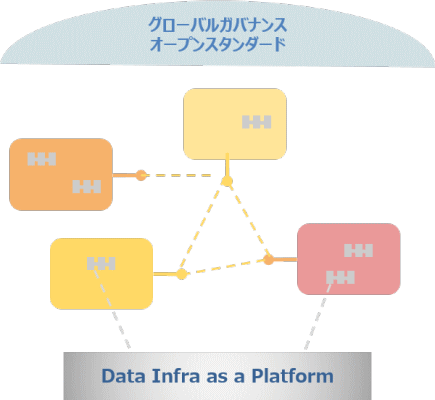
色のついたところが一つのドメインになります。先ほどお話しした部分もありますが、アーキテクチャに関するZhamak Dehghaniの提唱は以下の4点に集約されます。
ドメインデータはクロスファンクショナルチーム(ドメインオーナー、データエンジニア、
インフラエンジニア)によって提供される新しいドメインデータは他のドメインデータと関連付けて作成される
プロダクトとしてのドメイン指向データは、他のドメインからも参照される
ドメイン内でのデータパイプラインは、共通のセルフサービスインフラを利用する
Zhamak Dehghaniの提唱をさらにかみ砕くと、以下にまとめられます。
ドメインを相互連携させ、ユーザーからの多様なニーズにどのドメインからでも
データを参照できるような検索性を担保するプロダクトとして提供するデータは、ドメインオーナーが品質などに責任を担うが、
ドメイン全体は企業がガバナンスを行うインフラは共通プラットフォーム(テンプレート)化し、テンプレートをコピーして
ドメインに応じた変更を加えていく
筆者も、今後、米国はじめIT業界が、Zhamak Dehghaniの論文に書かれている概念をどのように実現していくのか非常に注目しています。また、今年(2022年)のガートナーのハイプサイクルでは、MVA(Minimum Viable Architecture)という考え方が提唱されていました。これはリーンスタートアップでよく言われる「ユーザーに必要最小限の価値を提供するプロダクト(Minimum Viable Product)」をもじったものではないかと思いましたが、最小限動くアーキテクチャであるMVAも、Zhamak Dehghani提唱の「Data Infra as a Platform」に合致してくるのではないかと感じました。
分散型のデータ活用基盤まとめ

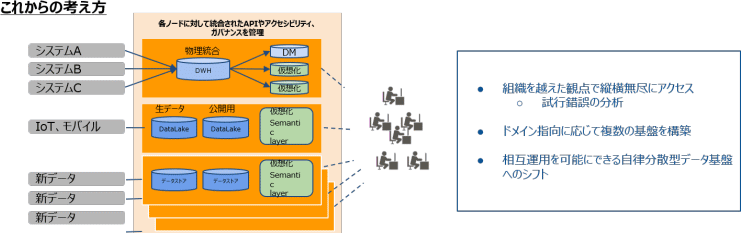
データ活用ニーズがPDCAなのか仮説を新たに生み出すものなのかによって、求められる基盤が異なります。また、昨今では物理的にデータ統合するのではなく「分散」という考え方が出始めているということに加え、データメッシュでは「ドメイン」という角度から分散していけばよいという提唱でした。
筆者としては、今後ドメインという考え方を採用するのであれば、PDCAなのか仮説を生み出すものなのかといったデータ活用ニーズを軸にするのか、どのような括りが最適かをお客様と会話しながら検討していきたいと考えています。
ここで重要なのは、必ずしも今までの基盤を無理やり育てていくのではなく、「分散」という考え方も一つの選択肢だということ、そして、あくまでも提供するデータはエンドユーザーに喜ばれるプロダクトにすること、この二つが重要な視点だと考えています。
企業においてもドメイン単位でエンドユーザーがハッピーになる基盤を構築し、分散していても相互にデータがやりとりできる、そのような環境が今後、自律分散型を目指していく、そんな未来を予見されているような論文であり、考え方であると理解しました。この図のようにデータの多様化だけでなく、ユーザーニーズも多様化していくので、データ基盤もメッシュ化していくと言えるのではないでしょうか。
本記事は後編へと続きます。
https://www.ashisuto.co.jp/cm/pr-blog/20230313_mds.html
<執筆者のご紹介>

板木 栄樹
CX本部 新事業共創推進室
1987年入社。フィールド技術、技術マネージャを経て、2011年より新規取扱製品の開拓ミッションに専任。IT関連メディア、ベンチャーキャピタル、各国大使館、その他の各種情報ソースより、年間約200社のソフトウェアベンダーを調査、そのうち数十社と直接コンタクトを行っている。

松山 晋ノ助
CX本部 新事業共創推進室
2008年にアシストに入社。新BI製品の立ち上げから約10年活動し、2019年にアシスト初代BIマイスターに任命され、お客様のデータ活用に関わるご相談や提案にも対応。現在はアシストマイスターとして活動しながら、既存製品・事業に関わらず様々な分野の情報を得ながらお客様とのビジネス共創に従事。世界で日々生み出される新技術、新製品の発掘・育成・研究に明け暮れる日々。同時に次世代IT基盤を担うお客様との共同検証や、社内おける新しい文化の醸成などパワフルに活動中。最近はWeb3、NFTに明け暮れる。
ページトップへ戻る