
みなさんは、データの加工、特に「文字列の処理」に手間取った経験はありませんか?
「このテキストの中から特定のパターンの文字だけ抜き出したい…」
「複数の表記の揺らぎを一度に直したい…」
そんな悩みが、今回新たに追加された正規表現関数で解決できるかもしれません。
この記事では、これまでQlik Senseでは使えなかった正規表現関数の使い方と実用例を解説します。
目次
※本記事は「2025年7月時点のQlik Sense SaaS」で作成しています。
オンプレミス版ではQlik Sense Enterprise on Windows May 2025から正規表現関数が使用できるようになりました。
なぜ今、Qlik Senseで正規表現なのか?
多くのツールで標準機能となっている正規表現が、Qlik Senseでも実装され、多くのユーザーの方に利用いただけるようになりました。 実装を期待されていたユーザー様もいらっしゃるのではないでしょうか。
今回の正規表現関数の実装により、複数の文字列関数を何重にも組み合わせ、複雑な数式で対応していた以下の様な場合に、単純な数式で対応できる可能性があります。
・表記の揺らぎを統一する
・複雑なパターンを持つ文字列を抽出する
この記事では、Qlik Senseで正規表現をどう活用するかに焦点を当て、具体的な関数と実用例を解説します。
<Qlik Sense 正規表現関数の一覧(一部抜粋)>
関数名 | 機能 |
|---|---|
ReplaceRegEx★ | 対象の文字列に対して、指定された正規表現パターンに一致する文字列を指定した文字列に置き換えます。 |
ExtractRegEx★ | 対象の文字列に対して、指定された正規表現パターンに一致する文字列を抽出します。 |
CountRegEx★ | 対象の文字列に対して、指定された正規表現パターンの出現回数を返します。 |
MatchRegEx | 対象の文字列に対して、引数に指定された正規表現パターンと比較し、一致する正規表現パターンの位置を返します。 |
★・・・今回詳しくご紹介する正規表現関数です。
ほかの関数の詳細は、以下のメーカーヘルプをご覧ください。
ロード スクリプトとチャートの数式での正規表現の使用
https://help.qlik.com/ja-JP/cloud-services/Subsystems/Hub/Content/Sense_Hub/Scripting/regular-expressions-qlik-analytics.htm
正規表現関数の使い方と実用例3選
今回は、以下のサンプルデータを使って解説します。
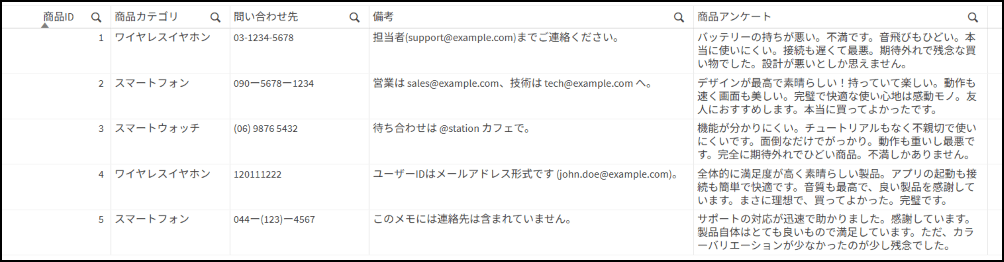
【実用例1】表記の揺らぎの統一
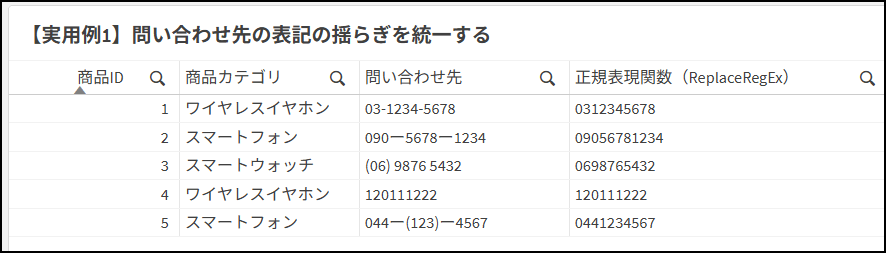
サンプルデータの「問い合わせ先」項目には、「-(半角ハイフン)」「ー(全角ハイフン)」「( )(括弧)」やスペースなど、入力者による表記の揺らぎが存在します。 これらについてチャート上の数式で、「03-1234-5678」を「0312345678」のように数字のみの形式に統一するには、ReplaceRegEx関数が便利です。
<従来の方法>
もし、従来の文字列関数で対応する場合、以下のように網羅する記号をすべて引数に指定する必要がありました。
▼記述例
=PurgeChar( 問い合わせ先,'ー-() ')<正規表現関数を使った方法>
正規表現関数を使えば、半角数字以外の文字を表すメタ文字「\D」(※)を使用することで、シンプルな記述で空文字への置換ができます。すべての表記の揺らぎを考慮して、いろいろな記号を指定しなくても済みます。
※補足
メタ文字とは、正規表現の中で特別な意味を持つ記号や文字です。「\D」のほかにも「\t」(タブ文字)「?」(直前のパターンの0~1の繰り返し)など様々なメタ文字があります。
メタ文字に使用される「\」は半角のバックスラッシュを表しますが、日本語のWindows環境では、半角の円マークとして表示されます。メタ文字の詳細は一般情報をご確認ください。
▼記述例
=ReplaceRegEx (問い合わせ先, '\D', '')<出力結果>
<構文>
ReplaceRegEx (text, regex, to_str [, occurrence])text:対象となる元の文字列または項目名
regex:検索する正規表現パターン
to_str:置換後の文字列
(occurrence):省略可能な引数。0を指定(初期設定)すると、一致するすべての文字列を置換します。0以外の正の値を指定すると、左から何個目の文字列を置き換えるかを指定できます。負の値を指定すると、右から何個目かを指定できます。
【実用例2】特定のルールに沿った文字列の抽出
サンプルデータの「備考」項目には、1つのデータにメールアドレスが最大2つ含まれています。 このメールアドレスをそれぞれ抽出してみましょう。
<正規表現関数を使った方法>
ExtractRegEx関数とメールアドレスのパターンを使って、1番目と2番目のアドレスをそれぞれ抽出します。
▼メールアドレス1の抽出
=ExtractRegEx(備考, '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}', 1)▼メールアドレス2の抽出
=ExtractRegEx(備考, '[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}', 2)シングルクォーテーションで囲っている以下の部分が、メールアドレスの正規表現にあたります。
「'[a-zA-Z0-9._%+-]+@[a-zA-Z0-9.-]+\.[a-zA-Z]{2,}'」
赤字で記載している数式末尾の数値は、何番目のメールアドレスを抽出するかを指定しています。もし、メールアドレスがない場合は、NULL値が返されます。
<構文>
ExtractRegEx (text, regex [, field_no])text:対象となる元の文字列または項目名
regex:検索する正規表現パターン
(field_no):省略可能な引数。 何番目に一致した文字列を抽出するかを指定します。 初期設定は1です。
<出力結果>

※ただし、以下のようなデータの場合、想定した抽出ができない場合があります。
▼抽出できないパターン
【メールアドレス前に日付がある場合】
2025/07/28sales@example.com
出力結果⇒28sales@example.com
【メールアドレスが連続した場合】
sales@example.comtech@example.com
出力結果⇒comtech@example.com
【実用例3】テキストの感情分析
「商品アンケート」のテキストデータから、顧客がどのような評価をしているかを分析したい時にも正規表現関数が便利です。
<正規表現関数を使った方法>
CountRegEx関数を使い、アンケート文中のポジティブな単語とネガティブな単語の出現回数をそれぞれカウントします。ここでは、「|」(または)を使って複数のキーワードを一度に指定します。
▼ポジティブな単語のカウント
=CountRegEx(商品アンケート, '満足|素晴らしい|感謝|最高|良い|よかった|使いやすい|便利|簡単|助かる|完璧|快適|おすすめ|リピート|買ってよかった')
▼ネガティブな単語のカウント
=CountRegEx(商品アンケート, '不満|悪い|残念|改善|使いにくい|分かりにくい|面倒|遅い|重い|壊れた|もう少し|動かない|ひどい|最悪|期待外れ|がっかり|もっと|高い|気になる')
これにより、各商品に対する顧客の感情を定量的に把握し、アンケート分析に役立てることができます。
<構文>
CountRegEx (text, regex)text:対象となる元の文字列または項目名
regex:検索する正規表現パターン
<出力結果>

注意点
正規表現関数を使用するにあたり、2点の注意点があります。ご認識いただいたうえで、実装をご検討ください。
【パフォーマンスについて】
正規表現関数は非常に有効な関数ですが、正規表現関数を使用しない場合と比べて、多くのリソースが消費され、パフォーマンスが低下することがあります。
文字列関数をネストしなくても済むような単純な処理を行う場合は、文字列関数の使用を検討しましょう。
【一般的な正規表現との差異について】
一般的に製品により正規表現での検索パターンの動作が異なることがあります。
他のツールで検証した正規表現パターンでもQlik製品上で動作を確認してから、ご利用ください。
さいごに
今回は、Qlik Senseに新しく導入された正規表現関数についてご紹介しました。 これまで諦めていた複雑な文字列の処理や、テキストデータからの感情分析など、正規表現関数で新たな分析の可能性が広がるかもしれません。
皆さんのデータ分析の際のお役に立てれば幸いです。
この記事を書いたスタッフ

株式会社アシストテックフェイス サポートサービス技術統括部
山部 晃太
株式会社アシストテックフェイス サポートサービス技術統括部
山部 晃太