








- Oracle Cloud
- Oracle Database
気になるテーマから学べる!無料オンデマンド動画「OCI入門者向けウェビナー」のご紹介
OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。
![]()






|
|
アシストは1987年よりOracle Database製品の取り扱いを開始し、教育、技術支援、サポートを提供しています。Oracle Databaseはシステムの基幹となるソフトウェアであるため、ミッションクリティカルなシステムに対応できる24時間365日のサポートが必要となります。2014年、弊社サポートセンターでは1万件以上のOracle Database製品に関するお問い合わせをいただきました。お問い合わせの内容は様々ですが、運用中に発生したトラブルに関するお問い合わせの中でも早期解決のご要望が高いのは、データベースへの「接続障害」が発生したケースです。
接続障害を解決するには、接続障害の発生状況を正確に把握し、どの部分で問題が発生しているのかを特定した上で、調査に必要な情報を素早く収集することが重要です。接続障害が発生した場合に何を確認すれば早期解決が期待できるか、サポートセンターにお問い合わせをいただいた事例を基にご紹介します。
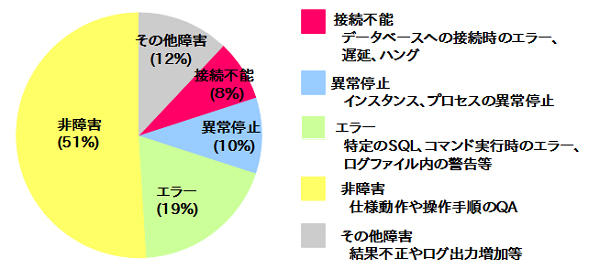
2014年に弊社サポートセンターにいただいたお問い合わせを内容ごとに分類したものが図1です。製品の使用方法についてのお問い合わせといった非障害と、運用中に何かしらの問題が発生したトラブルのお問い合わせの割合はほぼ同一です。
|
図1:2014年お問い合わせ分類 |
トラブルに関するお問い合わせを操作時のエラー、異常停止、接続障害、その他で分類すると接続障害は大きな割合を占めているものではありませんが、他の障害に比べて緊急対応のご要望をいただくケースが多い傾向にあります。
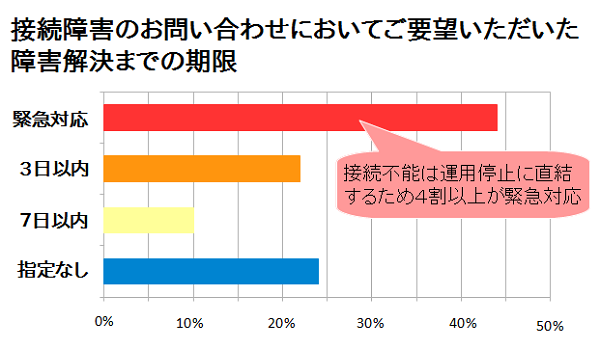
本稿では、サポートセンターに「データベースに接続ができない」とお問い合わせをいただいた事例を接続障害と定義しています。接続障害は多くのケースで緊急対応をご要望いただくと前述しましたが、実際の割合を示したのが図2です。
|
図2:接続障害時にご要望いただいた期限の割合 |
弊社サポートセンターではお問い合わせの背景を理解した上でご要望の期限内に報告を差し上げられるよう、お問い合わせをいただいた際に解決までの期限をお伺いしています。接続障害はデータベースそのものが使用できない=本番環境の場合はサービスが提供できないため、4割以上のお問い合わせで一刻も早く解決して欲しいといった緊急対応のご要望をいただいています。
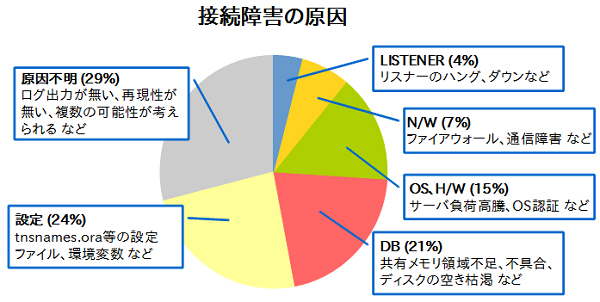
次に、調査の結果、接続障害はどの部分に問題があったのかを示したのが図3です。最も割合の多い“設定”に起因した接続障害でも24%であり、接続障害の原因が多岐にわたっていることがわかります。
|
図3:接続障害の原因 |
これらの原因についてそれぞれ詳しく見ていきましょう。
“設定”とは、具体的には以下のような設定に依存して接続障害が発生しているケースです。
次に多いのが“DB”です。これは接続障害の原因がデータベース側にあり、具体的には以下のようなケースが該当します。
その他にも図3に示しているように、サーバの負荷やリスナーの動作に起因して接続が行えないケースや、原因解明に至らなかったといったケースがあります。
クライアント、サーバ、データベース、ネットワークを1つずつ確認していくと調査に膨大な時間がかかり、早期解決は望めません。早期解決のためには問題発生箇所を特定し、調査に必要な情報を迅速に収集することが重要です。次の章では接続障害が発生してしまった場合に確認するポイントを解説します。
接続障害を解決するためには、図4に記載されている作業を迅速に行う必要があります。
|
図4:早期解決のために行う作業 |
まずはじめに、接続障害がどのように発生しているのかを正確に把握します。接続ができないというのは接続時にエラーが発生しているのか、応答が返らないのか、最終的に接続はできるが時間がかかっているのか、といった接続障害の具体的な内容を確認します。
そして、一時的な接続障害の可能性や環境に依存した問題か否かの切り分けのために接続障害が発生したクライアント、接続方法、ミドルウェアから正常に接続が行えた実績があるかを確認します。
いずれのクライアントからも接続できないのであれば、この時点ではネットワークやサーバ、データベースの広範囲で原因を考える必要がありますが、特定のクライアントやミドルウェアからのみ接続できないということであれば調査項目を絞ることができます。
また、今まで正常に接続できていたのにあるタイミングから接続障害が発生したということであれば、具体的にいつから接続障害が発生していたのかを確認します。
障害発生時刻を明確にすることで確認するログファイルの時間帯を絞ることができ、正常に接続ができていた時間帯の出力と比較ができます。その際、障害発生時刻より前にクライアント、サーバ、データベースで設定の変更を行っていないか、普段と異なる処理の実行がないかも確認します。
接続障害がどの部分で発生しているかを切り分けることは調査を行う上で重要なポイントですが、その前にクライアントがデータベースに接続するまでの流れと、各箇所で発生する可能性のあるエラーを整理しましょう。
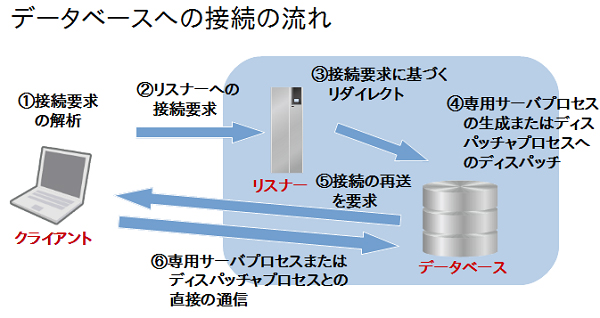
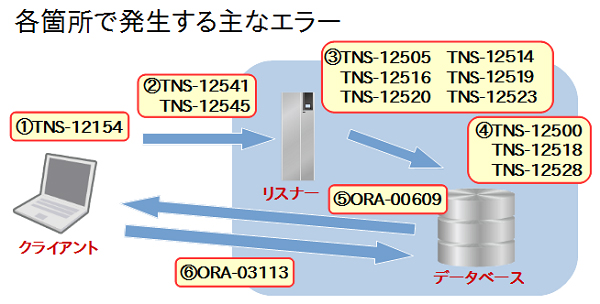
図5ではOracle Clientが導入されているクライアント端末から、リスナーを経由してデータベースに接続を行う一連の流れを表しています。
|
図5:データベースへの接続の流れ |
まず、「①」クライアント側で接続要求の解析が行われます。そして、「②」その解析した結果のホストやポート番号を基に、リスナーに対して接続要求を行います。「③」接続要求を受け取ったリスナーは要求の内容に基づいてデータベースに接続要求をリダイレクトします。その後、「④」接続の形態が専用サーバ接続であれば専用サーバプロセスが生成され、共有サーバ接続の場合では既に稼働しているディスパッチャプロセスに接続を割り当てます。「⑤」専用サーバプロセスまたは、ディスパッチャプロセスはクライアントに対して接続の再送を要求し、「⑥」再送を受け取ったクライアントは直接データベースのプロセスに対して通信を行います。以降の通信ではリスナーは介しません。
この一連の流れで発生するエラーの例を示したものが図6です。
|
図6:データベースへの接続で発生するエラーの例 |
エラーのほとんどがTNS-12XXXというエラーですが、このTNS-12XXXというのはOracle Netで発生したエラーであることを表しています。TNS-12XXXのエラーのいくつかは、ORA-12XXXとしてクライアントやアラート・ログに出力されることもあります。
たとえば③のTNS-12505(リスナーは接続記述子で指定されたSIDを現在認識していません)はサーバ側のリスナー・ログに記録されるエラーですが、SQL*Plusから接続を行ったクライアントにはORA-12505と出力され、これらはまったく同じ意味を表します。
エラー発生箇所ごとの接続障害をもう少し詳しく解説していきます。
図6の①にあるTNS-12154ですが、このエラーはクライアント側での接続識別子の名前解決に失敗した場合に発生するエラーです。
SQL*Plusから接続を行う場合、ユーザ名とパスワードの後に入力した接続識別子とtnsnames.oraに記載されている接続識別子が一致していなければなりませんが、図7のように接続時に指定した接続識別子がtnsnames.oraに存在しない場合にTNS-12154が発生します。
|
図7:クライアントの設定に依存する接続エラー |
よくあるケースは接続時とtnsnames.oraに記載している接続識別子のどちらかに記載ミスがあることでの不一致ですが、複数バージョンのOracle Clientがインストールされている環境で環境変数の設定が適切ではなく、使用したいtnsnames.oraとは別のディレクトリ(ORACLE_HOME)にあるtnsnames.oraを読み込んでいるケースも弊社にいただくお問い合わせとしては多く確認できています。
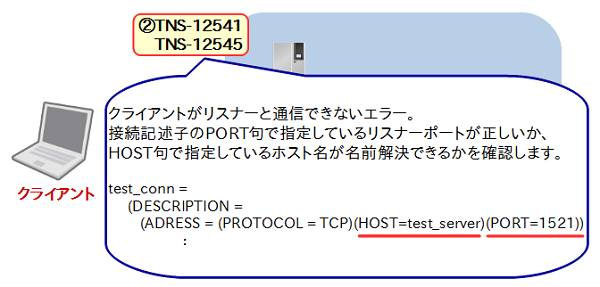
クライアントからリスナーに接続する際に発生する可能性があるのが図8に記載しているTNS-12541/TNS-12545といったエラーです。
|
図8:クライアントとリスナー間で発生するエラー |
ここでもtnsnames.oraの内容を記載していますが、この例ではtest_serverというホストの1521ポートでリスナーがリスニングしているはずですが、接続先サーバのリスナーが1521以外のポートで起動している場合やtest_serverの名前解決に失敗した場合にはこれらのエラーが発生します。
また、ネットワークの負荷などに起因して接続先のホストまで到達できず、接続がタイムアウトした場合にはTNS-12535のエラーが発生する可能性があります。
リスナーが認識しているデータベースの状態が正しくない、データベースが正常な状態ではないようなケースで、データベースへのリダイレクト時に問題があった場合にはこれらのエラーが発生する可能性があります。
具体的にはクライアント側のtnsnames.oraのSIDに指定している値と、サーバ側のlistener.oraのSID_NAMEに指定している値は同じである必要がありますが、この値が一致していない場合や、接続先のインスタンスが起動していない場合などが該当します。
このようなケースではクライアント、サーバの設定ファイルの見直しや、lsnrctlのstatusやservicesといったコマンドを使用して正常に接続先データベースの情報が登録されているか、接続を受け付けているかといった確認を行います。
リスナーからのリダイレクトを受け、クライアントと通信を行うプロセスを生成する際に発生する可能性があるのがこれらのエラーです。
主な原因としてはサーバのリソース不足や、起動プロセスが初期化パラメータprocessesで指定している上限に達している状態で新たに接続を行ったようなケースで発生します。
調査の観点としてはOSコマンドによるリソースの確認や、アラート・ログなどからデータベースの状態をチェックします。
リスナーがサーバプロセスを生成し、クライアントに再接続を要求する過程で失敗した場合に発生するのがORA-00609です。この場合、接続を要求したクライアントが異常終了していないか、ネットワークに問題が発生していないかといった確認を行います。
接続確立後、クライアントとデータベース間の通信が何かしらの理由によって切れてしまった場合にはクライアント側にORA-3113が返ります。
Oracle側で原因として考えられるのが、接続先のサーバプロセスがORA-600やORA-7445などで異常終了してしまったケースです。この場合、クライアントにはORA-600やORA-7445が返らずORA-3113が返ることがあります。
クライアントでORA-3113を検知した場合には、データベース側で同時刻に何かエラーが発生していないか、データベースが停止していないかといった確認を行います。
その他、クライアントとサーバのネットワークが物理的に切れてしまった場合にもこのエラーが発生する可能性があるため、ネットワークの状態も確認します。
エラーを伴っている場合は問題発生箇所がある程度推測できますが、それでも障害の要因は複数考えられる場合がありますので、次の章で紹介する問題発生箇所を特定する方法で切り分けを行う必要があります。
接続障害が発生した際には、問題発生箇所を特定するために図9の一部、もしくはすべての確認を行います。
|
図9:接続障害の問題発生箇所を切り分けるポイント |
図9の①~③はOracle Netの問題かどうかの切り分けです。pingが失敗する場合にはOracleのレイヤーではなく、ネットワークの問題である可能性が高いと言えます。
更に、サーバ上からのリスナー経由の接続を行い、ループバックアダプタなどを使って外部のネットワークを通さずに接続した場合に正常に接続ができるのかを確認します。外部のネットワークを通さなければ接続できるという場合には、クライアント、サーバ間のネットワークを疑っていくことになります。
また、問題が発生しているアプリケーションとは異なるアプリケーションやSQL*Plusからの接続は可能な場合には、使用しているアプリケーションやミドルウェアの問題の可能性を疑います。
図9の④~⑥はリスナーの問題かどうかの切り分けです。リスナーは正常に起動しているか、サービスは登録されており接続を受け付けているか、そして、ローカル接続では正常に接続が行えるかといった観点で確認を行います。
図9の⑦~⑨は接続方式やデータベースの問題かどうかの切り分けです。専用サーバ接続では正常に接続が行え、共有サーバ接続では失敗するということであれば共有サーバプロセス、ディスパッチャプロセスなどに依存した問題が発生している可能性を疑います。
また、特定クライアントからのみ接続が失敗するということであれば、クライアント側の接続定義情報が他のクライアントと異なっていないかといった点を確認します。
一般ユーザでは接続が行えず、SYSなどの管理ユーザでは接続が可能ということであればネットワークやリスナーではなく、データベースの内部的な問題である可能性を疑います。
これらの項目を確認することで、たとえば、DBサーバへのpingは正常に行えており、ローカル接続も問題なく行えるが、SQL*Plusからのリスナーを経由した接続でエラーが発生するということであれば、クライアント側の接続定義かリスナーに何かしら問題がある可能性が高い、といったように問題発生箇所の切り分けが行えます。
接続障害が発生した際に必要なファイルとコマンドについて解説をします。クライアント側から調査を行うために使用するファイルとコマンドは次のとおりです。
図9の①に記載のとおり、クライアントからDBサーバに対してpingが通るかを確認し、ネットワークの問題かどうかの切り分けを行います。この際、tnsnames.oraで指定しているホスト名の名前解決に問題がないかも確認するためにホスト名指定、IPアドレス指定の両方で確認を行います。
クライアント側のOracle Netに関連するファイルにはtnsnames.oraとsqlnet.oraがあります。tnsnames.oraについては前述したとおり、接続時に指定する接続識別子の解決に使用するファイルです。そして、sqlnet.oraはOracle Netにおける通信の設定を定義するファイルです。
たとえば、接続識別子の解決はデフォルトの設定ではクライアント上のtnsnames.oraを最優先に使用しますが、sqlnet.oraでNAMES.DIRECTORY_PATHというパラメータを設定することでディレクトリ・サーバを優先させることも可能です。他には、接続時の認証に関連するパラメータとしてAUTHENTICATION_SERVICESがありますが、このパラメータを変更したことでOS認証が失敗し、お問い合わせをいただくことも少なくありません。
そのため、図9の⑨の確認で特定のクライアントからの接続のみ失敗するような状況が確認できた場合には、接続が成功するクライアントと、失敗するクライアントの接続に関する設定を比較するためにtnsnames.oraだけでなくsqlnet.oraの情報も必要です。
また、特定のクライアントのみ失敗するようなケースではOracle Netの設定ではなく、環境変数の設定が異なっている可能性も考えられるため、envコマンドなどで環境変数の設定も確認します。
クライアント側のログファイルとしてはsqlnet.logがあります。図9の⑥の確認でリスナー経由の接続のみ失敗するようなケースではsqlnet.logを確認します。
出力先は次のいずれかですが、sqlnet.oraのADR_BASEパラメータや環境変数ORACLE_BASEの設定有無により異なりますので、ご利用環境ではどこに出力されているか、接続障害発生時に備えて事前に把握する必要があります。
サーバ側で接続障害の調査に必要なファイルとコマンドは次のとおりです。
サーバ側でも調査に使用するファイルは基本的にクライアントと同じですが、接続を受け付けるリスナーがあるため、図9の④と⑤を確認するために定義ファイルのlistener.ora、クライアントからの接続要求やエラーが出力されるリスナー・ログ、そして、リスナーの現在の稼働状況やサービスの登録状況の確認を行うためのlsnrctlコマンドの結果も確認します。
なお、sqlnet.logの情報はサーバ側ではOracle Databaseのバージョンが11gR1以降であればアラート・ログに出力されます。図9の⑥でローカル接続でも接続障害が発生する場合にはデータベースの問題に起因している可能性が高いためアラート・ログも確認します。
接続障害に関する問題が発生した際にこれらのファイルやログ情報が、ご利用環境のどのディレクトリに出力されているかを事前に把握しておき、素早く収集を行うことが問題解決までの時間短縮に繋がります。
次の章ではそれぞれのログファイルの出力内容やコマンドの実行結果について解説します。
接続障害の調査で使用する各ログファイルの出力とコマンドを解説します。各エラーや出力内容について個別に取り扱うと内容が膨大になってしまうので、ここではどのような情報が確認できるかといった概要をご確認ください。
図10はエラーを伴った接続障害が発生した際のsqlnet.logの出力例です。末尾の出力は接続元クライアントの情報です。この内容から2014年9月25日にtest_sというクライアントからの接続がTNS-12535で失敗しているということがわかります。
|
図10:sqlnet.logの出力例 |
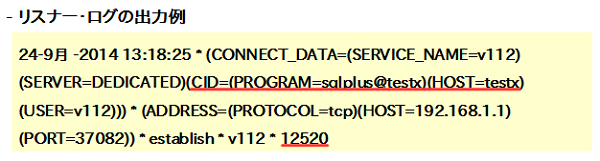
リスナー・ログはクライアントからの接続要求を受け付ける度にクライアントの情報と、その接続が成功したのか、失敗したのかが出力されます。図11はエラーで接続要求が失敗しているケースです。
|
図11:リスナー・ログの出力例 |
この例では9月24日にtestxというマシンからSQL*Plusでの接続要求があったことが読み取れます。そしてこの一番最後の12520という箇所がリターンコードです。この例ではTNS-12520というエラーが発生して接続に失敗したことがわかります。正常に接続できた場合は0と出力されます。
リスナー・ログは接続要求の度に情報が出力されるため、肥大化しやすいファイルの1つです。接続障害の調査のためにリスナー・ログのご提供を依頼すると数GBまで肥大化しており、必要箇所の抜粋や送付に時間がかかってしまうケースもあります。
リスナー・ログのサイズが4GBを超えることで接続障害が発生するという事例もありますので、定期的にローテーションを行う必要があります。
リスナーの状態を確認するためにはlsnrctlというユーティリティを使用します。オプションとして“status”、“services“を用います。
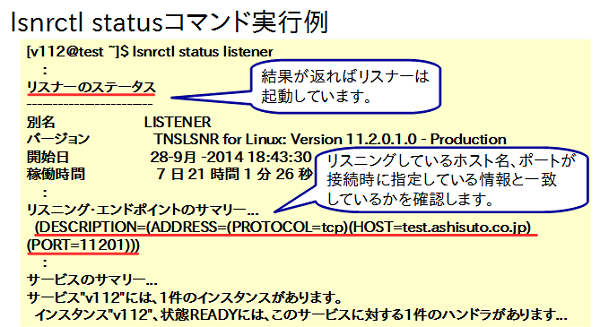
statusオプションではリスナーが正常に起動できているか、いつから起動しているのか、どのポートでリスニングしているのかといった情報が確認できます。
図12のような結果が返ってくればリスナーは起動しています。TNS-12541(リスナーがありません)のようにクライアントからリスナーに対する接続要求の時点でエラーが返るようなケースではクライアントのtnsnames.oraで指定しているホスト名やポートの値がリスニング・エンドポイントの内容とマッチしているかを確認します。
|
図12:lsnrctl status実行例 |
servicesオプションではリスナーに登録されているサービスの情報を確認できます。主に接続先のインスタンスのサービスが正常に登録されているかや、どのようなハンドラ(ディスパッチャ、専用サーバ)が登録されているかを確認します。
図13では、v112というサービスが登録されており、v112というインスタンスが紐付いています。“状態”の箇所は動的サービス登録を行っていると自動的にインスタンスの状態が通知され値が変わります。READYは正常な状態です。
|
図13:lsnrctl servicesコマンド実行例 |
インスタンスごとにハンドラの情報も表示されます。専用サーバの場合はDEDICATED、共有サーバ接続の場合はD00xのようにディスパッチャ名が出力されます。
ハンドラごとにも状態が表示されており、正常な状態ではreadyですが、たとえば、接続先データベースで初期化パラメータprocessesで指定した値までプロセスが起動しており、新規にプロセスを起動できないようなケースではblockedに変わります。
では、具体的にどのような問題を接続障害としてお問い合わせいただいているのか、いくつか事例を紹介させていただきます。
この事例ではアプリケーションからデータベースに対して接続ができない状態が続いているというお問い合わせをいただきました。サポートセンターからは調査方針検討、影響範囲を確認するために次の確認を依頼しました。
その結果、接続は応答が返らないがpingは正常に通ること、いずれのクライアントからでも同様であること、ローカル接続でも接続はできないとのことでした。ローカル接続でも失敗するという状況からネットワークの問題である可能性は排除し、データベースの問題を視野に入れアラート・ログの提供を依頼したところ「WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!」というメッセージが出力されていました。
ROW CACHE ENQUEUEというのは共有プールにロードされているディクショナリ情報にアクセスする際に必要な行キャッシュ・ロックのことです。データベースにログインする際にはユーザの情報を確認しますし、セッションを生成する際にセッションIDを採番することになりますので、内部的にはシーケンスも使用します。これらの情報を確認するために行キャッシュ・ロックを獲得します。
「WAITED TOO LONG FOR A ROW CACHE ENQUEUE LOCK!」は、その行キャッシュ・ロックの獲得が1000回失敗すると出力されます。リトライは3秒に1回行われますので、50分連続で失敗しつづけるとこのメッセージが出力されます。
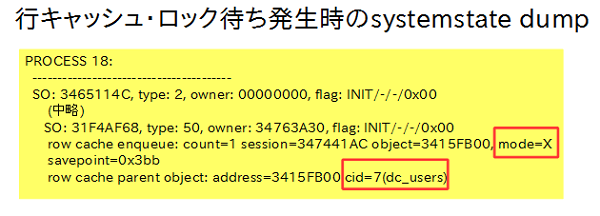
このメッセージが出力されるとデータベースでは自動的にsystemstate dumpを出力します。このsystemstate dumpにはその時点でのデータベース上のすべてのプロセスの情報が出力されていますので、出力内容から対象のロックを持っているプロセスと処理内容を特定して対応を検討します。
図14の例では、プロセス番号18のプロセスが排他モード(mode=X)でユーザに関するディクショナリ情報(dc_users)のロックを保持していることがわかります。
|
図14:systemstate dump出力例 |
一般ユーザで新規接続をする際には共有モード(request=S)でdc_usersのロックを要求しますが、排他モードとロックの互換性がないため、プロセス番号18がロックを解放しない限り新規接続は待機させられます。問題を解決するためにこのプロセス番号18の処理内容を特定し、セッションのKILLなどでロックを解放するといった対処を行います。
この事例ではユーザから見ると接続障害ですが、実際にはロック競合が原因でした。そのため、設定ファイルの見直しやネットワーク障害の調査、リスナー・ログを確認することでは解決できません。
次にご紹介するのはLinux上でのJDBC Thin Driverでの接続がタイムアウトするというお問い合わせです。このケースでは、同じJDBCでもOracle Clientを使うJDBC OCI Driverや、SQL*Plusでは問題がありませんでした。
接続障害が発生している状態でスレッドダンプを取得していただき、スタックトレースを確認したところ、SecureRandom.nextBytesというメソッドを使用していることが確認できました。
Linux上でのJDBC Thin Driverの接続では、ログイン時に乱数を生成するために/dev/randomを使用するSecureRandom.nextBytesというメソッドを内部的に使用します。/dev/randomは環境ノイズをエントロピー源としており、この環境ノイズは主にキーボードの入力などの入力デバイスの操作によって発生します。
そのため、たとえばマシンがサーバルームにあって普段は誰もキーボードには触れないような場合にはエントロピーが枯渇し、/dev/randomは延々と待機し続けるため、ログイン処理がハングし、接続障害が発生します。
この問題の対応策は/dev/randomの代わりに/dev/urandomを使用する、もしくはLinuxにmgdパッケージをインストールするのいずれかです。
JDBC Thin Driverからの接続が乱数生成で待機する事象についてはオラクル社からも情報が提供されており、比較的お問い合わせの数も多いトラブルのため「JDBCアプリケーションでタイムアウトが発生している」とお問い合わせをいただくとピンときますが、「接続ができない」というお問い合わせですと、はじめから切り分けを行っていく必要があります。
いずれの事例も接続障害が発生した際に発生状況を正確に把握できるかが解決までの時間に影響します。どの部分で問題が起きているのかを正確に把握することで、適切な情報収集、合致する可能性のある事例や情報の確認を素早く行うことができます。
ご紹介した事例はログの出力や発生時の状況が明確なため原因が特定でき、解決したケースですが、ログ出力のないケースや発生しているエラーから複数の要因が考えられ、解決に至らないケースもあります。
既存の情報から原因追及に至らなかったケースでは、次回再現時にOracle Netのトレース機能を使用した調査を検討します。クライアント、サーバ双方にトレースの設定を行うことでパケットのやり取りを確認することができます。
出力例は図15のとおりで、左側に各ステップでのタイムスタンプが出力されています。パケットがどの時点で送受信されていて、どの箇所で時間がかかったかを見ていくことになります。
|
図15:Oracle Netトレースの出力例 |
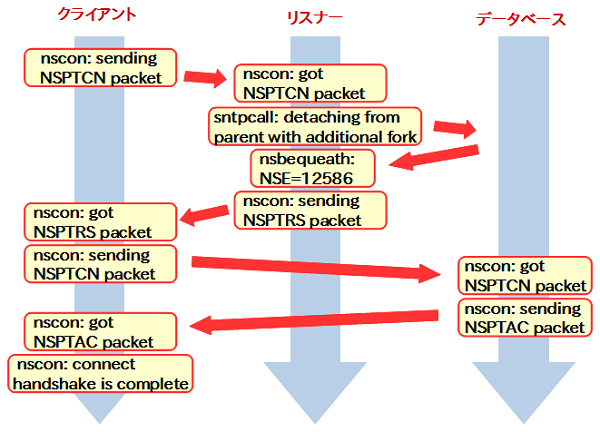
図16はクライアントから専用サーバ接続でデータベースに接続を行った場合のパケットの流れをOracle Netトレースの出力から確認した例です。
|
図16:接続完了までのパケットの流れ |
まずクライアントからリスナーに接続要求(NSPTCN)を行い、リスナーはデータベースに対してプロセスの生成(fork)を要求します。プロセスが生成されるとデータベースはリスナーに応答を返します。
リスナーはクライアントに、接続の再送要求(NSPTRS)を送ります。再送要求を受けたクライアントはデータベースのプロセスと通信を行い、データベースのプロセスが応答を返した時点で接続が完了します(handshake is complete)。
一連の流れの中でパケットの送信に時間がかかっている箇所や止まっている箇所が確認できれば、どこで問題が発生しているかの特定が行えるため調査方針を検討することができます。
ただし、Oracle Netのトレース機能を有効にすると多くのトレース・ファイルの生成、およびファイルへの書き込みが行われるため非常に負荷がかかります。
設定方法はNet Services管理者ガイドにも記載されていますが、通常運用時に設定を行うとご利用環境のパフォーマンスを損なう要因となりますので接続障害に備えた定常的な設定は現実的ではありません。開発環境での検証目的や接続障害の調査でサポートセンターからの指示があり、一時的に有効にする以外では設定いただかないようお願いします。
接続障害はクリティカルな問題でありながら調査範囲が非常に広く、原因の特定までに時間を要することがあります。
接続ができないという事象で確認する項目や、調査する設定ファイルとログ情報を再掲します。
【接続障害の内容を把握するために確認する項目】
【問題発生箇所の切り分けを行うために確認する項目】
【接続定義確認のための設定ファイル】
【調査のために必要なログファイル】
【調査のために必要なコマンド】
接続障害は発生しないことがベストですが、万が一発生してしまった場合には今回ご紹介したような発生状況の把握、問題箇所の切り分け、情報収集を迅速に行うことが早期解決のためには重要です。本稿が接続障害とは何か、どのような情報が原因特定には必要なのかといった理解の一助となり、解決の早期化に繋がれば幸いです。
|
|
大野 高志
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

