




- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
インメモリのデータベースはサーバが落ちたら終わり。そんなふうに考えていた時期が私にもありました。でもOracle Database In-Memoryにはそうならないための構成が用意されているのです。検証シリーズ最終回となる今回は、実際に障害を発生させてその動きを追っていきます。
セミナーや勉強会などで、「Oracle Database In-Memoryはメモリ上にデータがあるのだから、サーバがダウンしたら復旧が大変ではないか?」というご質問をいただくことがあります。仕組みを考えればこうした懸念は当然です。サーバがダウンすればもちろんRAMの中身は消えますし、インスタンスがダウンすればデータベースから見たキャッシュは空になってしまいます。データの整合性はどうなるのか、インメモリの状態に復旧するまでどの程度かかるのかといった情報は、採用を検討する上で必ず抑えておかなければいけません。
まず、データの整合性についてですが、Oracle Database In-Memoryでは更新処理にこれまでどおりデータベース・バッファ・キャッシュを使用しています。もしサーバがダウンしたとしてもクラッシュリカバリによってデータの整合性が維持されるため、Oracle Database In-Memoryならではの懸念事項というのはありません。それよりも問題なのは、クラッシュリカバリが終わってもディスクからメモリ上にデータを配置(ポピュレーション)し直さなければ、インメモリの状態には戻らないということです。
これまでの検証でご紹介したように、ポピュレーションは行フォーマットから列フォーマットへの変換と圧縮を行うため、それなりに時間のかかる作業です。ポピュレーションの途中でもクエリを発行できますが、部分的にインメモリになった状態では本来期待する性能を発揮することができません。
|
図1:可用性構成ではない場合のOracle Database In-Memory |
これはOracle Database In-Memoryに限った話ではなく、インメモリ技術全般に当てはまります。メモリにデータを配置する以上、常に「消える」というリスクと戦わなければいけません。特にクリティカルなシステムの場合は、ダウンタイムを短く抑えるための可用性構成を組めるかどうかが、採用可否を大きく左右します。
Oracle Databaseの代表的な可用性構成と言えば、Real Application Clusters(RAC)です。RACは全てのサーバ(ノード)で読み取りと書き込みが可能なアクティブ-アクティブ型のクラスタ構成なので、もし1台のノードがダウンしても生き残ったノードに接続すれば処理を継続できます。
Oracle Database In-MemoryはRAC上でも動作しますので、可用性を確保したい場合はRACの構成を選択するのが最も良い方法です。ただし、話はそれほど単純ではなく、各ノードのメモリ上でどのようにデータを保持するか、3つのパターンから選択する必要があります。それが以下の図です。
|
図2:Oracle Database In-MemoryをRAC上で使う場合の設定 |
「NO DUPLICATE」は、各ノード上のインメモリ・カラムストアにデータを分散します。データの複製を保持しないため、より多くのデータをメモリ上に配置できますが、例えば図のノード1がダウンしてしまうと、P1のデータにはインメモリでのアクセスができなくなってしまいます。
「DUPLICATE」と「ALL DUPLICATE」は、異なるノード上に複製を保持します。「NO DUPLICATE」と比べて使えるメモリ量は減ってしまいますが、いずれか一つのノードがダウンしたとしても別のノードに複製が存在するため可用性に優れています。ただし、この構成がとれるのは、Oracle Exadata Database Machine(Exadata)やOracle Database Applianceなどの、Engineered Systemsのみになっています。機材の選定と可用性のレベルが密接に関わってきますので、特に「DUPLICATE」と「ALL DUPLICATE」を選択する場合は注意が必要です。
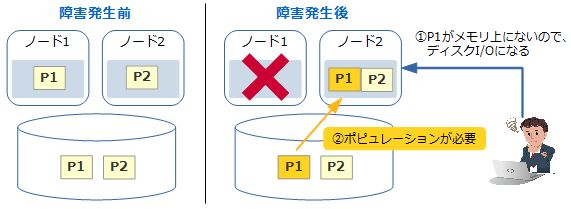
障害発生時の影響がどの程度異なるのか、前述の3つの設定パターンをそれぞれ検証してみます。「NO DUPLICATE」はメモリ上にデータの複製を持たないので、運悪くアクセスしたいデータを持っているノードがダウンしてしまうと、生き残ったノードに接続したとしてもディスクI/Oが発生してしまいます。
|
図3:NO DUPLICATEで障害が発生した場合の動き |
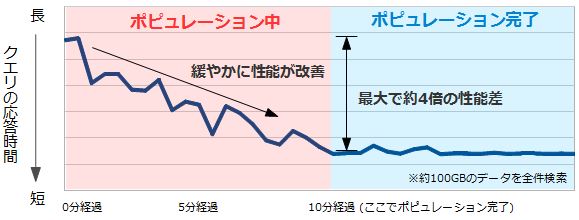
生き残ったノードではポピュレーションが自動的に始まるので、クエリを実行すると時間の経過とともに緩やかに応答性能が改善していきます。それでもポピュレーションが完了するまでは時間がかかるので、その間の性能劣化は覚悟しなければなりません。ポピュレーションの対象が多い場合は、頻繁にアクセスする表を優先的にポピュレーションするよう設定を行うなどの工夫が必要です。
|
図4:NO DUPLICATEでポピュレーションが完了するまでのクエリ性能 |
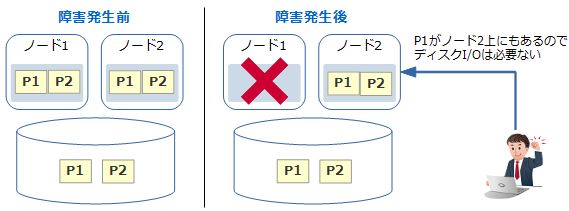
「DUPLICATE」の場合は、生き残ったノード上のインメモリ・カラムストア内にデータの複製があるため、そちらに接続すればディスクI/Oではなくメモリアクセスで処理を行うことができます。
|
図5:DUPLICATEで障害が発生した場合の動き |
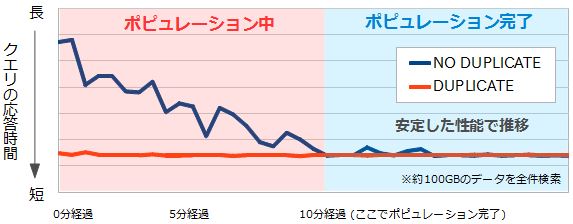
DUPLICATE をNO DUPLICATEの結果と並べてみると、その違いがはっきりと分かります。DUPLICATEの場合はポピュレーションを実行する必要がなくそのまま欲しいデータにアクセスが可能なので、NO DUPLICATEのように性能が落ちることはありません。以下のとおり、生き残ったノードに接続した直後から安定した性能で推移しています。
|
図6:NO DUPLICATEとDUPLICATEでのクエリ応答時間の比較 |
このように、RACの場合はインメモリ・カラムストアのデータを冗長で持たせるか/持たせないかによって障害発生時の影響度が大きく異なります。ポピュレーションの時間はどの程度か、ダウンしたノードのデータをポピュレーションできるだけのメモリサイズを確保できるかなど、クラスタが縮退することを想定した設計や動作検証をしっかりと行うことが、RAC とOracle Database In-Memoryを組み合わせる際の重要なポイントと言えるでしょう。
先ほど検証した「DUPLICATE」の設定は、ExadataやOracle Database ApplianceのEngineered Systemsでのみサポートされているので、Oracle Database In-Memoryの基盤としてExadataやOracle Database Applianceを評価・検討したいというケースが今後増えるかもしれません。ただし、ExadataやOracle Database Applianceには、メモリ以外のレイヤーに様々な高速化技術が備わっているため、それらとOracle Database In-Memory をどう使い分けていくのかを理解しておくことで、より正しく機材が選定できるようになります。
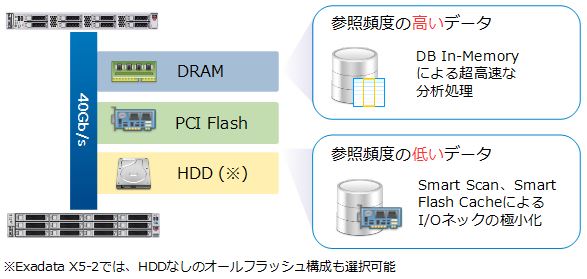
例えばExadataの場合、以下のようにメモリ、PCI Flash、ハードディスクという3つのレイヤーにデータを配置できます。メモリが最も高速なのは言うまでもありませんが、ハードディスクへのアクセスであってもInfiniBandネットワークやストレージ・サーバ上でデータを絞り込むSmart Scanが効果的に働くため、十分な性能が期待できます。さらに、最新のExadata X5-2では、オールフラッシュのストレージ・サーバも提供されています。性能要件を満たすにはExadataの技術で十分なのか、それともOracle Database In-Memoryが必要なのか、それぞれの機能を鑑みて十分に見極める必要があります。
|
図7:Exadataの高速化技術とOracle Database In-Memoryの棲み分け |
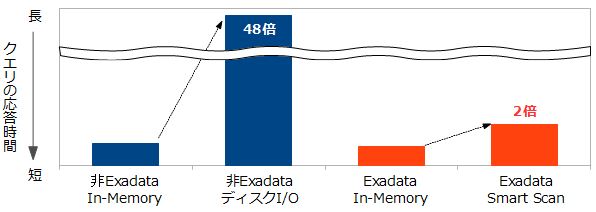
実際に、Exadataの環境を使ってOracle Database In-Memoryの有無でどの程度性能に差があるのか検証してみましょう。分かりやすいように、Exadataではない汎用的なIAサーバで同じ処理を実行した場合の結果と比較してみます。今回のクエリでは、約100GBのデータを全件検索しており、ExadataはオールフラッシュではないHDD タイプのモデルを利用しています。
|
図8:Oracle Database In-Memoryの有無による性能差 |
検証の結果を見ると、非Exadataの場合は大きく性能差が出ていますが、Exadataではその差が小さくなっています。今回のクエリではExadataのSmart Scanがよく効いており、ストレージ・サーバ側で処理対象のデータを絞り込むことでI/O量を削減し、応答時間を大幅に短縮しています。この結果はあくまで一例ですが、ExadataはOracle Database In-Memoryがなくても十分速いと捉えることもできます。
もちろん、Oracle Database In-Memoryでなければ実現できない性能要件も存在します。ExadataでOracle Database In-Memoryを使う場合は、頻繁にアクセスされるデータをメモリ上に置き、それ以外はハードディスクに置いてSmart Scanを使うといった棲み分けができます。両者は補完関係にあるので、データ量やコストなどを整理して適切な方法を選択しましょう。
皆さんがOracle Database In-Memoryの検証や評価を進める中で、本連載の内容が少しでもお役に立てば幸いです。
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.1
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.2
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.3
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.4
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.5
|
|
関 俊洋
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

