







- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
前回はOracle Database In-Memoryの仕組みを図解で解説しました。今回は実際にテーブルをインメモリ化して、検索処理の性能を測ってみます。Oracle Databaseにインメモリ+カラム型の技術が加わると、性能はどの程度向上するのでしょうか?
前回のおさらいになりますが、Oracle Database In-Memoryには以下の特徴があります。分かりやすく表現すると、「Oracle Databaseにカラム型のメモリ領域(インメモリ・カラムストア)を追加したもの」がOracle Database In-Memoryです。
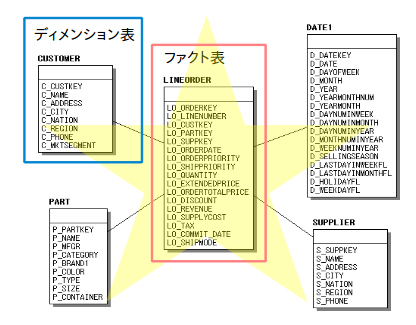
今回は、カラム型が得意とする検索処理を実行した時の性能を測っていきます。使用するハードウェアおよびOracle Databaseのパラメータは以下のとおりです。検証データはStar Schema Benchmark※を使って生成しており、テーブルのサイズは約70GB、レコード数は約6億です。
※Star Schema Benchmarkの詳細についてはこちら
をご参照ください。
|
表1:使用するハードウェアと初期化パラメータ |
|
図1:Star Schema Benchmarkのテーブル構成 |
まずは、各テーブルをインメモリ・カラムストアに読み込みます。この動作は「ポピュレーション」と呼ばれ、メモリに読み込む際にカラム型への変換や圧縮が行われます。ポピュレーションを行うには、テーブルに対してALTER文でINMEMORY属性を指定します。今回は優先度をCRITICAL、圧縮レベルをFOR QUERY LOWとします。
|
|
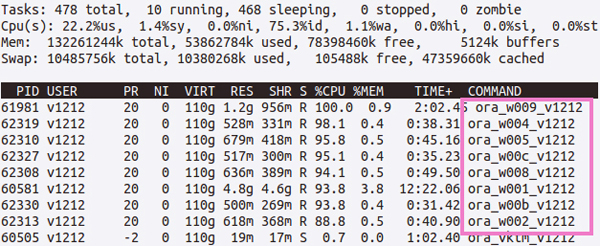
優先度をNONE以外に設定した場合、バックグラウンド・プロセスが2分間隔でポピュレーションのタスクを実行してくれます。OS上からは「ora_wNNN_<SID>」というワーカー・プロセスがポピュレーションを行っている様子が確認できます。
|
図2:ポピュレーション中のOS稼働状況 |
ポピュレーションはそれなりに負荷のかかる処理で、ディスクからデータを読み込むためのI/Oはもちろんのこと、圧縮のためにCPUのリソースを多く使用します。高負荷になるのが心配だという場合は、初期化パラメータのinmemory_max_populate_serversでワーカー・プロセスの数を変更することができます。
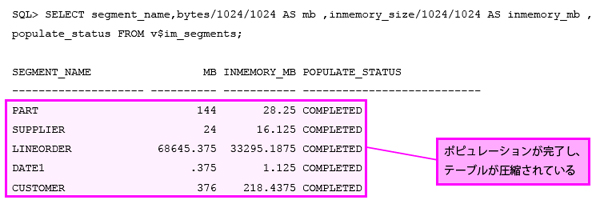
OS上からワーカー・プロセスが消えたら、ポピュレーションは完了です。今回は約70GBのテーブルをポピュレーションするのに4分かかりました。ポピュレーションの進捗やステータスは「V$IM」で始まるディクショナリ・ビューから参照できます。
|
|
ポピュレーションが完了したので、早速Oracle Database In-Memoryの性能を測ってみます。最初に実行するのは、6億行あるLINEORDER表への全件検索です。今回は以下のパターンで結果を取得し、比較していきます。
まずは従来のOracle Databaseで全件検索を実行します。今回は索引を作成しておらず、かつデータが6億行と膨大なため、ディスクにアクセスした場合は4分49秒、バッファ・キャッシュの場合は54秒かかりました。
|
|
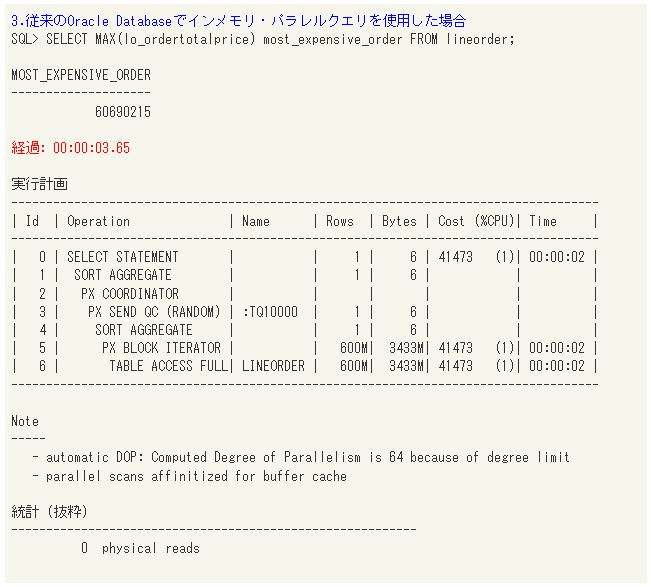
続いて、Enterprise Editionの機能であるインメモリ・パラレルクエリを使用して同様のSQLを実行します。今回は64並列で処理を行うことにより、3.6秒まで処理時間を短縮できました。
|
|
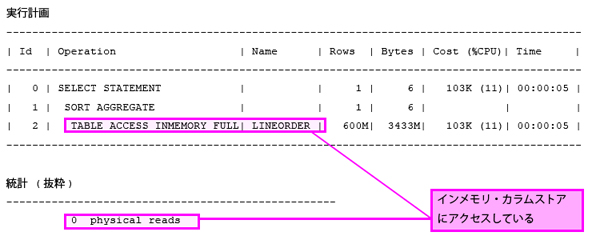
最後に、Oracle Database In-Memoryで全件検索を実行します。
|
|
なんと、0.1秒で検索結果が返ってきました!!
今回実行したSQLはlo_ordertotalprice列だけを対象としているため、カラム型の効果が出やすいのですが、これまでの結果と比べて桁違いのスピードです。実行計画を見ると、これまでとは異なり「TABLE ACCESS INMEMORY FULL」と表示されています。統計のphysical readsが0になっており、一切ディスクにアクセスせずメモリ上で処理できていることが分かります(実は更に高速化の秘密があるのですが、それは後述します)。
|
|
全4パターンの結果をまとめると、改めてOracle Database In-Memoryの速さが分かります。ディスクにアクセスした場合と比べて数千倍、バッファ・キャッシュと比べても数十倍高速化できており、分析系の性能に課題を持つシステムには非常に効果のある新機能と言えます。
|
表2:全件検索の検証結果 |
Oracle Database In-Memoryの特徴のひとつに、「索引を削除することで更新性能が上がる」というものがあります。インメモリ+カラム型によって検索処理が高速になるため、索引が不要になるという意味なのですが、チューニングの要とも言える索引を削除して本当に大丈夫なのかが気になります。
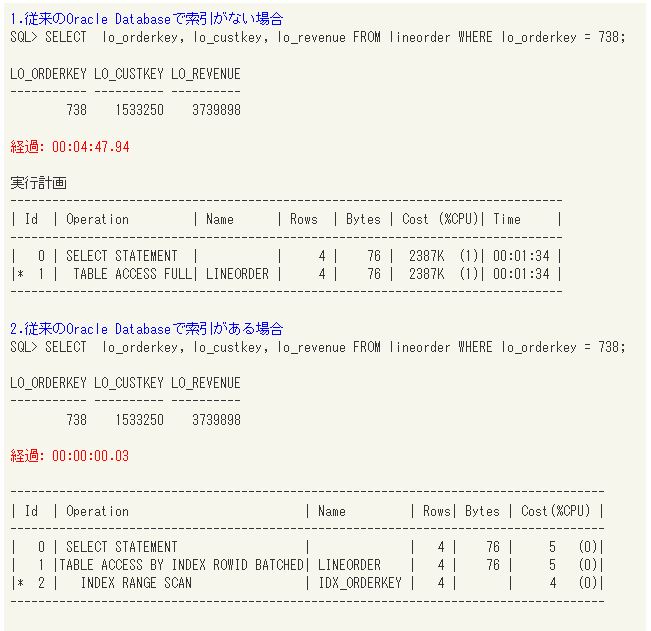
そこで、索引が得意とする一意検索の性能を測ってみます。6億行あるLINEORDER表から1件のデータを取り出すのにどのくらいかかるのか、以下のパターンと比較していきます。
まずは従来のOracle Databaseで性能を測ります。該当列に索引がない場合は当然ながら全件検索になるため、4分47秒と時間がかかりますが、索引がある場合は0.03秒にまで短縮されます。
|
|
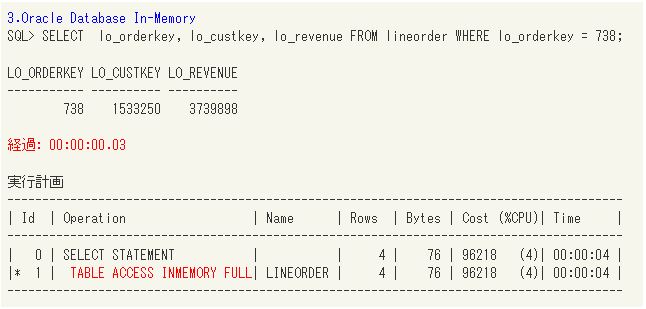
次にOracle Database In-Memoryで同じSQLを実行します。
|
|
結果は索引がある場合と同じ0.03秒でした。この性能であれば、更新速度を上げるために索引を削除するということも十分視野に入れることができます。しかし、実行計画を見るとTABLE ACCESS INMEMORY FULLになっており、1件のデータを検索するのに6億行すべてにアクセスするのは効率が悪いのでは?と思ってしまいます。
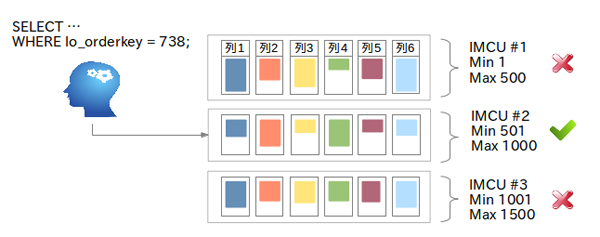
実は、インメモリ・カラムストア内のデータは「IMCU(In-Memory Compression Unit)」という単位で区切られており、さらにすべての列の最大値と最小値を記録する「ストレージ索引」が存在しています。以下のようにWHERE句の条件と最大値、最小値を照合することで、アクセスするIMCUを絞り込むことができるため、従来の索引がなくても高速に処理が行えます。最初に実施したMAX関数を使用した全件検索が高速だったのも、ストレージ索引のおかげです。
|
図3:IMCUとストレージ索引 |
ただし、ストレージ索引があるからといってすべての索引が不要になるわけではありません。今回試したようなOLTPでよく使われるシンプルな一意検索では、あえてOracle Database In-Memoryを使わずとも従来の索引だけで十分な性能が出ます。実行計画をよく見るとOracle Database In-Memoryの方がコスト的には高くなっているので、この場合は索引アクセスのほうが適切と言えます。
実行計画を決めるのはあくまでオプティマイザであるため、Oracle Database In-Memoryを使用した場合でも、従来の索引アクセスが選択される場合があります。索引の削除を検討するにあたっては、インメモリ化することによって必要以上にコストが高くなりすぎないか、十分に確認することが重要です。
次回は結合を含む検索処理について、Oracle Database In-Memoryの性能を検証します。
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.1
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.3
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.4
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.5
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.6
|
|
関 俊洋
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

