















- Oracle Cloud
- Oracle Database
気になるテーマから学べる!無料オンデマンド動画「OCI入門者向けウェビナー」のご紹介
OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。
![]()






|
|
企業の情報システムで利用されているRDBMSでは、近年は商用データベースだけでなくオープンソース・データベースを併用するケースも増えており、選択肢は多様化しています。ご存じの通り、SQLはRDBMS共通の言語ですが、実際は細かな記述の違いやRDBMS独自の機能が多数存在します。そのため、例えば商用データベースからオープンソース・データベースに移行したり併用したりすると、アプリケーションの改修コストや、意図した通りに動作しないといった問題が発生する場合があります。本記事では、SQLの視点からRDBMSの主な差異を紹介し、異なるRDBMSに移行する際の注意点やRDBMS選定のポイントに迫ります。
本記事では、以下のRDBMSについて解説していきます。
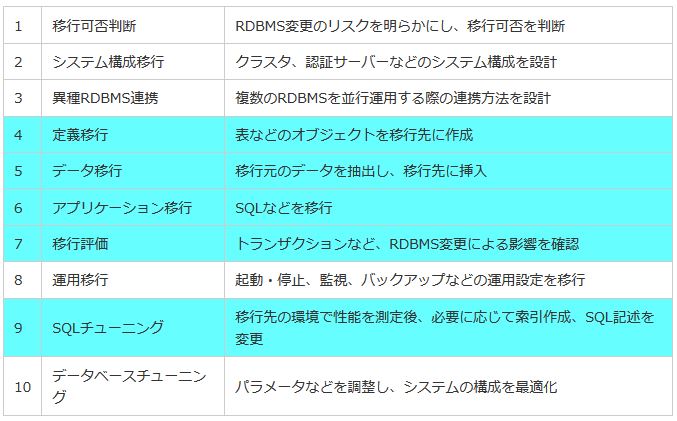
本記事では、RDBMS間での移行を題材にして解説していきます。移行は一般的に主に以下のようなフローで行われます。その中でもSQLが直接関係するステップ4、5、6、7、9(網掛けのステップ)について解説しています。
|
表1:異なるRDBMS間での移行ステップ |
RDBMSを移行する際は、まず移行先のデータベースに表などのオブジェクトを定義する必要があります。この時、作成コマンドの指定項目が異なっていたり、オブジェクトの存在有無などの違いがあるため、必要に応じて代替機能を用いるなどで対応します。
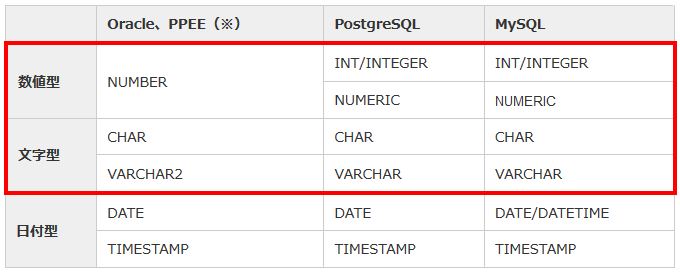
RDBMS間で同じデータ型もあれば、名称や内部的なデータの取り扱いが異なるデータ型もあります。そのため、異なるRDBMSに移行する際は、対応する同等のデータ型に修正して表を作成します。
|
表2:主なデータ型の比較 |
特に数値型、文字型で差異があるため、互換性の高いデータ型を調査・設定する必要があります。
表名・列名の命名規則について、RDBMSごとに違いがあります。
|
表3:表名・列名の命名規則の比較 |
先頭文字に半角数字を指定した場合、OracleとPostgreSQLではエラーが発生します。
表作成時は、必要に応じて特定列に制約を定義します。この時、MySQLではチェック制約(列に任意のルールを定義できる制約)が存在しないため、代替機能も含め対応を検討します。
|
表4:チェック制約の有無 |
実は、MySQLではチェック制約が存在しないにも関わらず、OracleやPostgreSQLと同じチェック制約の構文を実行してもエラーは発生しません。ただ、実際にはチェック制約は定義されていません。
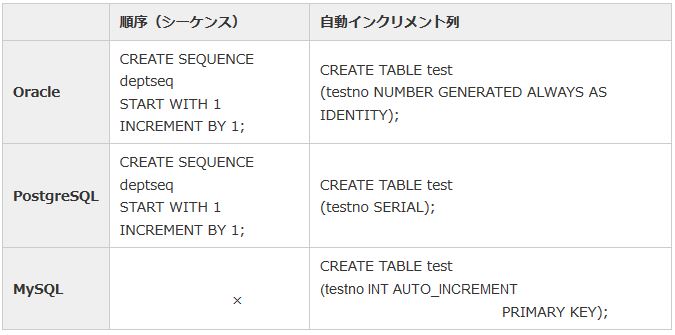
連続値を生成する主な機能として、順序(シーケンス)と自動インクリメント列があります。これらの機能は、RDBMSによっては利用できないものがあります。
|
表5:連続値の生成機能の比較 |
・順序(シーケンス)
連続値を生成するオブジェクトで、関数で呼び出すごとに値が生成されます。
・自動インクリメント列
列の属性として定義し、行が挿入されるごとに連続値が生成されます。
MySQLでは、列名とデータ型の指定に続き、AUTO_INCREMENT句を指定します。また、主キー制約、一意キー制約、索引のいずれかの設定も必要です。また、データ型にSERIAL型を指定した場合、自動インクリメント列が暗黙的に定義されます(「BIGINT UNSIGNED NOT NULL AUTO_INCREMENT UNIQUE」として定義されます)。
PostgreSQLでは、データ型にSERIAL型を指定すると暗黙的に順序が作成され、その順序を使用するように設定されます。
シノニムとは、オブジェクトに対する別名のことです。シノニムを利用することで、所有者名の修飾を不要としたり、SQLを変更せずにアクセスするオブジェクトを切り替えたりといった、オブジェクトの実体の隠蔽が可能になります。
Oracleには2種類のシノニムがありますが、PostgreSQL、MySQLにはシノニムが存在しません。
|
表6:シノニムの有無 |
PostgreSQL、MySQLではシノニムが存在しないため、移行の際は注意が必要です。ちなみに、表に対する別名定義であれば、以下のようにビューで代替できます。
1. CREATE VIEW emp_pub AS SELECT * FROM emp;
対象表を全件検索するSQLに対してビュー名emp_pubを定義
2. GRANT SELECT ON emp_pub TO ユーザー名;
ビューemp_pubに対するSELECT権限をユーザーに付与
<補足:スキーマの概念>
Oracleでは、ユーザーとスキーマは同義です。それに対し、PostgreSQLでは、ユーザーとスキーマは分離しています。Oracleと同様にスキーマ・オブジェクトを管理したい場合は、明示的にスキーマを作成する必要があります。MySQLではスキーマはデータベースと同義であり、また、他のRDBMSのような所有者の概念がありません。このように、各RDBMSでスキーマの概念が異なるため、注意が必要です。
移行先のデータベースにオブジェクトを作成した後は、データを移行します。この時、RDBMSによってデータの扱いが異なる点に注意します。
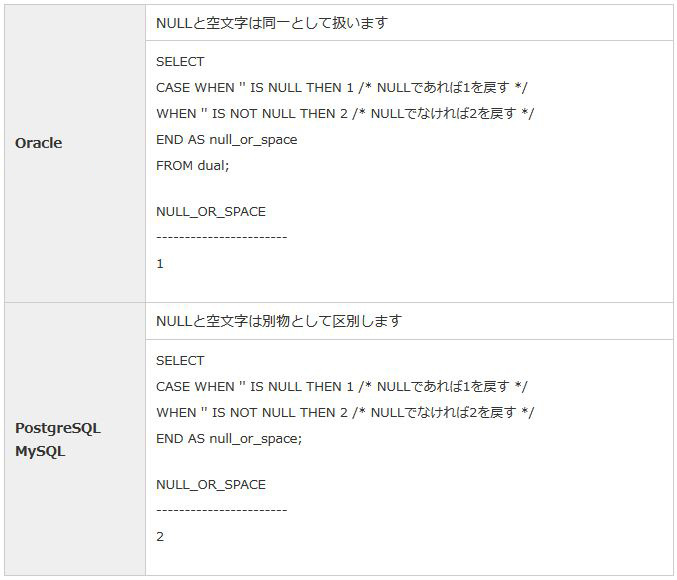
OracleとPostgreSQL・MySQLでは、NULLと空文字の扱いが異なります。そのため、移行時はその特性を踏まえてアプリケーションを改修したり、表からNULL自体を排除する対応(NULLをダミーデータに置き換えるなど)が必要です。
|
表7:NULLと空文字の扱いの比較 |
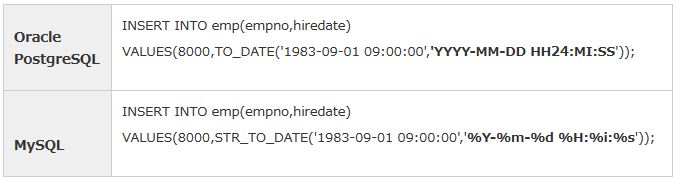
OracleとPostgreSQLは日付書式の共通性が高く、日付書式を修正せずに移行できるケースがあります。対して、MySQLは共通性が低いため、MySQLが関わる移行では注意が必要です。
|
表8:日付書式の比較 |
アプリケーションの移行では、RDBMS特有の機能や記述方法に注意が必要です。RDBMS独自の手法を多用しているとアプリケーションの移植性が低くなるため、普段から可能な限り汎用的な機能・記述の利用を意識することが重要です。
どのRDBMSでもANSI規格のOUTER JOIN構文を使用できます。
また、Oracleのみ結合演算子(+)を使う方法も利用できますが、将来の移植性を鑑み、汎用性の高いOUTER JOINを使用した外部結合をお勧めします。
|
表9:外部結合構文の比較 |
結合演算子(+)は移植性以外にも、結合条件の記述に制限があったり、完全外部結合(FULL OUTER JOIN)でコードが長くなるなどの注意事項があります。
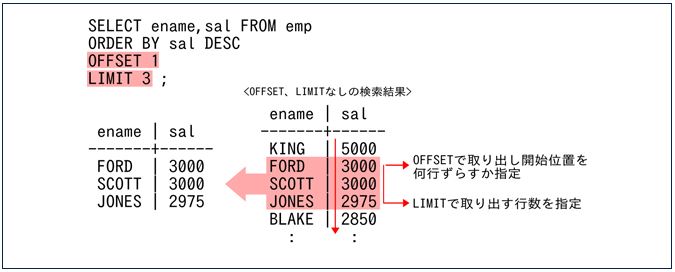
PostgreSQLとMySQLでは、OFFSET句とLIMIT句を使用すると、以下のように検索結果の特定行の抽出が容易に行えます。Oracleは12cから同等の機能が提供されています。
|
図1:OFFSET句とLIMIT句の役割 |
|
表10:検索結果の特定範囲の行の抽出方法 |
Oracle 11gまでは、OFFSET句とLIMIT句に相当する機能はありません。しかし、インラインビュー・集計関数・ROWNUM擬似列などを併用すれば同じ結果を表示できます(ただしSQLは複雑になります)。
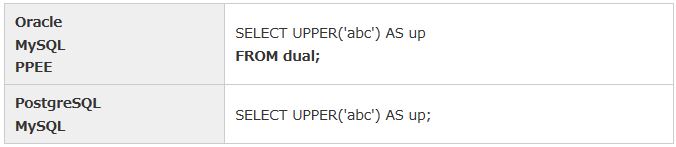
日付や演算結果の表示といった、値の表示で表を参照する必要が無い場合、OracleではDUAL表を指定します。PostgreSQLはDUAL表の指定は不要です(DUAL表が存在しません)。MySQLはDUAL表を指定しても指定しなくてもどちらでも実行できます。
そのため、OracleとPostgreSQL間での移行では注意が必要です。
|
表11:DUAL表の有無 |
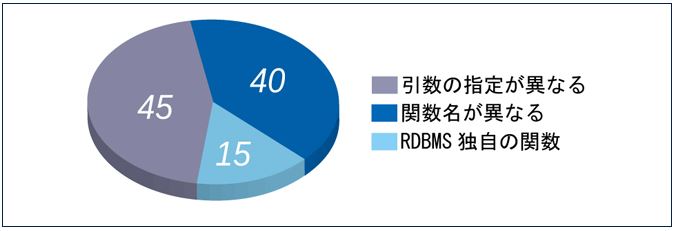
主要な組み込み関数を比較したところ、RDBMS間の共通性はそれほど高くないことがわかりました。まずは以下の比較結果を見てください。
・Oracle、PostgreSQL、MySQLで関数名と指定方法が全く同一の関数は30%程度
・残りの70%の関数は以下3つの違いに分類
|
図2:関数の差異の内訳 |
では、この3つの違いの具体例を出していきます。
1. 引数の指定が異なる
<数値を文字に変換する>
|
表12:引数の指定が異なる関数の比較 |
2. 関数名が異なる
<接続中のセッションIDを表示する>
|
表13:関数名が異なる関数の比較 |
3. RDBMS独自の関数が存在する
Oracleの場合、独自関数としてDECODE、TO_MULTI_BYTE、TO_SINGLE_BYTE、SUBSTRB、INSTRBなどが存在します。
移植性を重視する場合、このような独自関数は可能な限り使用しないことをお勧めします。
※PPEEはOracle独自関数を数多くサポートしているため、Oracle→PostgreSQLの移行コストを低く抑えることができます。
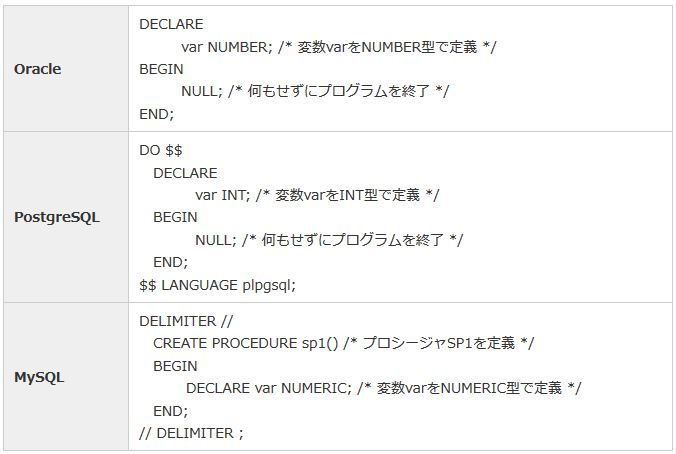
SQLから話が外れますが、基本的にどのRDBMSでもOracleのPL/SQLのような手続き型言語(プロシージャやファンクション)が提供されています。
条件分岐やループ、カーソル処理などの基本機能はRDBMS間で共通して提供されていますが、以下の例のように基本構文自体が異なります。そのため、異なるRDBMSに移行する際は、手続き型言語で作成したアプリケーションの改修コストが高くなることに注意してください。
|
表14:プロシージャの基本構文の比較 |
RDBMSによってトランザクションのデフォルト設定やエラー時の動作が異なります。そのため、トランザクションが意図した動作になっているか、入念に評価する必要があります。
RDBMSによって任意の単位でトランザクションを確定するか、SQL1文単位で自動的に確定(自動コミット)されるかが異なります。
|
表15:デフォルトのトランザクション動作の比較 |
このような特徴により、OracleとPostgreSQL・MySQL間の移行では特に注意が必要です。
また、PostgreSQL独自の特徴としてDDLによる暗黙コミットは行われないため、任意の単位でトランザクションを実行している場合はロールバックが可能です。
PostgreSQLのみ動作が異なるため、例外処理において注意が必要です。
|
表16:トランザクション中のエラーにおける動作・対処の比較 |
|
図3:PostgreSQLにおけるトランザクション中のエラー対処 |
このような特徴から、PostgreSQLに移行する際は例外処理を特に入念に設計・評価する必要があります。ちなみに、セーブポイントを設定していれば、そのセーブポイントまでのロールバックで済みます。
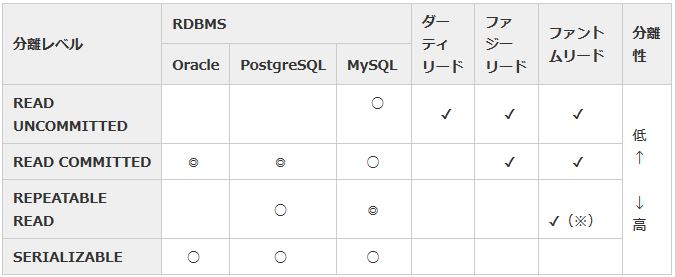
ANSI規格では4つのトランザクション分離レベルが定義されていますが、RDBMSによって全てサポートしているものもあれば一部のみサポートしているものもあります。
|
表17:サポートしているトランザクション分離レベル |
上記4規格とは別に、OracleとMySQL(5.6.5以降)では読み取り専用モードの設定が可能です。この設定をしたトランザクションでは、トランザクション開始時のCOMMIT済みデータを一貫して読み取るようになります(読み取りのみで変更操作はできません)。
移行の最終フェーズでは、パフォーマンス測定によって移行前と同等の速度が得られているかを確認します。その結果に応じてSQLチューニングやデータベースチューニングを実施します。
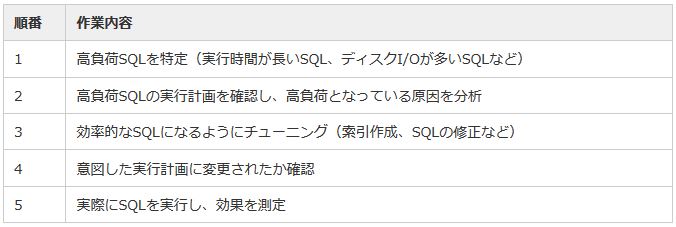
中でもチューニングの効果が大きいSQLチューニングでは、チューニングのアプローチや効率的なSQL記述のパターンを中心に、RDBMS共通であるものが数多く存在します。
作業ステップ自体はRDBMSで共通です。しかし、各ステップにおける作業方法(使用するユーティリティやコマンドなど)に共通性はなく、RDBMSごとに異なります。
|
表18:SQLチューニングの作業ステップ |
例えば、索引が使用されない記述など、パフォーマンスに影響を及ぼすSQLの記述パターンは基本的にRDBMS共通です(ただし、細かなルールレベルでの違いは幾つかあります)。
そのため、正しく効率的なSQL記述のパターンを理解しておけば、将来異なるRDBMSを利用することになっても、そのスキルを継続して活かすことができるでしょう。
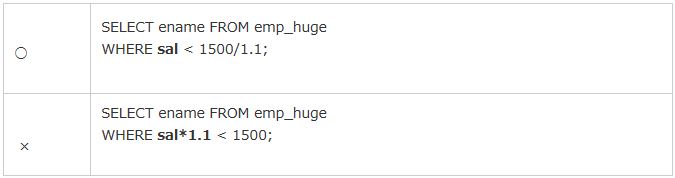
<パターン例1:索引列を変更してしまうと索引が使用されない(SAL列に索引が定義)>
|
表19:索引が使用されないSQLの記述パターン |
<パターン例2:索引からソート済みデータを読み取り、ソート処理をスキップする(EMPNO列も索引が定義)>
|
表20:索引を使用してソート処理をスキップできる記述パターン |
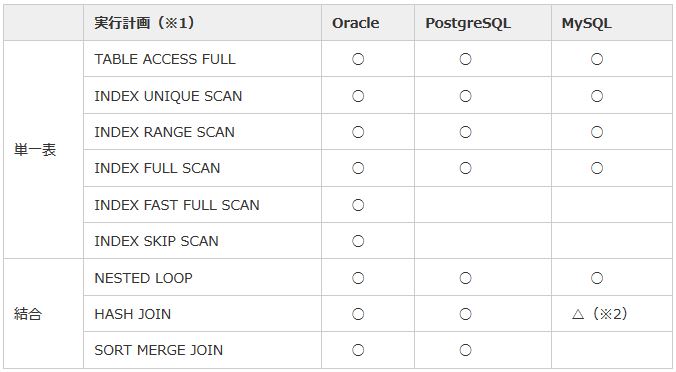
Oracleでは非常に多くの実行計画がサポートされており、SQLの記述やデータ量などに応じて最適な実行計画を選択できます。以下の表にはOracleの主な実行計画をまとめていますが、それと比べると、PostgreSQLとMySQLの実行計画はそれほど多くないことがわかります。
PostgreSQLは単一表、結合の実行計画ともに必要最低限のものはサポートしています。 それに対してMySQLの結合方式はNESTED LOOP(少量行の結合に向く方式)のみのため、大量行を結合して集計・分析を行うようなシステムでは注意が必要です。
|
表21:サポートされている実行計画の比較 |
任意の実行計画を強制するヒントは、RDBMSによってそれ自体の有無、種類数、指定方法などが異なります。
|
表22:ヒントの有無の比較 |
ちなみに、PostgreSQLではヒントはありませんが、各実行計画の使用可能・不可をパラメータで制御できます。そのため、これらを調整して任意の実行計画に誘導することは可能です。
いかがでしたでしょうか。主なものだけの紹介でしたが、RDBMS共通と言われているSQLでもRDBMSによってある程度違いがあることがお分かりいただけたと思います。このような違いを踏まえると、将来のデータベース移行も想定して、以下の点に注意する必要があると言えます。
・可能な限り汎用的な方法でSQLを記述する(ANSI規格のSQLを利用する)
・互換性の高いRDBMSを採用する(例えばOracle→PostgreSQLの場合はPPEEを採用)
将来の自由なRDBMSの選定を妨げないよう、普段から汎用的なSQL記述を意識することが重要です。また、異なるRDBMSに移行する際、機能の有無が問題になったり、移行工数を削減したいようなケースでは、PPEEやMariaDBのような互換性の高いRDBMSを検討することも1つの手でしょう。
なお、本記事に掲載している各トピックは、書籍「SQL逆引き大全363の極意」から抜粋し、加筆・修正したものです。興味のある方は是非ご覧になってください。
|
|
|
|
小笠原 宏幸
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

