



- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
Oracle Database In-Memoryがリリースされてから約5ヵ月が経ち、導入に向けた製品評価を行っている、あるいは行う予定があるという声を多く耳にするようになりました。4回目となる今回は、実際に検証しなければ分からないOracle Database In-Memoryの真実に迫ります。
アシストでは、10月から11月にかけて、東京、大阪、名古屋でOracle Database In-Memoryの検証結果を発表するセミナーを開催(2014/10/29開催 アシストテクニカルフォーラム特別講演 開催報告
)しました。延べ700名以上のお申し込みをいただき盛況のうちに終えることができましたが、印象的だったのは性能だけでなく注意事項や課題などに着目されている方が多かったということです。
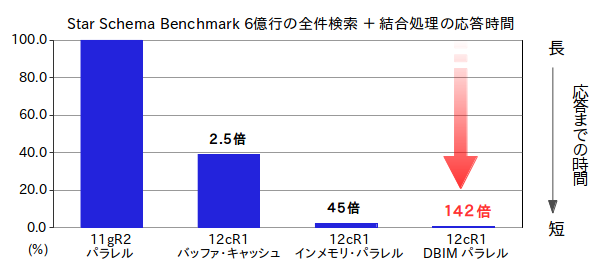
これまでの記事でご紹介したように、Oracle Database In-Memoryの特徴はその圧倒的な速さと、SQLの変更が不要というシンプルさにあります。Star Schema Benchmarkを用いた検証では、ディスク・アクセスに比べて数百倍、バッファ・キャッシュに比べて数十倍の速度向上が確認できています。
|
Oracle Database In-Memoryの性能検証結果 |
しかし、表をインメモリにするという簡単な操作でこれだけの結果を得られてしまうため、「本当にそれだけで大丈夫なのか?」「他に気を付けることはないか?」と疑問を抱く方が多いように思います。そこで今回は、Oracle Database In-Memoryを実際に検証して分かった注意事項や、マニュアルに書かれていない特殊なケースでの動作などをご紹介します。
Oracle Database In-Memoryでは、非圧縮を含む6つの圧縮タイプをサポートしています。デフォルトではFOR QUERY LOWというクエリの性能を重視した圧縮タイプが使われるようになっており、その他にも圧縮率を重視したFOR CAPACITY HIGHなどがあります。
圧縮タイプは自由に選択できるため、メモリのサイズが有限であることを考えると、高い圧縮率のものが魅力的に映ります。ただし、どれを選択するかによって圧縮率だけでなくクエリの性能も変わってくることを考慮しなければいけません。
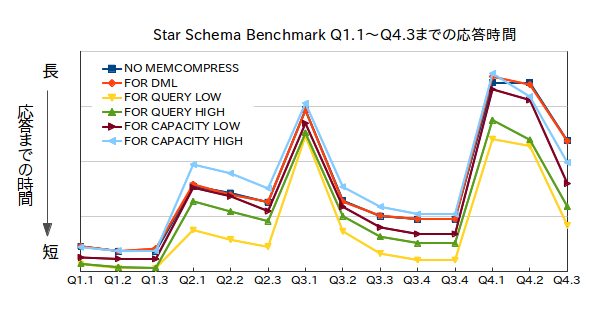
以下のグラフは、圧縮タイプごとにクエリの応答性能がどの程度違うのかを並べて比較したものです。全部で14あるStar Schema Benchmarkのクエリのほぼすべてにおいて、圧縮タイプごとの性能差が確認できています。クエリによっては3倍近くの性能差が出ることもあります。
|
圧縮タイプごとの性能差 |
性能差が出る理由はAWR(自動ワークロード・リポジトリ)やシステム・リソースの使用状況を見ればすぐに分かります。FOR QUERYではデータを圧縮した状態でそのまま参照できますが、FOR CAPACITYの場合は解凍が必要になります。CPUが使われた時間を比べてみると、以下のように何倍もの差が出ています。
|
解凍が必要な圧縮タイプとその影響 |
こうした動作の違いがあるため、性能重視の場合はデフォルトであるFOR QUERY LOWが推奨されます。FOR CAPACITYが非推奨というわけではなく、クエリの応答時間が性能要件を上回るのであれば、圧縮率を高めるための選択肢としては有効です。こうした違いを把握した上で、どの圧縮タイプを選択するかを決めましょう。
Oracle Database In-Memoryでは、ポピュレーションと呼ばれる動作によってディスク上のデータをメモリ上に読み込みます。このとき、行フォーマットから列フォーマットにデータが変換され、さらに圧縮が行われるため、どの圧縮タイプを選択するかによってポピュレーションの速度は大きく変わってきます。
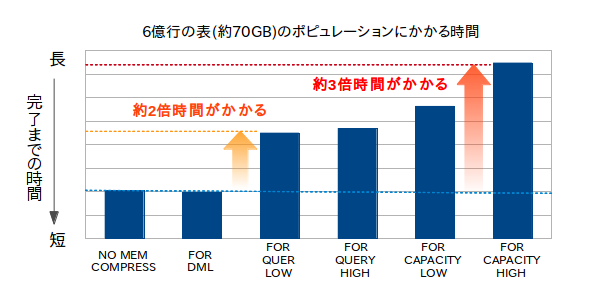
以下のグラフは、同じデータを使って圧縮タイプ別のポピュレーション時間を測定したものです。圧縮タイプによって2~3倍の差が出ていることが分かります。
|
圧縮タイプによるポピュレーション速度の違い |
ポピュレーションの時間が長くなると、それだけインメモリのクエリを実行できるまでの待ち時間が増えてしまいます。例えば投入したデータをすぐに分析したい場合や、障害が発生してサーバが再起動した場合など、ポピュレーション時間が長すぎることで業務が滞ってしまう可能性もあります。ポピュレーションの時間はCPUの性能やコア数に大きく依存するため、検索性能だけではなくポピュレーションの時間までしっかりと検証した上でどれを選択するか決めましょう。
Oracle Database In-Memoryの製品情報サイトやデータシートには、索引の扱いについて以下のように書かれています。
一見すると、Oracle Database In-Memoryでは索引が不要になるように思えますが、そうではありません。不要になるのは「分析用の」索引だけです。例えば一意検索などのオンライン・トランザクションに関しては、引き続き索引が必要です。
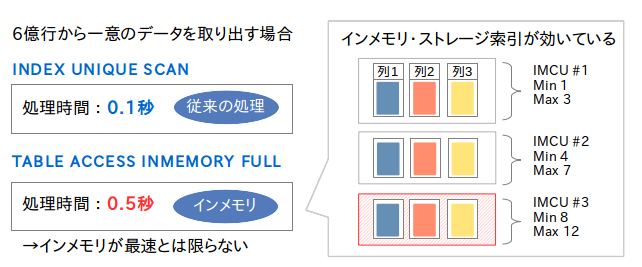
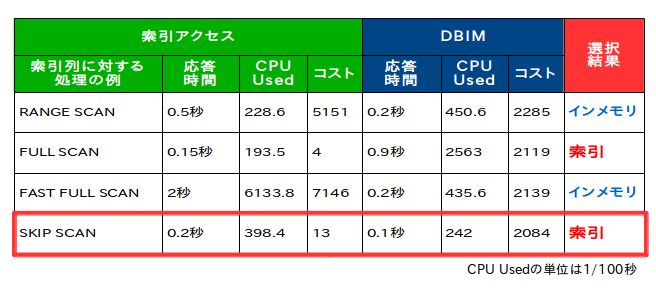
例えば、6億件のデータから1件だけを取り出す場合、索引があればINDEX UNIQUE SCANができるため0.1秒で結果が返ってきます。同じ処理をOracle Database In-Memoryで実行すると0.5秒かかります。Oracle Database In-Memoryにはインメモリ・ストレージ索引などデータを絞り込むための工夫が施されていますが、処理によっては従来の索引アクセスの方が高速な場合もあります。
|
一意検索の応答速度 |
索引作成されており、かつデータがメモリ上にポピュレーションされている場合、どちらを使用するかはオプティマイザが判断します。先ほどご紹介したような処理であれば、オプティマイザはインメモリではなく索引アクセスを選択します。
しかし、現実はこうした分かりやすい処理だけではありません。範囲検索など索引アクセスにも様々なパターンがありますので、インメモリとの使い分けが正確に行われるのかを検証してみました。その結果が以下の表です。
|
様々な索引アクセスにおけるインメモリとの使い分け |
ほとんどの場合、より応答時間の短い方をオプティマイザが選択しています。しかし例外もあり、一番下にあるSKIP SCANの場合はインメモリの方が応答時間は短いにも関らず、索引が選択されています。コストの列を見ると、インメモリの方がコストが高く見積もられていることが分かります。他の場合でもインメモリのコストは2,000前後と似通った値になっています。索引が選択されたとしても0.1秒が0.2秒になるという微々たる差なので、これまでどおりコストベース・オプティマイザの判断に委ねるのが基本ですが、どうしてもインメモリに実行計画を固定したい場合は、ヒント句を入れるなどして対応します。
Oracle Databaseに限らず、どのデータベース・システムにおいてもメモリのサイジングは非常に重要です。メモリとハードディスクのI/O性能はナノ秒とミリ秒で100万倍も違うため、頻繁に参照されるデータはメモリ上から取り出されるのが理想的です。
しかし、サイジング当初の想定よりも運用開始後にデータが増えてしまうということはよくあります。もしOracle Database In-Memoryでデータ量が増えてメモリに収まりきらなくなったらどうなるのでしょうか?
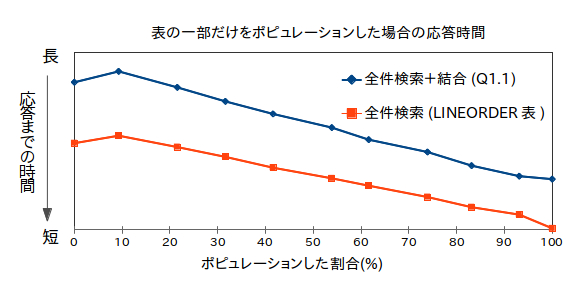
Oracle Database In-Memoryでは、例えば10GBのインメモリ・カラムストアに対して50GBの表をポピュレーションしようとしても、エラーにはなりません。10GBのうち使える領域の分だけポピュレーションが行われます。そのため、表の何%かだけがインメモリになっているということが起こりえます。その状態でクエリを実行した時の性能を検証したのが以下のグラフです。
|
表の一部だけをポピュレーションした場合 |
表の100%がポピュレーションされている場合が当然最速ですが、ポピュレーションした割合に応じてクエリの時間が短くなっていることが分かります。Oracle Database In-Memoryでは、わずかでもメモリ上にデータがあればそれを使ってくれます。足りない分はディスクまたはバッファ・キャッシュへのアクセスになりますが、それでもある程度の性能は確保できます。
ただしこれが望ましい状態とは言えないため、データ量が増えた場合はパーティショニングでインメモリにするデータを絞ったり、圧縮レベルを変更するなどの検討を行いましょう。なお、実行計画には表の一部だけがポピュレーションされている状態でも、「TABLE ACCESS INMEMORY FULL」と表示されます。全データをメモリから取り出しているとは限らないので、physical readsの統計も併せて確認するようにしましょう。
SQL> SELECT MAX(lo_ordertotalprice) most_expensive_order FROM lineorder;
---------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes |
---------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 6 |
| 1 | SORT AGGREGATE | | 1 | 6 |
| 2 | PX COORDINATOR | | | |
| 3 | PX SEND QC (RANDOM) | :TQ10000 | 1 | 6 |
| 4 | SORT AGGREGATE | | 1 | 6 |
| 5 | PX BLOCK ITERATOR | | 600M| 3433M|
| 6 | TABLE ACCESS INMEMORY FULL| LINEORDER | 600M| 3433M|
---------------------------------------------------------------------
統計
----------------------------------------------------------
209 recursive calls
0 db block gets
4054526 consistent gets
4050437 physical reads <----- 物理読込みが発生している
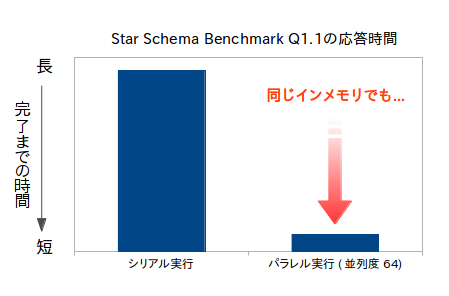
Oracle Database In-Memoryでは、パラレル実行を組み合わせることで、より高速に検索結果を返すことができます。以下のようにパラレル実行の有無によって数十倍の性能差が出ることもあり、利用が必須と言っても過言ではありません。
|
シリアル実行とパラレル実行の性能差 |
パラレル実行には手動設定と自動設定があり、手動設定の場合はALTER文のPARALLEL句で並列度を指定します。このとき、並列度を省略して「ALTER TABLE 表名 PARALLEL;」と指定することもできますが、Oracle Database In-Memoryではあまりお薦めできない設定なので注意してください。
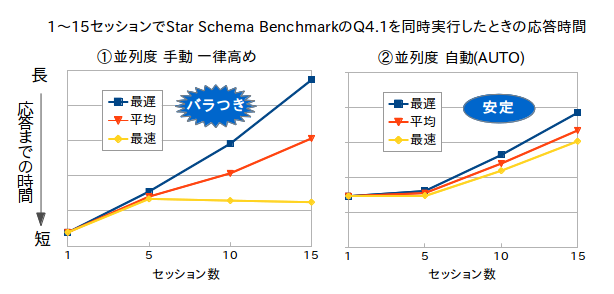
並列度を省略した場合、デフォルト値として初期化パラメータのPARALLEL_THREADS_PER_CPU x CPU_COUNT※の結果が使用されます。例えば、16コア搭載でHyper-ThreadingがONの場合、並列度は「32☓2=64」になります。これは単一セッションだけ考えればベストに近い設定ですが、複数セッションからクエリを実行するような場合には向いていません。値が大きすぎるため、以下のようにセッションごとの応答時間に大きくバラつきが出てしまいます。
※ シングル・インスタンスでの計算式です。RAC環境の場合はさらにノード数に応じて並列度が増加します。
|
並列度の設定による応答時間の違い |
こうした複数セッションでの性能を考慮せず並列度を決めてしまうと、カットオーバー後に多数のユーザが利用し始めた途端に性能が出なくなり、トラブルの原因になります。Oracle Database In-MemoryではI/Oが発生しない分CPUに処理が集中するため、並列度を自動設定にするか、手動設定でも一律で並列度を高めにしすぎないよう、十分な検証を行ってから設定値を決めることをお薦めします。
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.1
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.2
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.3
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.5
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.6
|
|
関 俊洋
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

