


- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
前回に引き続き、実際に検証して分かったOracle Database In-Memoryの真実をご紹介します。後編となる今回は、検索の性能だけでなく更新系の性能や圧縮率なども取り上げます。
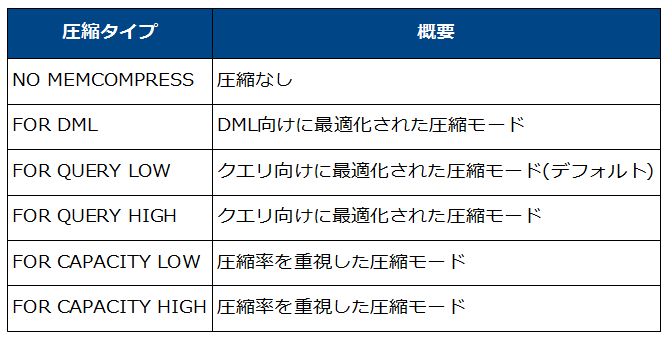
Oracle Database In-Memoryには6種類の圧縮タイプが用意されています。どれを選択するかはユーザが自由に決めることができ、クエリの性能を重視する場合は「FOR QUERY」、圧縮率を重視する場合は「FOR CAPACITY」というように、適切な圧縮タイプは目的によって変わってきます。
|
Oracle Database In-Memoryで選択可能な6つの圧縮タイプ |
圧縮タイプごとの性能差については前回ご紹介しましたので、今回は圧縮率がどの程度異なるのかを比較していきます。使用するデータはこれまでと同じStar Schema Benchmarkのスキーマです。ファクト表には6億行のレコードがあり、列内に同じ値(数字)が多く含まれているのが特徴です。
|
圧縮タイプごとの圧縮率 |
結果を見ると、圧縮タイプによって最大で3倍ほど圧縮率が異なっています。最も圧縮率の高いFOR CAPACITYではデータのサイズが1/4以下になっており、FOR QUERYなど他の圧縮タイプと比べてより多くのデータをメモリ上に格納できます。
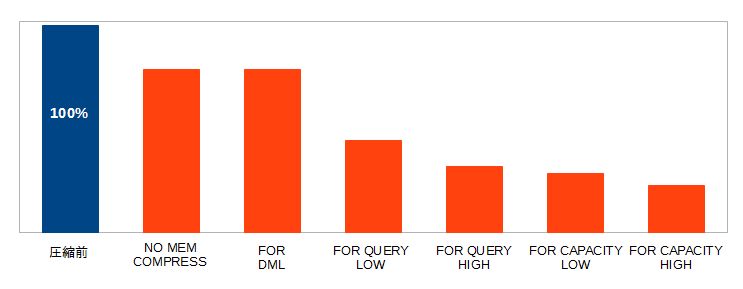
圧縮タイプごとの違いが分かったところで、今度は従来の圧縮やExadataのHybrid Columnar Compression(HCC)と比べてみましょう。その結果が以下のグラフです。
|
従来の圧縮、Exadata HCCとの比較 |
従来の圧縮と比べると、FOR QUERY LOW以降であればOracle Database In-Memoryの方が高い圧縮率になっています。従来の圧縮はデータブロック内にある重複値をシンボル表にコピーするという形で行われていますが、データを行単位で格納しているため、圧縮率はそれほど高くなりません。重複データは同じ行内ではなく列内に存在する可能性が高いので、列指向であるOracle Database In-Memoryのほうが仕組み上有利です。Exadata HCCには及ばないものの、圧縮率としてはかなり優れていることが分かります。
なお、従来の圧縮やExadata HCCで圧縮済みの表でも、ポピュレーションをするとOracle Database In-Memoryの圧縮が適用されます。圧縮されたものをそのままメモリ上に持っていけるわけではないので、メモリのサイジングはOracle Database In-Memoryの圧縮率をもとに行う必要があります。DBMS_COMPRESSIONパッケージやOracle Database In-Memory Advisorを使えば必要な領域を試算できるので、サイジングの際に活用すると良いでしょう。
Oracle Database In-Memoryは分析処理だけに特化した機能であり、更新処理を高速化するような仕組みは持っていません。時折「OLTPの高速化」という表現を見かけますが、それは表をインメモリにして分析用の索引を削除すれば、索引の更新が不要になる分OLTPの高速化に繋がるという意味です。更新は従来どおりバッファ・キャッシュを使って行われるため、索引を削除しない限り非インメモリと同等の性能になるはずです。
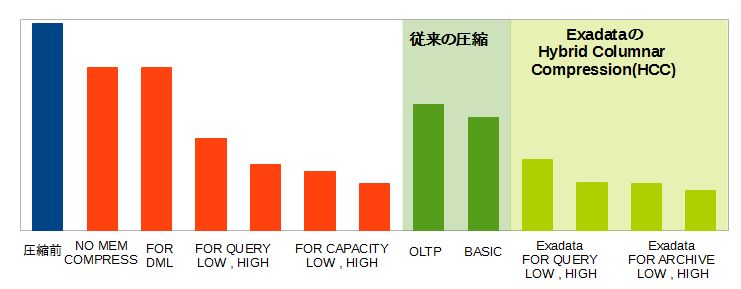
実際にSwingbenchを用いたテストを行ってみたのが以下のグラフです。あらかじめポピュレーションしておいた表に対して、100から500までセッション数を変化させて検証しています。
|
SwingbenchのTPS |
一番左にある非DBIM(Oracle Database In-Memoryを使用しない構成)を基準に比べてみると、100~300セッションの間ではほとんど性能に変化がないことが分かります。500セッションの超高負荷状態になると多少差が見られますが、更新処理向けの圧縮タイプであるFOR DMLを選択しておけばその影響も軽微です。
Oracle Database In-Memoryは、OLTPと分析処理をリアルタイムに融合するというコンセプトを掲げています。非インメモリと同等の更新性能が維持できれば、更新されたデータをその場で分析するというリアルタイムな情報活用が可能になるはずです。
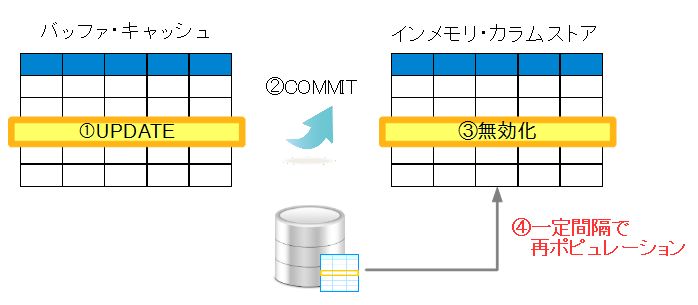
Oracle Database In-MemoryでUPDATE文を発行すると、以下のようにまずバッファ・キャッシュ内で該当のデータが更新され、そのあとインメモリ・カラムストア内にあるデータが無効化されます。
|
更新処理の動作 |
もしこの状態でSELECT文が発行されたとしても、バッファ・キャッシュとインメモリ・カラムストアの内容をマージして結果を返してくれます。インメモリのクエリだけ古い値を返してしまうことはありませんし、SELECT文の書き換えも一切必要ありません。ただ、いつまでも両方のメモリ領域を見に行くのは効率が悪いため、更新されたデータは一定間隔で再ポピュレーションされます。この再ポピュレーションには必ずディスクI/O(direct path read)が伴うため、対象となるデータが多いか少ないかによって、負荷が違ってきます。
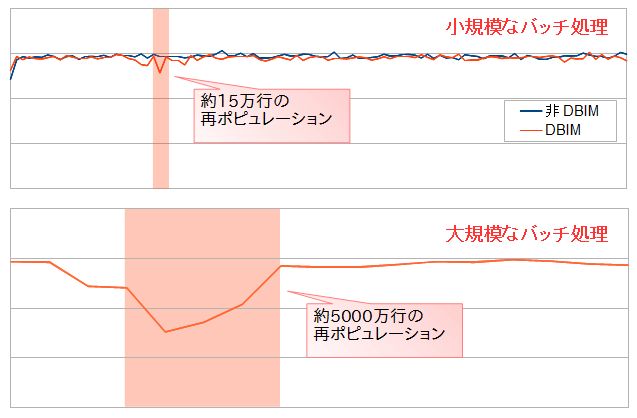
トランザクション中に再ポピュレーションを発生させた時の影響を検証したのが以下のグラフです。Swingbenchを実行している最中に更新系のバッチ処理を行い、TPSがどう変化するかを確認しています。
|
再ポピュレーションの影響度 |
再ポピュレーションの量が少ない小規模なバッチ処理では、裏で動いているトランザクションに全く影響が出ていませんが、大規模なバッチ処理では目に見えてTPSが落ち込んでいます。再ポピュレーションではdirect path readによって大量のI/Oが発生するだけでなく、列フォーマットへの変換や圧縮も同時に行われるためCPUリソースを大量に消費します。
もし大規模なバッチ処理を実行する場合は、できる限り他の処理が動いていない時間帯を選ぶなど運用面での考慮が必要です。
Oracle Database In-Memoryには、ポピュレーションを実行するバックグラウンド・プロセス数を制御するための初期化パラメータ「inmemory_max_populate_servers」が用意されています。この初期化パラメータを調整することでポピュレーションを可能な限り速く終わらせたり、あるいは意図的にプロセス数を減らして負荷を抑えることができます。
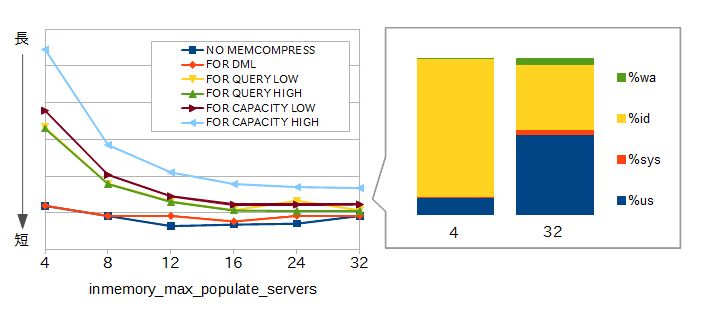
以下のグラフは、inmemory_max_populate_serversの設定によるポピュレーション時間の違いです。4から32まで変化させて検証したところ、プロセス数に応じてポピュレーション時間が短くなっています。
|
プロセス数によるポピュレーション時間の違い |
今回の環境では12あたりでI/O待ちが発生して頭打ちになっていますが、限界点はサーバやストレージの性能に依存します。なお、この初期化パラメータは動的に変更でき、0にするとポピュレーションが停止します。ポピュレーションの時間は圧縮タイプによっても大きく違ってくるため、検証フェーズにおいて実際のデータをもとにポピュレーション時間を試算してみることをお薦めします。
これまでデータベースのボトルネックと言えばディスクI/Oというのが定番でしたが、インメモリの表に対するクエリではその心配がありません。むしろ心配すべきなのはCPUへの負荷です。パラレル処理やポピュレーション時の圧縮など、Oracle Database In-MemoryではCPUの性能が処理速度を大きく左右します。
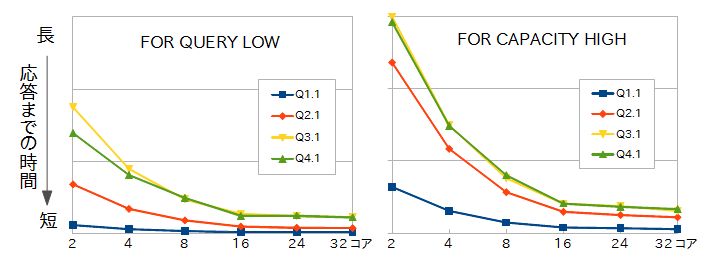
CPUのコア数によって、クエリの性能がどの程度違うのか見てみましょう。以下のグラフはStar Schema Benchmarkのクエリを2~32までコア数を変えながらパラレル処理で実行した結果です。コア数によって性能が大きく異なっていることが分かります。
|
コア数の違いによるクエリの性能差 |
前回の記事でご紹介したように、圧縮タイプにFOR CAPACITYを選択するとクエリ実行時に解凍処理が必要になります。FOR QUERYと比べてより多くのCPUを消費してしまうため、コア数が少ない環境で使用するのは避けたほうが良いでしょう。もちろん、非インメモリの場合と比べればFOR CAPACITY HIGHであっても性能向上が期待できますので、あくまでCPUコア数が少ない環境では選択しにくいというだけです。
CPUのサイジングを行う際には、性能目標がどこにあるのかが非常に重要です。確かにCPUを増やせばそれだけ性能は上がりますが、例えば0.1秒の処理が0.05秒に短縮できてもビジネス的なメリットがなければ意味がありません。過剰投資にならないためにも、できるだけPoCを実施して適切なCPUのサイジングを行うことをお薦めします。
また、ユーザ数やデータ量が増加した場合に備えて、CPUの拡張ができる設計にしておくことも重要です。もちろん物理的にCPUを追加しても良いのですが、Oracle Database In-MemoryはRACにも対応しているので、スケールアウトの構成をとることもできます。
さらに最近では、Oracle Database ApplianceがCapacity-On-Demand(システム規模に応じた支払い)に対応しています。少ないコアを課金対象としてスモールスタートし、必要に応じて残りの搭載コアを有効にしていくことができるため、運用開始後のリソース不足にも柔軟に対応できます。それ以外にもOracle Database In-Memoryの可用性を高める機能が提供されているので、次回はOracleのアプライアンスにスポットをあてて解説していきます。
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.1
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.2
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.3
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.4
・既存の概念を覆す!Oracle Database In-Memoryのテクノロジー Vol.6
|
|
関 俊洋
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

