


- アシストの視点
アシスト取扱製品ヒストリー:Glean編
アシストが設立以来培ってきた「ソフトウェアの目利き力」とは?商材発掘・調査の専門チーム「Bダッシュ委員会」が、生成AIの活用に挑戦するお客様向けに、エンタープライズサーチ「Glean」をどのように選定したのか、その経緯をご紹介します。
![]()





|
|
商用RDBMSのデファクト・スタンダードである「Oracle Database」、オープンソースRDBMSの両雄である「PostgreSQL」、「MySQL」には、それぞれのRDBMSの個性を活かせる適用領域があります。本稿では、RDBMSの「性能要件」に深く関係する「アクセス・パス」を題材に、「Oracle Database」、「PostgreSQL」、「MySQL」の特長を整理し、適材適所で活用するヒントを探ります。
アシストでは1987年に取り扱いを開始した「Oracle Database」に加え、2009年10月より「PostgreSQL(ポストグレスキューエル)」、2011年10月にはPostgreSQLをベースとしOracle Databaseとの互換性機能を有する「Postgres Plus(ポストグレスプラス)」、Webサービスのシステムにて採用されているRDBMSとしてはデファクト・スタンダードになりつつあるコミュニティ版の「MySQL(マイエスキューエル)」と、そのブランチである「MariaDB(マリアディービー)」のサポートを同年12月から開始しています。また、DWH専用に設計されたDBMSソフトウェアとして、2012年3月よりCalpont社の「InfiniDB(インフィニディービー)」の取り扱いを開始しました。
RDBMS領域で、商用RDBMSのデファクト・スタンダードである「Oracle Database」、オープンソースRDBMSの両雄である「PostgreSQL」、「MySQL」のサポート・サービスを開始したことで、それぞれの適用領域に関するご相談をいただくようになりました。RDBMSを採用する要因は、機能要件、非機能要件以外に、開発要員や運用人員のスキルの有無、移行コスト、開発コスト、同じ業界やシステムでの採用事例の有無、社内標準RDBMSであるかどうかなど、多種多様な選定ポイントがあります。
本稿では、「性能要件」に深く関係する「アクセス・パス」の観点から、「Oracle Database」、「PostgreSQL」、「MySQL」の特長を整理します。
「アクセス・パス」とはデータベースからデータを取り出す「経路」のことです。RDBMSでは、アプリケーションから発行されたSQLを「解析」して「実行」しており、「解析」では、SQLの構文チェック、参照されているオブジェクトの存在チェックが行われた後、データにアクセスするための経路であるアクセス・パスが決定されます。例えば、友人との待ち合わせ場所まで、どの経路を使って、どんな交通手段で移動するのが一番効率的かを考えるのと似ています。
代表的なアクセス・パスには、表の行データを1行、1行読み取って、条件に合うデータを取り出す「全表スキャン」と、本の巻末の索引と同じく、表の各列のデータとそのデータの格納位置を示すアドレス情報を持つ「索引」を利用した「索引スキャン」があります。このアクセス・パスは各RDBMSで実装されている種類ごとに異なり、また、各RDBMSのデータを保持する物理構造の違いと相まって、適用領域を考える際のポイントとなります。
「全表スキャン」は表のすべての行が順に読み取られ、選択基準を満たす行が取り出される表データのスキャンです。シンプルな処理であるため、表データを格納する物理構造により特長が生まれます。
|
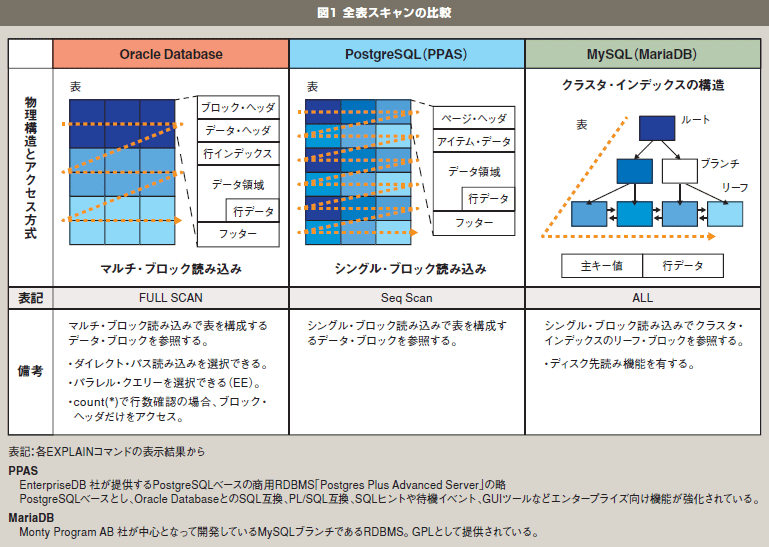
図1 全表スキャンの比較 |
図1のように、Oracle Databaseと、PostgreSQLは、データ格納の最小単位であるデータ・ブロック(ページ)の構造、およびデータ・ブロックの連続した塊で表データが構成される構造が類似していますが、ブロックを読み取る方式が異なります。PostgreSQLはシングル・ブロック読み込みのため1回の読み込み命令で1つのデータ・ブロックにアクセスしますが、OracleDatabaseではマルチ・ブロック読み込みと呼ばれる、複数のデータ・ブロックを一回の読み込みで処理することで、全表スキャンでの読み込み回数を軽減する機能が実装されています。一方、MySQLのデフォルト・ストレージエンジンである「Innodb」では、表データはクラスタ・インデックス構造として格納されています。図1のようにクラスタ・インデックス構造では、表の主キー(主キーが存在しなければ、行を一意に識別する内部行ID)によって、いわゆるB-Tree構造のリーフ・ブロックに相当するデータ・ブロックに、主キーと行データが格納されています。全表スキャンでは、B-Tree構造のルート・ブロック、ブランチ・ブロックからリーフ・ブロックに存在する行データを読み込む方式となります。
このように、どのRDBMSでもアクセス・パスとして全表スキャンは実装されていますが、物理構造とデータ・ブロックの読み取り方式に違いがあるため、特に大規模な表を全表スキャンする場合、Oracle Databaseに優位性があると考えられます。
索引には主キーや一意キーに作成される列値の一意性を保証する一意索引と、一意性を保証しない非一意索引があります。
|
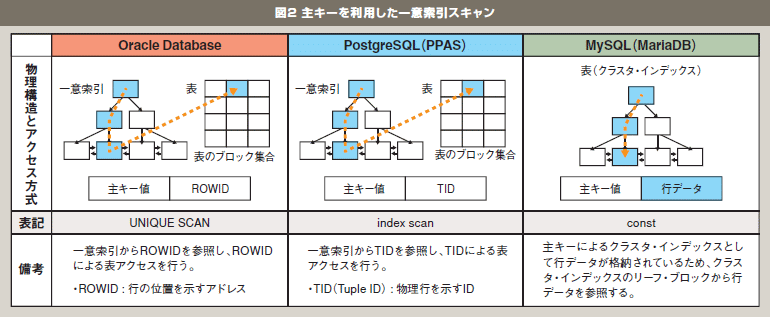
図2 主キーを利用した一意索引スキャン |
Oracle DatabaseとPostgreSQLの場合、いずれの索引も表とは異なるオブジェクトとして作成されます。図2のように、主キーを利用した一意索引スキャンの場合、一意索引のリーフ・ブロックから物理的な行の格納位置を示すアドレス情報を参照し、表を構成するデータ・ブロックにアクセスします。一方、MySQLの場合、行データは主キーによるクラスタ・インデックスのリーフ・ブロックに格納されているため、主キーを利用した一意索引スキャンでは、クラスタ・インデックスから行データを直接参照することができます。つまり、Oracle Databaseと、PostgreSQLでは一意索引のルート、ブランチ、リーフの各ブロックと表のデータ・ブロックの合計4ブロックへのアクセスが必要であるのに対し、MySQLではクラスタ・インデックスのルート、ブランチ、リーフの3ブロックで行データにアクセスできるため、主キーを利用した一意索引スキャンではMySQLに優位性があると考えられます。
|
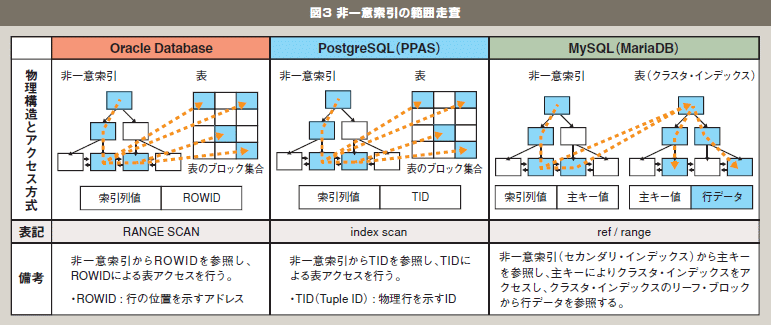
図3 非一意索引の範囲走査 |
非一意索引スキャンの場合も、図3のようにOracle Databaseと PostgreSQLの動作は一意索引スキャンと同様です。MySQLの場合、非一意索引のリーフ・ブロックには、索引を作成した列の値と、主キー値が格納されています。非一意索引スキャンでは、非一意索引のリーフ・ブロックから該当する主キー値が参照され、クラスタ・インデックス構造である表データに主キーでアクセスされます。つまり、Oracle Database、PostgreSQLでは、非一意索引のルート、ブランチ、リーフの各ブロックと表のデータ・ブロックの合計4ブロックへのアクセスが基本となるのに対し、MySQLでは非一意索引のルート、ブランチ、リーフ、クラスタ・インデックスのルート、ブランチ、リーフの6ブロックで行データにアクセスすることになるため、非一意索引スキャンではOracleDatabaseや PostgreSQLに優位性があると考えられます。
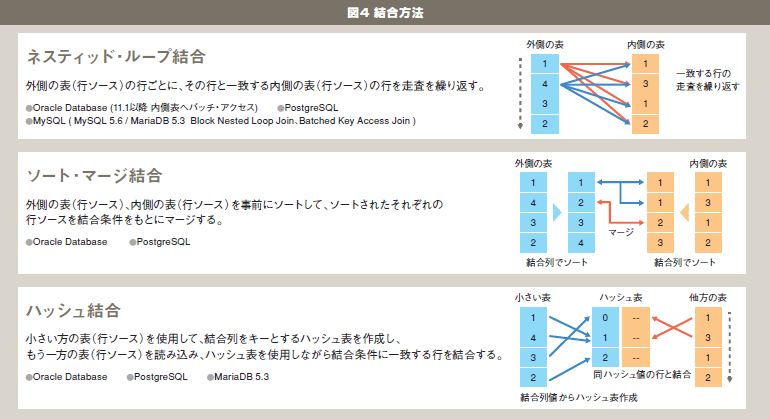
表結合とは、ある表の行データと関連する、もう一方の表の行データをつなぎ合わせる処理のことです。結合対象となる表同士には、結合のキーとなる情報を格納する列が存在し、結合キーの列値が一致する行データ同士を、あたかも1つの表の行データのように扱うことができます。表結合の方法には図4のようにネスティッド・ループ結合、ソート・マージ結合、ハッシュ結合があります。
|
図4 結合方法 |
ネスティッド・ループ結合は、結合の駆動軸となる外側の表の行データに一致する行を内側の表から見つけ出す方法です。外側の表の行データに一致する行を内側の表から見つける走査を繰り返すため、外側の表には、件数の少ない表を配置して繰り返し回数を少なくすること、内側の表の結合条件となる列には索引を作成し、索引スキャンを採用することがネスティッド・ループ結合を効率化させるポイントです。ソート・マージ結合やハッシュ結合は、主に結合結果の行ソース同士を結合させる必要が生じるなど、索引を利用した結合を行うことができない場合や、索引を利用する結合が適切ではない場合に、効率的に結合を行う方法です。
Oracle Database、PostgreSQLは、ネスティッド・ループ結合、ソート・マージ結合、ハッシュ結合が実装されていますが、MySQLはネスティッド・ループ結合のみ実装されているため、結合結果の行ソース同士を結合しなければならない多数表の結合の場合、Oracle DatabaseやPostgreSQLに優位性があると考えられます。
主なアクセス・パスと結合方法だけにフォーカスして、Oracle Database、PostgreSQL、MySQLの違いを説明しましたが、同じRDBMSでも個性があり、適用領域が少しずつ異なることがわかると思います。
|
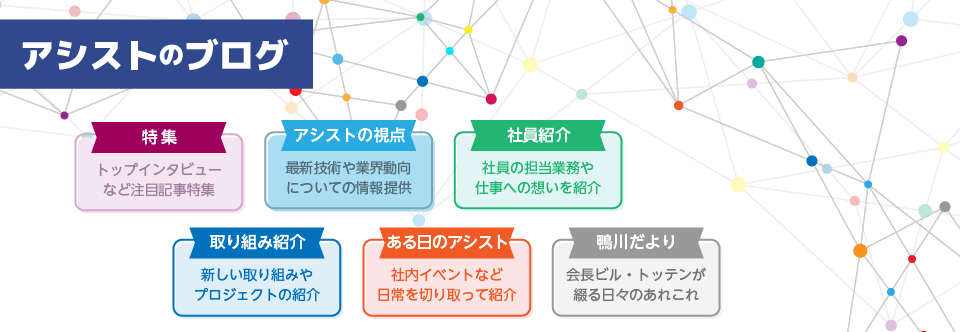
図5 結合方法と結合順序評価 |
例えば、MySQLのinnodbストレージ・エンジンでは、表は主キーを用いたクラスタ・インデックス構造であるため、主キーによるデータ操作に向いており、その特性を踏まえてデータ・モデルとSQLを設計すると期待した効果が得られます。一方、多数表の結合処理や副問い合わせを含む処理などは、アクセス・パスや結合方法が限られているのでMySQLの良さを発揮することが難しくなります。そのため、MySQLでは参照負荷を分散できるレプリケーション構成と合わせて、WebのバックエンドのデータベースとしてMySQLの特性を考慮したアプリケーションを開発しているケースが多いようです。
PostgreSQLはMySQLと比べるとOracle Databaseと類似した物理構造と索引アクセス、結合方法が実装されているため、より幅広く汎用的に利用できるRDBMSであると言えます。Webのバックエンドのデータベースとしても利用できますが、PostgreSQLのアクセス・パスの特性を考える場面は少なく、社内システムや業務システムなど、既存の商用RDBMSと同じような感覚で利用できるのが特長です。
Oracle Databaseは様々な用途で利用されているデファクト・スタンダードであり、実装されているアクセス・パスも多く、大量データ、大量の同時実行ユーザを扱うことを前提としたアーキテクチャが採用されているため、万能型で大規模向けRDBMSであると言えます。
RDBMSの採用ポイントは多岐にわたりますが、アクセス・パスでの適材適所を考えた場合、様々なタイプのアプリケーションからアクセスされるミッション・クリティカルな基幹システムのデータベースはOracle Database、特定業務の業務システムなどはPostgreSQL、主キー走査を主体としたアプリケーションを設計できるシステムの場合はMySQLを採用するなどの棲み分けが可能です。
また、参照負荷や更新負荷を分散させたい各サービスのフロントDBとしてMySQLやPostgreSQLを複数ノードに配置し、バックエンドのDBとしてOracle Databaseを採用することでシステム全体のワークロードを低コストで拡張、縮小できる柔軟性のある仕組みを実現できます。このように、適材適所でRDBMSの活用を検討してはいかがでしょうか。
|
|
岸和田 隆
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


アシストが設立以来培ってきた「ソフトウェアの目利き力」とは?商材発掘・調査の専門チーム「Bダッシュ委員会」が、生成AIの活用に挑戦するお客様向けに、エンタープライズサーチ「Glean」をどのように選定したのか、その経緯をご紹介します。

新商材・サービスの発掘・育成に取り組むBダッシュ委員会活動の中で、分散型自律組織(DAO)のビジネス適用の可能性を探り、アシストのビジネスにどう活かせるかを研究する「DAO分科会」についてご紹介します。

生成AI時代に改めて考えたいセキュリティ対策について、後編では「生成AIを活用したセキュリティ対策」を中心に解説します。