

筆者は、データモデリングを通じてお客様のプロジェクトを企画・要求定義段階からご支援しています。データモデリングは昔からある枯れた技術ですが、クラウド化が進むこの時代においても、データドリブンを推進する上で、データ自体の問題を解決するツールだと感じています。
本記事では、特に論理データモデリングに焦点を当てて、クラウド環境でどのようにデータ活用をしていくかについてご紹介します。
1. クラウド化でビジネスの成功がより現実のものに
昨今、クラウドへのリフト&シフトが勢いを増していますが、筆者はこれを時代の必然の流れと捉えています。なぜ必然なのか、また、クラウド化の波が、企業ビジネスを成功に導く重要な要因であるデータとその活用にどのようなメリットをもたらすのかについてご紹介します。
クラウドへのリフト&シフトが加速化するのは必然
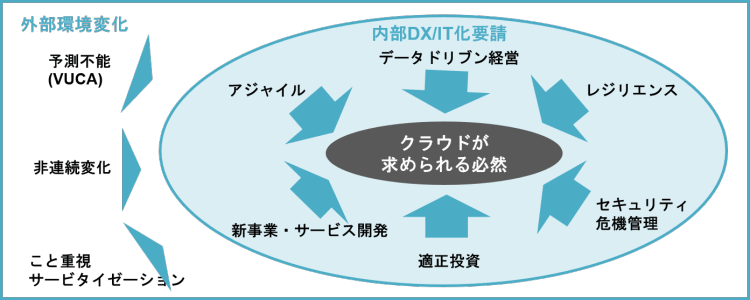
企業の外部環境を見れば、VUCA*といわれる不確実で予想不可能な時代であるとともに、その変化自体が非連続で発生しています。さらには、モノからコト重視(モノの所有に価値を見い出すのではなく商品やサービスの購入で得られる体験に価値を見い出す)となり、ビジネスのコアがサービス化するとともに、顧客体験価値を高めていくことが求められるようになってきました。
*VUCA:Volatility(変動性)、Uncertainty(不確実性)、Complexity(複雑性)、Ambiguity(曖昧性)の頭文字をとった造語。今後の予測がしにくい状況を表す。
このような外部環境に対応していくために、企業内部で求められることは、スピードすなわちアジャイルであること、新事業・新サービスを作っていくこと、データドリブン経営、そして、しなやかでレジリエンスなシステムであることです。また、不確実だからこそ、セキュリティや危機管理の強化も必要となり、かつ投資も適正でなければなりません。すなわち、上記の円の中にある6つの要素すべてについて、バランスをとることが求められています。この受け皿こそがクラウドであり、もはやクラウド化の流れは必然であると言えます。
データ活用におけるクラウド利用「五つの醍醐味」と企業がその先に見据えるもの
クラウドを前提としたデータ活用基盤では、フルマネージドな環境が強化されており、データドリブンをビジネスに取り込みやすくします。データ活用に焦点を当てると、クラウドの醍醐味は以下の五つのキーワードに集約されます。
(1)スケーラブル
物理的容量や処理性能の制約から解き放たれるスケーラブル性はクラウドならではのものです。
(2)多様化
データの種類や特性に合わせてリレーショナルデータベース(RDBMS)だけにとどまらない多様な実装環境を選択できます。また、複数のサービスにまたがったデータクエリもできるようになってきました。
(3)自動化
データパイプライン構築におけるデータやメタデータの自動収集といった機能があります。
(4)アジャイル
クラウドは、データの発生から利用に至るまでのフローをアジャイルに構築できる環境が整っており、xOpsにも適しています。
(5)民主化
ビジネスニーズに合わせて、高度な設定をすることなく、誰でも、柔軟に環境を構築し、展開できるようになってきました。
そして、クラウドを活用したその先に企業が見据えているのはもちろん「ビジネスの成功」です。それは、企業内外に増え続けるデータを統制・利活用して「データを競争優位に立つための企業資産とすること」に他なりません。
2. データに起因するデータ活用の壁
先ほどデータ活用におけるクラウドの醍醐味についてご紹介しましたが、クラウド環境で提供されるテクノロジーでデータ活用の容易性が増す一方、テクノロジーでは解決できないこともあります。ここで解決できる部分とできない部分について解説します。
クラウドのテクノロジーで解決できる部分
以下の図はデータを利用する側から見た一般的なデータ活用のプロセスを表しています。
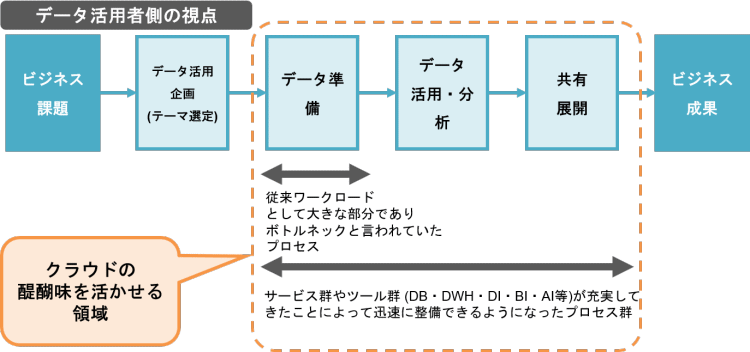
データ活用の究極の目的は、ビジネスの成功です。どの企業においても、データを活用するきっかけとなるのは「ビジネス課題」です。新規顧客開拓、販路拡大といったビジネス課題を解決するために、データ活用のテーマ選定を行い、データを準備して、データ活用・分析し、最後に分析環境の共有や展開するというプロセスを経て、最終的に課題を解決するという流れが一般的です。
図のオレンジの点線で囲っている部分に、データ整備、データ活用・分析、共有・展開という三つのプロセスがありますが、ここがいわばクラウド環境の醍醐味が生かせる部分となります。従来ワークロードとして大きく、ボトルネックといわれていた部分が「データ準備」ですが、このデータ準備を含め、クラウド上のサービス群やツール群(データベース、データウェアハウス、データ連携、BI、AI)が充実してきたことにより、迅速に整備できるようになりました。
クラウドのテクノロジーで解決できない部分
では、クラウドのテクノロジーで解決できない部分はどこかというと、クラウド環境が活用できるプロセス(データ準備以降)よりも手前の「企画段階」になります。
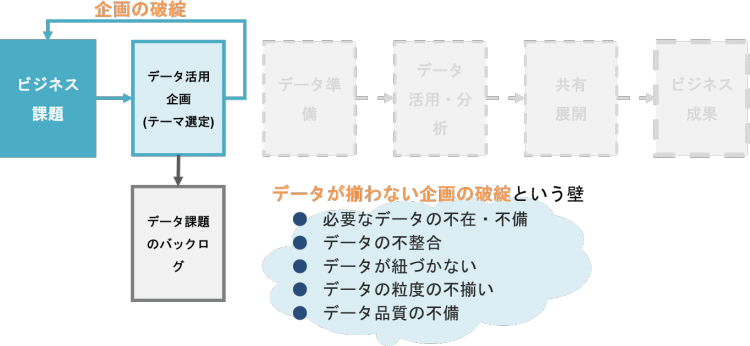
企画段階で「データ自体に問題がある」ことが発覚すると、企画自体が破綻してしまいます。以下でどういう問題なのか、具体的な例をご紹介します。
そもそも業務支援が目的で、データ分析が目的ではないため、分類や区分といった切り口となる
項目がない。企業戦略が変わったため、意味をなさなくなった古い項目が多く、逆に最新のデータがNULLだらけである。
現場の表計算ソフトがビジネス上の正となっているため、集計した数字が合わない。
年齢層、生年月日、年齢など、似て非なる項目が沢山あり、利便性も悪い。使う項目が属人化すると分析の精度に個人差が出る。
顧客名が複数のテーブルにあり、データ値に不整合が起きている。
同じマスターが複数あり、データの量や質が異なっている。
マスターの目的や対象が異なるため名寄せができない。
氏名と住所が別のテーブルにあるが、クレンジングしても不整合が起きている。
予備項目の中の一つは昨年から定義が変わった。データ項目が使い回されていて使えない。
システム改定時に使われなくなった項目が残っている。
マッチングテーブルを作らないと複数のマスターが紐付かない。
テーブルが紐付いているとわかっても人力作業で紐付けなければならない。
マッチングテーブルさえ作れないような孤児テーブルが散在している。
前工程と後工程が紐づいていないためトレースができない。
上記の例は、程度の差はあるものの、データ活用基盤を構築される方なら経験されたことがあるのではないでしょうか。データ自体に問題がなければ、データ整備以降のプロセスに流していけますが、問題があるとテクノロジーでは解決できないため、企画段階でとん挫してしまいます。
データ自体の問題はデータカタログで解決するのか
データ自体の問題について、「データカタログがあれば解決するのではないか」というご意見を伺ったことがありますので、データカタログの機能について簡単に整理してみます。特定の製品の話ではなく、あくまでも一般的な考え方としてお読みください。
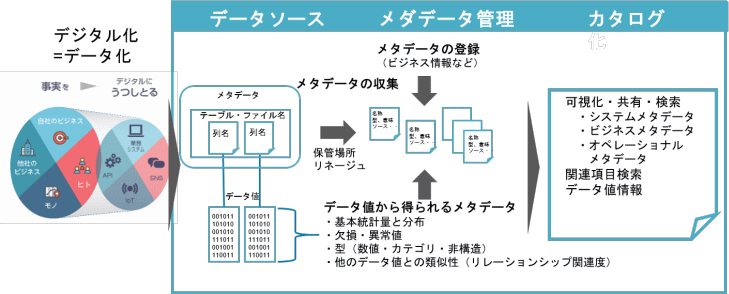
左側はデータの発生を表しています。ビジネスで起きた事実をデジタル化すなわちデータ化したものが右側のデータソースです。データソースはラベルであるメタデータとデータ値によって構成されています。
データカタログ自体はデータに関するデータ、すなわちメタデータを管理・ビジュアライズするツールです。一般的には、メタデータを収集したり、ビジネス情報などのメタデータを登録したり、場合によっては、データ値の情報を集約するなどして、ユーザーが見やすいように整理・カタログ化するものです。
しかし、データカタログがあったとしても、実際に目の当たりにするデータ群が次の図のような状態であったとしたらどうでしょうか。
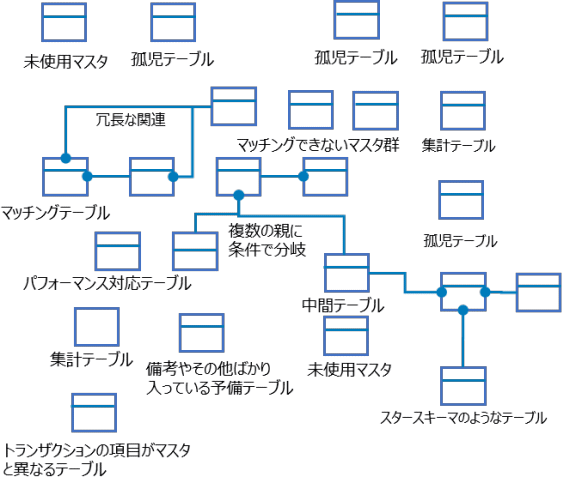
筆者も実際の支援現場でこのようなデータ群と出くわすことは少なくありません。そもそもこのように沢山の種類のデータがあるのは、既存のシステムやサービスの構築時の目的や、ユーザーからの要求といった理由があったからで、目的や理由の数だけデータ構造が存在するのはいたしかたのないことです。
しかし、ビジネス課題を解決したいデータ利用者から見れば、過去ではなく、今、必要なデータが、すぐに、品質的にも安心して使えるという状態が望ましいことはいうまでもありません。そうなると、「使えるデータをすぐに特定できて、そのデータに問題がないこと」。この二つを満たす必要があります。
データがどうなっていてもカタログ化はできますが、カタログがあっても使えないデータはやはり使えないと言わざるをえません。カタログ自体には、データの理解を促すメリットがありますが、データ自体に問題がある場合は、元となるデータの整備を並行して行わなければビジネス課題の解決には至りません。
データ自体の問題を解決するツール、それが「論理データモデリング」
ここまで、データを活用する側の視点で見てきましたが、ここからデータ活用の「基盤」を推進・管理する側の視点に切り替えて考えてみます。
既存のシステムにあるデータは、過去の個別プロジェクトやユーザーからの要求といった目的別に作られたものです。データ活用基盤を新たに構築する場合や、データ構造のリファクタリングを考える場合は、既存のデータ構造に引きずられないデータ構造にしなければなりません。
既存のデータ構造に引きずられてしまうと、複数のシステムをまたぐ場合に、目的別というサイロ化から抜け出せないことに加え、既存のデータには現在使われていないデータ、使い物にならないデータも数多くあり、整理も必要です。
本記事のテーマである「論理データモデル」は、数多くの個別目的を考慮することなく、純粋に企業ビジネスの視点からデータ本来の構造を整理したモデルです。
そして現実に存在するデータ群について、
●企業として本当に対処すべき重要なデータ課題は何なのか
●スリム化対象のデータはどこなのか
●データ活用のためになくてはならないデータは何か
を見極めるツールなのです。
データ活用促進における「論理データモデル」の役割
ここで、データを利用する側の視点とデータ基盤の推進・管理する側の視点を重ね合わせてみます。
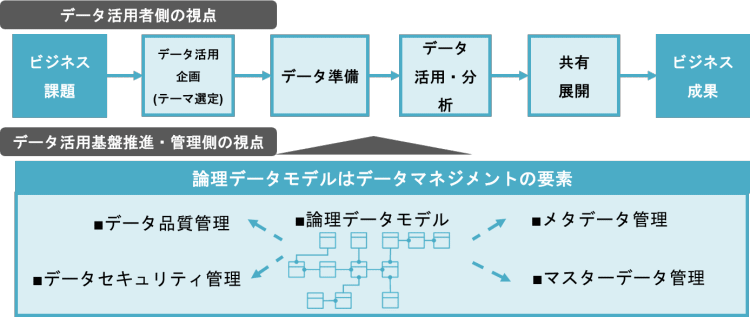
データ利用者が必要なデータを活用し続ける環境を構築するためには、データ活用を下支えするデータマネジメントの要素として、メタデータ管理、マスターデータ管理、品質管理、セキュリティ管理に加え、論理データモデルが必要です。また、論理データモデルは他の四つの要素を結びつける中核の役割を担います。
例えば、メタデータ管理やマスターデータ管理は、データモデルの構造そのものとして関わりますし、論理データモデル自体もメタデータです。データ品質にはデータモデルに表されているビジネスルールが関わってきます。データ・セキュリティ管理についても守るべきデータの識別のためにデータモデルを活用できます。
こうした活動が下支えとなることで、データ活用のプロセスが促進され、企画が破綻することなく、クラウド環境の醍醐味を享受できるようになります。
3. 論理データモデリングの特徴
ここからは論理データモデリングの特徴について見ていきましょう。
データモデリングの流れ
データモデリング自体は古くからある枯れた技術・考え方なので、ご存じの方も多いかと思います。データモデリングでは、下の図のように、概念データモデル、論理データモデル、物理データモデルの順に作成していきます。
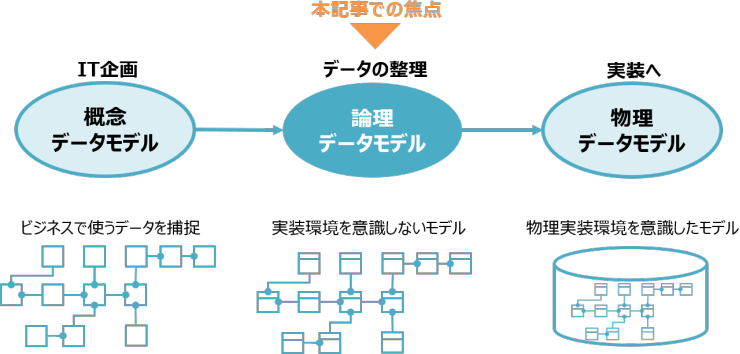
概念データモデルはIT企画で用いる道具です。実際のデータ項目を扱わずに、箱(E:エンティティ)と線(R:リレーションシップ)だけでビジネスで扱うデータを表し、システム化対象などを決めていきます。
論理データモデルは、概念データモデルと同様、ビジネスで扱うデータを表しますが、システム化対象となるデータについて、項目レベルまで詳細化したものになります。データの重複がないか、不備がないかを確認しながら、ビジネスにとって最適なデータ構造に整理したものが論理データモデルです。
概念データモデルを先に作成し、論理データモデルに落としこむ方式が王道ではありますが、整理するデータ項目の対象範囲が決まっていれば、いきなり論理データモデルからの作成も可能です。
最後の物理データモデルは、ビジネスに最適化した論理データモデルを実際の実装環境に合わせ最適化していくモデルとなります。
論理データモデルとは
論理データモデルは、データ本来の構造を定義したもので、「実装環境を意識しない」ということがとても重要なポイントです。そして、論理データモデルを端的に定義すると、以下の2点になります。
1.重複のないデータ構造を作り上げること、
すなわちOne Fact In One Placeの構造とすること
2.実世界すなわちビジネスの世界をERモデルにより箱(E:エンティティ)と
線(R:リレーションシップ)で可視化すること
以下はアシストのビジネスの一部を表した実際のERモデルです。アシストはソフトウェアの販売およびサポートを主な業務にしていますが、そこで発生するデータとそれぞれの関係性を箱と線で可視化しています。
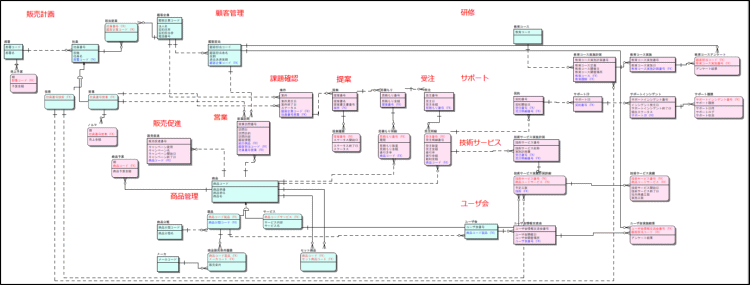
ERモデルはビジネスで扱うデータ群を箱と線だけで表現する非常にシンプルな文法ですが、ポンチ絵などとは異なり、誰が見ても同じ解釈しかできないため、データ整理や実装を行う関係者同士の標準化ツールとしても優れています。
論理データモデルの特徴
論理データモデルは、実装する環境(クラウドを例にした場合は様々なサービス群)とは完全に独立したものであり、普遍的であるため、あらゆる実装形態に対して共通の参照モデルになる点が大きな特徴です。
しかし、実装段階では、目的に応じて選択する実装方法に応じて最適な形に修正する必要があります(物理データモデリング)。これは性能面、運用面で後々問題が生じ、せっかく作ったデータ活用基盤が使えないという事態を回避しなければならないからです。
例えばアマゾン ウェブ サービス(AWS)のサービス上でデータの蓄積・利活用を考えたとしましょう。AWSではRDBMSですらないようなストレージ上のParquetファイルや、列指向RDBのRedshift、リレーショナルデータベース、さらには key-valueDBといった様々な実装環境が用意されています。論理データモデルをベースに、目的に応じて実装方法を選択し、それぞれのサービスのプロが最適な形で実装します。
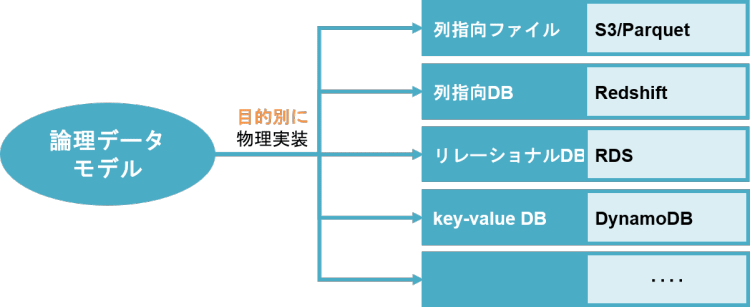
また、データウェアハウス構築においては、よくスタースキーマやスノーフレークスキーマといったデータ構造の話が持ち上がることが多いと思いますが、これらもまた物理データモデルの話になります。ここで、データウェアハウスの構築における代表的な三つのアーキテクチャを簡単にご紹介し、論理データモデルとの関連性を見ていきます。
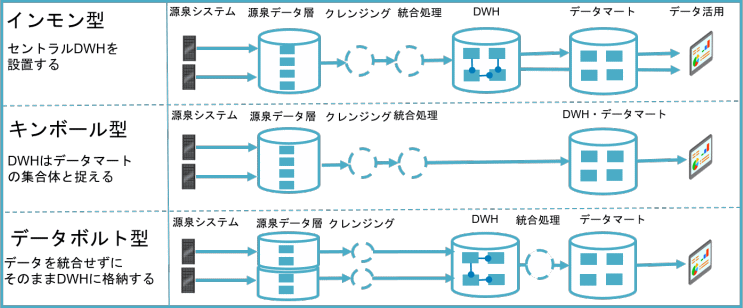
インモン型
インモン型は、セントラルデータウェアハウスを設置する考え方です。データの流れとしては、源泉システムを取り込んだ後、クレンジング、データ統合を行い、セントラルデータウェアハウスに格納して、必要に応じてデータマートを作成します。
キンボール型
キンボール型では、データウェアハウスはスタースキーマのような多次元分析用のモデルであるデータマートの集まりとして捉えます。そのため、インモン型と異なりセントラルデータウェアハウスがありません。
データボルト型
データボルト型は、データ統合せずにそのままデータウェアハウスに格納します。ビジネスが変わってもデータウェアハウスに入っているデータ構造は変わりません。例えばデータ項目が増えたり、源泉システムが増えてもデータをそのままの形でリレーショナルのデータウェアハウスにロードし、あとでSQLで統合します。
これら三つの型は考え方の違いであり、クラウドやオンプレミスといった環境を想定したものではないことにご注意ください。

論理データモデルは、普遍的なデータモデルですが、データウェアハウスの三つのアーキテクチャそれぞれで、データウェアハウスに持たせるデータの推奨スキーマが異なっている点は興味深いことです。
例えば、インモン型では、論理データモデルをほぼそのままの形で実装します。実装したデータそのものを企業資産として積み上げていきたいというビジョンがある場合にはインモン型が最適です。
期間的・予算的制約などによりセントラルデータウェアハウスを設置しないという選択肢を選んだ場合は、論理データモデルをベースに、スタースキーマやスノーフレークスキーマといった物理データモデルに変換することは難しくありません。
また、データボルト型では、モデル化のルールがはっきりと決まっているため、論理データモデルからデータボルトモデルに変換することも可能です。
このように論理データモデルはデータウェアハウスの様々な形態においてもアーキテクチャの都合に流されることがないという特徴があります。そして、論理データモデルは、個々の物理実装案件から見た場合は、共通の参照モデルとして位置付けられます。
論理データモデルの役割
論理データモデルを作るデータモデリングの工程は以下の通りです。
[1] データ構造 <One fact in One Placeの原則検討>
3NF
ビジネスに基づくキーの設定・統合
データ項目の統合・分割
データ本来の構造を定義するためには、One Fact In One Placeの原則を保証することが第一歩になります。
[2] ビジネスルール検証
ビジネスルールに基づくリレーションシップの検証
NULLの回避
アシストが考える論理データモデリングでは、論理データモデルはビジネスの世界で扱うデータを表したものと考えているため、ビジネスルールを正しく反映できているかどうかの検証を行います。
[3] 構造の安定性
ビジネスルール変更時のデータ構造安定性検証
こちらのフェーズにおいては、今現在のビジネスを正しく反映しているだけではなく、将来起こりうる変化も想定してデータ構造が安定しているかどうか検証を行います。
[4] 標準化
型や長さ・ドメインの適用
用語・命名規則・表記の標準化
同音異義語・異音同義語・別名の排除
論理データモデリングでは、構造だけではなく、型や長さ、用語や命名規則といった標準化を行うこともポイントです。
[5] メタデータの定義
データの来歴(ソースデータの定義)
エンティティ・データ項目の意味定義
データ構造そのもの
論理データモデリング実施時には、データの意味や出所といったメタデータの定義を推奨しています。
[6] データ履歴管理検討
このような工程を経て作成される論理データモデルによって、データが整理できるという本来の目的はもちろんですが、必要なデータの不在・不備、データ不整合、データが紐付かない、粒度の不揃い、データの品質不備、不要なデータの山といった、テクノロジーだけでは解決できないデータの諸問題の把握、対処方法などを検討するツールとして活用できます。
4. クラウド環境構成例ごとの論理データモデル活用例
さて、ここから、論理データモデルのクラウドでの活用について、以下の三つの構成例を交えながらご紹介します。
(1)データレイクとデータウェアハウスが連携している環境
(2)データ仮想化技術を導入している環境
(3)非構造化データと構造化データを一度に扱う環境
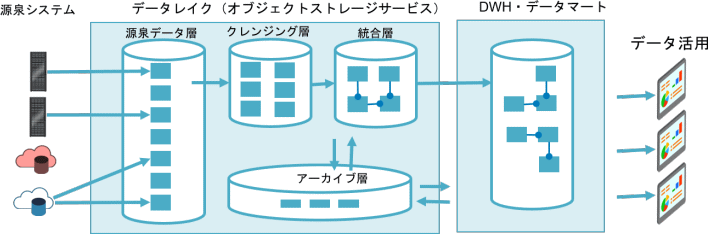
(1)データレイクとデータウェアハウスが連携している環境
ここでは、データレイクとデータウェアハウスが連携したデータ量の多い大規模なケースを想定しています。先ほど、インモン型やキンボール型といったデータウェアハウスのアーキテクチャを紹介しましたが、今回はハイブリッドの応用例です。
データの流れは、源泉データから、クレンジング、加工・統合、そしてデータウェアハウスへのロードやデータマートとの連携となっていますが、データ量が多い大規模なケースを想定しているため、データウェアハウスへロードする前に、安価で容量制限のないストレージサービスを使ったデータレイクと連携させています。
※クラウドでは多様な実装形態を選択可能なため、以下は推奨ではなくあくまで一例です。
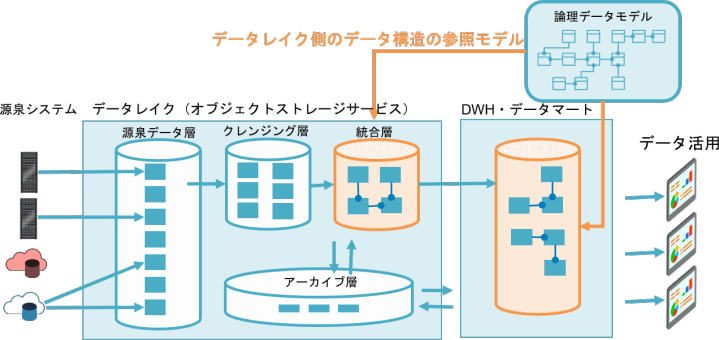
こちらの構成例では、複数のシステムのマスターやトランザクションから統合されたデータを、データレイク中の「統合層」で管理し、統合層のデータをデータウェアハウスやデータマートに連携させます。データレイク側、データウェアハウスやデータマート側でそれぞれデータ構造を検討・設計するのではなく、普遍的である「論理データモデル」を参照モデルとして活用することで、ぶれない・効率的な連携を実現します。
また、アーカイブ層の対象となるデータを検討する場面でも、時系列の観点に加え、データ構造を参照することも必要となるため、ここでも論理データモデルを活用できます。
(2)データ仮想化技術を導入している環境
二つ目は、データ仮想化技術を導入した場合の構成例です。図の上側では、物理的データ活用基盤構成を、下側では、仮想統合したデータウェアハウスとデータマートを配置した構成を示しています。
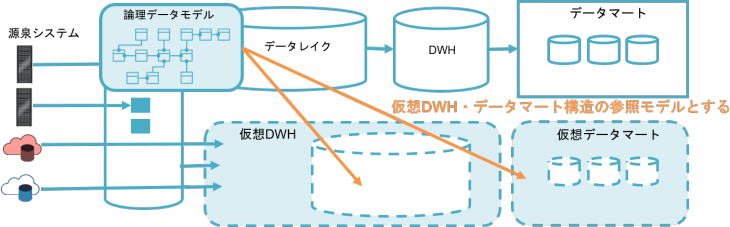
データ仮想化においては、データウェアハウスもデータマートも、もはや物理的に実装されておらず、物理データモデルという概念すらありません。しかし、仮想データウェアハウスの場合は、ビジネス面から考えるとデータは本来どのような関係を持っているのか、どのようにデータを持たせればよいのか、といった、データ構造に関するなんらかの基準が必要です。ここでも実装とは独立した普遍的な「論理データモデル」を、仮想データウェアハウスやデータマートの参照モデルとして活用します。
ちなみに仮想統合においては、クレンジングや変換処理といった複雑なデータ前処理が必要な場合、リアルのデータレイクやデータウェアハウスとの連携を検討する必要があります。本構成はあくまでも一例です。
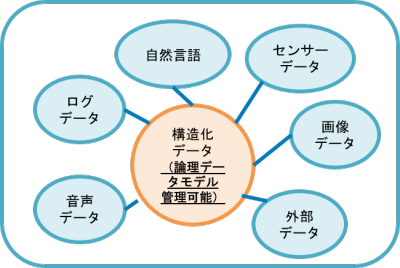
(3)非構造化データと構造化データを一度に扱う環境
次は、AI・機械学習の分野での構成例です。ここでは、画像や音声のような非構造化データと構造化データの両方を扱う分析案件を想定しています。いわゆるマルチモーダルAIです。例えば住宅価格の予測に住所、形状や築年数等といった構造化データの情報に加えて、間取り図といった画像データも組み合わせて予測するようなイメージですが、実際の案件でも、非構造化データ単独ではなく、構造化データと組み合わせることで、より高い分析精度を実現しているケースが多く見受けられます。
予測精度は、AIが学習するデータセットにどのようなデータ項目を持たせるかが大きく関わります。案件によっては、複数のテーブルから100を超えるようなテーブルを厳選して集めなければなりません。では、分析に大きな効果を与えるデータ項目をどうやって検討したらよいでしょうか。
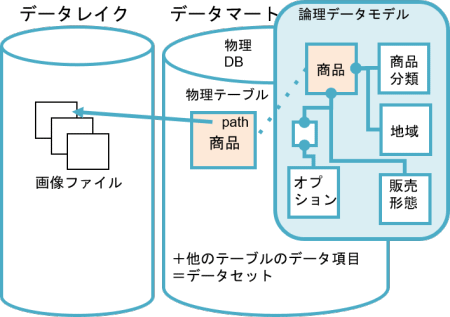
ここでも論理データモデルが役立ちます。非構造化データと構造化データの両方を扱う場合、非構造化データは格納先へのファイルパスやファイルIDというデータ項目として構造化データ側に表現されるケースが多く見受けられます。論理データモデルでは非構造化データそのものを扱うことができませんが、構造化データをハブとして非構造化データを位置付けることができます。
例えば、以下のように、構造化データである「商品」エンティティを中心に見た場合、論理データモデルを活用すれば、「商品」に関連する親テーブルや子テーブルも含めデータ分析に効果のあるデータ項目の検討が机上でやりやすくなります。データレイクにある商品の画像ファイルももちろん検討対象に含めることができます。
「商品」エンティティと同様、構造化データを中心に考えると、以下のように、「設備」エンティティとセンサーデータを紐づけたり、ログや音声データなど他の非構造データを紐付けることもできます。
非構造化データは構造化データと紐付けることで利用価値が高まります。両者を紐付ける案件では、論理データモデルで管理可能な構造化データを非構造化データのハブとして機能させるのがよいでしょう。
5. ユースケースごとの論理データモデル活用例
どのような場面で論理データモデルを活用すれば効果があるか、以下のユースケースごとの論理データモデル活用例をご紹介します。
(1)データのスリム化に活用
(2)共通モデルの整備とIT企画への活用
(3)データ分析の専門家組織での活用
(4)データ活用のための人財育成に活用
(1)データのスリム化に活用
論理データモデルを使ってデータのスリム化を実施してからデータ活用基盤を構築するという事例は、アシストのお客様でも数多く実績があります。
既存のシステムには構築当初の目的がありますが、目的の変更や、仕様追加によって、経過とともに似て非なるデータ項目が相当数散在するということはどのシステムにもありがちです。しかし、似て非なるデータ項目が散在した環境でデータ活用を行うと、どのデータ項目をレポート作成に使うかによってレポート品質にばらつきが生じたり、レポート作成工数が増大するといった課題が生じます。
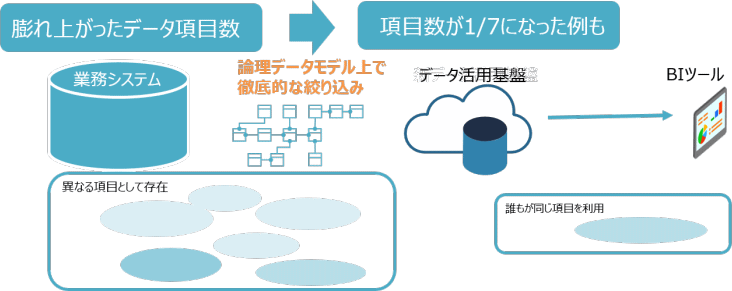
A社では、論理データモデルを使って、データ項目を徹底的に吟味した結果、業務パッケージのデータ項目数に対し、データ活用基盤側では約1/7まで圧縮することに成功しました。例えば約10,000項目あったものが、1,500項目まで圧縮できたことになります。
このように、スリム化によってデータ利用の属人化が排除されるため、データ品質が向上するだけでなく、結果的にメンテナンス性も高まります。また、論理データモデル上で業務上の不都合がないように配慮しながらデータ項目を厳選するため、スリム化しても業務にはまったく影響しません。さらに、論理データモデルをもとにデータ活用基盤を設計するため、業務システムのバージョンアップやリプレースに対してBIアプリケーションの変更を最小にできるという効果もあります。
(2)共通モデルの整備とIT企画への活用
基幹システムやその他のシステム、データ活用基盤の構築を予定している時期に、論理データモデリングを実施する顧客企業も数多くあります。
B社では、基幹システムと同時にデータ活用基盤の再構築を見据えたIT企画を検討中の時に、論理データモデリングを実施しました。
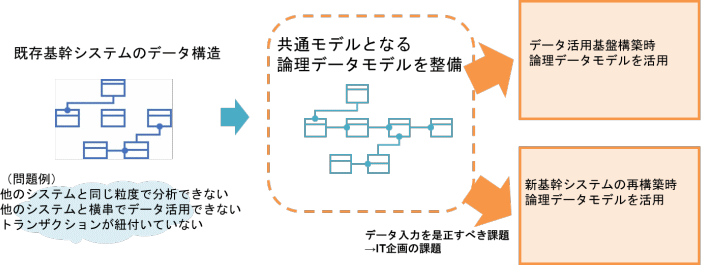
B社では、既存の基幹システムや他システムがそれぞれサイロ化していたため、データ活用基盤の再構築検討にあたり、同じ粒度で分析できない、横串でデータを活用できないという課題を抱えていました。また同一システム内でもトランザクションが紐付いていないため、業務ごとにデータが分断していてデータ活用ができないという課題も浮き彫りになっていました。
そこで、基幹システムやデータ活用基盤の再構築だけでなく、今後のIT企画も見据え、構築に入る前に、一度関連データの関係性を可視化してみようということになり、論理データモデリングを実施したのです。そして、既存システムのデータ課題を洗い出し、課題解決策を盛り込んだ論理データモデルを作り上げたため、以降に予定していた基幹システムやデータ活用基盤の再構築企画の共通モデルとして活用できるようになりました。
このように、共通モデルとして活用できるということが、目的に依存しない論理データモデルならではの使い方とも言えます。
(3)データ分析の専門家組織での活用
アシストの顧客企業でも、データスチュワードとデータサイエンティストで構成されるデータ分析の専門家組織を持つ企業が増えてきました。通常は、データ分析案件が発生すると、データスチュワードがデータサイエンティストにデータセットを渡して分析を行うという流れになっています。
データを分析する側は当然のことながら受け取ったデータセットの範囲内での分析に集中します。C社では、分析の精度と質を高めるという目的のために、案件の都度、データスチュワードが、データサイエンティストへデータセットを渡すのではなく、論理データモデルを作成してデータについての知見をデータサイエンティストへ共有するという流れに変更しました。
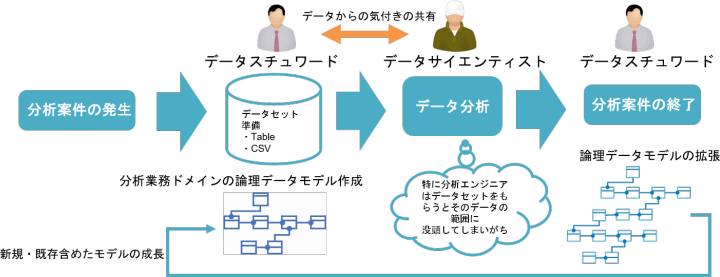
作成した論理データモデルは分析案件終了後に拡張し、次回別案件が発生した時点で再利用可能な部分は再利用するという形にすることで、案件を重ねるごとに全体を拡張・整備できるようになります。
(4)データ活用のための人財育成に活用
最後に、論理データモデルを人財育成に役立てている例をご紹介します。D社では、データ活用基盤推進・管理部門が論理データモデルを中心とした社内データ利用のガイド文書を策定しています。
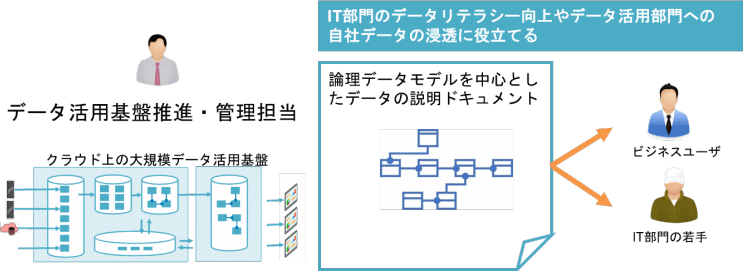
この文書を共有することで、これまでシステム構築に関わる関係者しか知らなかった重要データを、IT部門の全員、そしてデータを活用するユーザーからも参照できる状態にしました。データを利用するビジネス部門にとっては、活用する主要データ項目の構成やリレーションシップを把握することができるようになりました。またIT部門では、若手社員のリテラシー向上に役立てています。
6. クラウド時代の論理データモデル活用まとめ
これまでご紹介してきた論理データモデルの役割は、以下の2点にまとめられます。
1. クラウドの多様なサービスに実装可能な共通参照モデル
論理データモデルがクラウドのサービスやアーキテクチャから独立している点は、多様化が当たり前のクラウド環境において親和性を発揮するポイントとなります。
2. データ活用や、データマネジメントにおいてデータから気付きをえるための道具
データセットの設計やデータサイエンスのデータ理解を補助するといったステージでの使い方もご紹介しました。また、データマネジメントにおいては、データ品質、マスターデータ管理、メタデータ管理といったデータマネジメントの要素を紐付ける接点としての役割もあります。
データモデリングは基本的な教育と実践による正しい訓練を受ければ誰でも習得可能な技術です。そして、テクノロジーの選択肢が劇的に増えてきた時代だからこそ、枯れていて、変わることなく、テクノロジーに影響をうけない「論理データモデル」は、DX推進、そしてクラウドへのリフト&シフトにおいても身に付けておきたいスキルの一つと言えるのではないでしょうか。
<執筆者のご紹介>

矢野 勝彦
開発技術本部
1996年中途にて入社。エンジニアを経て1999年以降、お客様のIT企画を支援するサービスに従事。アシスト独自のサービス立ち上げにも関わる。現在はサービスの品質管理にも注力している。趣味のKaggleではソロ銀メダル等も獲得。
ページトップへ戻る