


- アシストの視点
Bダッシュ委員会 DAO分科会発信
「DAOをビジネスに適用できるか」社内で実証実験
新商材・サービスの発掘・育成に取り組むBダッシュ委員会活動の中で、分散型自律組織(DAO)のビジネス適用の可能性を探り、アシストのビジネスにどう活かせるかを研究する「DAO分科会」についてご紹介します。
![]()





|
|
大量のデータから知見を得るという「ビッグデータ」の概念が世に出て久しい中、「IoT(Internet of Things)」や「M2M(Machine to Machine)」といった技術発展により「ビッグデータ」というキーワードをさらによく耳にするようになりました。ビッグデータの活用においては、データの収集、蓄積、処理/分析という3つの技術を押さえる必要があります。今回はその中でデータ蓄積/処理の中核技術に焦点を当ててみたいと思います。
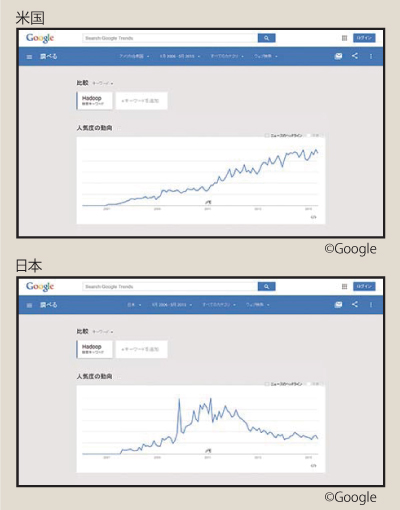
本稿の執筆に際し、Googleトレンドで「Hadoop」がどれくらい検索されているのかを確認しました。下図は米国と日本のトレンドを示すグラフですが、特徴的な結果が出ています。
|
|
米国では今なお右肩上がりのトレンドであり、主要先進諸国も米国と同様の傾向にありましたが、それと比べると日本は特徴的で2011年2月をピークに下降線を辿っています。なお、「ビッグデータ」や「IoT」、「M2M」といったキーワードについては、日本も欧米諸国と同様のトレンドを示していました。
これが意味する所は、日本におけるHadoopへの関心が薄れているということなのでしょうか。データ蓄積/処理の中核技術となるHadoopとリレーショナル・データベース(RDBMS)について振り返り、対極となる米国での活用について見ていきたいと思います。
「Hadoop」はデータを複数のサーバに分散して配置するファイル・システム(HDFS)と、それらデータを並列分散処理(MapReduce Framework)するソフトウェア基盤です。簡単に言えば、テラやペタバイト級の大量データを貯める機能と貯めたデータを処理する機能が提供されており、ビッグデータ活用を支える主要技術の1つです。
また、データ量や処理負荷に応じてスケールアウトが簡単に行えることが特長の1つです。安価なコモディティ・サーバを複数連携させて大量のデータを並列分散処理でき、その性能はサーバ台数に比例してスケールする特性を持ちます。つまり、超並列処理専用機に比べて大量データを簡単かつ安価に、そして高速に並列分散処理する革新的で強力な技術として登場したのがHadoopです。
さらにHadoopの特長はそのエコシステムにあります。前述の機能を提供するHadoopというソフトウェア基盤上で様々な補完機能を提供するツールが数多く登場しており、それらツール群は「Hadoopファミリー」と称されています。例えば、通常MapReduce処理はJavaでコーディングしなければならず、必ずしも生産性が高いとは言えません。Hadoopファミリーの1つである「Pig」はMapReduceの実行が可能な簡易言語を提供し、Javaコーディングよりも簡易に高い生産性で処理開発が行えます。他にも補完機能を提供するHadoopファミリーは数多く存在し、Hadoopを中核として有機的に結びつき成長していくエコシステムが形成されています。
現在、Hadoopとファミリーの多くは、Apacheソフトウェア財団がトップ・プロジェクトで管理するオープンソース・ソフトウェア(OSS)です。世界規模の開発貢献者コミュニティによって開発が進んでおり、その進化は急速です。
当初のHadoopは、並列分散処理環境の特性を活かした大量データのバッチ処理基盤としての性質が強く、非構造な大量データをより高速に、そして簡易で安価に処理できることにメリットがありました。その反面、構造化データに対する処理性能や処理効率性を追求するためには、より高度なリソース管理が必要でした。また、MapReduceを利用するには難易度の高いJavaコーディングが必要なため、ユーザビリティの面での課題もありました。つまりは、Hadoopが持つ大量データに対する並列分散処理の利点を残したまま、既存のRDBMSのようにレスポンス良く手軽に扱いたいという欲求の現れです。
これを背景に、それまでのHadoopがHadoop1.0とするとHadoop2.0への進化が訪れます。処理効率性の課題を解決するため、Hadoopのリソース制御を切り出し別途実装されたYARNが登場し、処理スループットの向上とMapReduce以外の分散処理方式のサポートを達成します。これにより、処理のたびにHDFSへの書き込みが発生するMapReduceとは異なり、インメモリでの並列分散処理も可能な応答性の高い(低レイテンシ)処理が実現できるようになりました。同時に「SQL on Hadoop」という概念のもと、最も身近なデータ操作言語であるSQLの処理エンジンをHadoopに実装できるようになり、並列分散処理を活かしつつSQLでHadoopを操作することができるようになります。
このようにHadoopの進化を振り返ると、我々がよく知るところのRDBMSに徐々に近づいているようにも見えます。これに対してRDBMS、特にHadoopと同じ領域で利用されることの多いデータ・ウェアハウス・データベース(DWHDB)の進化はどうなっているのでしょうか。
その代表格であり弊社で取り扱うVerticaを始め、GreenPlum、PureData(旧Netezza)、Teradataなどは、並列処理が可能な「MPP(Massively Parallel Processing)」、データの配置を分散し共有ディスクを必要としない「シェアードナッシング」といったアーキテクチャを採用しており、Hadoopと同様にデータ量や処理負荷に応じたスケールアウトが可能です。またRDBMSは構造化されたデータの取り扱いについては格段の優位性を今なお有しながら、Hadoopが得意とする準構造化データや非構造データの扱いも始めています。
このようにHadoopとRDBMS(特にDWHDB)は、互いに双方の得意領域に歩み寄りつつあります。HadoopはOSSであり、コモディティ・サーバを指向するのに対し、DWHDBはプロプライエタリ・ソフトウェアであり、DWHDBの一部は専用ハードウェアを指向します。またそれぞれの構築におけるコスト構造では、Hadoopは作業コストに、対してDWHDBはハードウェア+ソフトウェア・コストに比重が高くなる傾向にあります。このような比較点はいくつかあるものの、大量データを並列処理するという目的においての違いは曖昧になりつつあります。
このような両者の違いが曖昧な状況が、冒頭に挙げたように日本でHadoopの関心が低下する要因となっているのかもしれません。
では、企業における情報システムはどのように向き合うべきなのでしょうか。冒頭で比較に挙げた米国でのトレンドを確認することでそのヒントが見つけられるかもしれません。
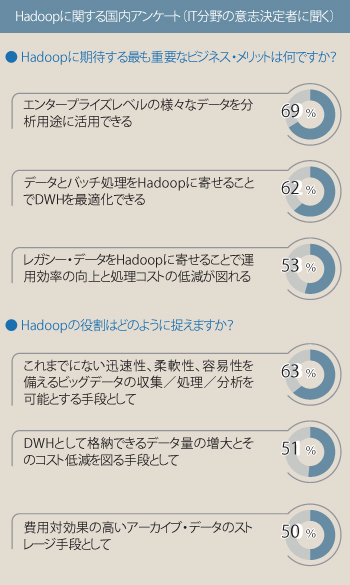
下記は、米国内での100人に及ぶIT分野の意思決定者へのHadoopに関するアンケート結果です。(Syncsort社調べ)
|
|
現在、米国でのHadoop活用におけるトレンドは、すべてのデータを集約する基盤にHadoopを活用し、そのデータの流れの先にDWHDBをはじめとした従来のデータ分析基盤を置くというものです。
|
|
といったことが可能となり、先に挙げたアンケート結果に表れるポイントが押さえらえた形となっています。
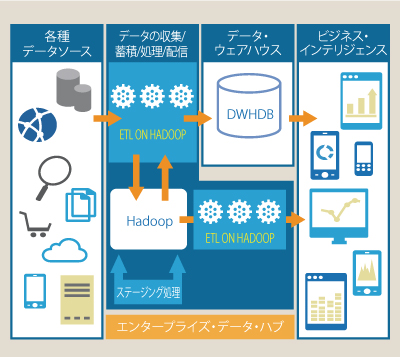
このようにビッグデータ活用の中核をなすデータの蓄積/処理基盤にHadoopを据え、そこで加工し構造化されたデータをDWHDBに送るなど、必要に応じて必要な加工を施したデータを必要なところへ必要な分だけ送る基盤としてHadoopを機能させています。米国におけるこのトレンドは、「データの湖(Data Lake)」や「エンタープライズ・データ・ハブ(EDH)」といったキーワードで表現されており、HadoopおよびDWHDBそれぞれの得意領域を生かしたビッグデータ活用における現時点での最適解の1つとなっています。
米国でのアンケート結果やトレンドが示すように、適材適所の選択によってHadoopは経営への貢献が高いという認識が拡がり、普及が始まっています。また、Hadoopに限らずビッグデータ活用の分野ではNoSQLやストリーミング処理など、新たな技術やトレンドが次々と登場しています。裏を返せば、企業活動の優位性に直結する分野であるからこその移り変わりの速さであるとも言えます。混沌としている今だからこそ、いずれは自社のビジネスに採り入れるという視点で、トレンドを把握し技術評価を継続して行うことが、IT部門の経営貢献という観点において重要なのかもしれません。
昨今日本においてもIT部門の経営貢献が強く求められています。弊社でもビッグデータ活用に注目し、情報活用分野で培ったノウハウに加えて、データの蓄積/処理に優れたHadoopとその周辺分野を含めた製品サービスを拡大しています。具体的には、Hadoop構築をオールインワン化した「御まとめHadoopパック」、専用ハードウェアではなくIAサーバでスケールアウトが可能なDWHDB「Vertica」、MapReduce コーディングの必要なしにGUIによるHadoop ETL処理の開発が可能な「SyncsortDMX-h」といった製品を取り揃え、ビッグデータ活用のお役に立つご提案をして参ります。
|
|
田中 貴之
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


新商材・サービスの発掘・育成に取り組むBダッシュ委員会活動の中で、分散型自律組織(DAO)のビジネス適用の可能性を探り、アシストのビジネスにどう活かせるかを研究する「DAO分科会」についてご紹介します。

生成AI時代に改めて考えたいセキュリティ対策について、後編では「生成AIを活用したセキュリティ対策」を中心に解説します。

生成AI時代に改めて考えたいセキュリティ対策について、前編では「生成AIが使われる攻撃への対策」、「生成AIを利用する場合の対策」を中心に解説します。