





- Oracle Cloud
- Oracle Database
気になるテーマから学べる!無料オンデマンド動画「OCI入門者向けウェビナー」のご紹介
OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。
![]()






|
|
前回はOracle Database 12c(以下、12c)のセキュリティ新機能について解説しました。今回は、移行後すぐに使える便利なオプティマイザ関連の新機能を紹介します。
12cが国内で出荷されてからおよそ1年が経ち、新規システムでの採用や既存システムのバージョンアップを本格的に検討しているという声を多く耳にするようになりました。Oracle Multitenantをはじめとする新機能や、Oracle Open World 2013で発表されたインメモリの機能には、非常に高い期待が寄せられています。
その一方で、バージョンアップの話題になると「オプティマイザの動作に変更はありましたか?」というご質問をいただくことが多々あります。これは期待というよりも、むしろ不安の方が大きいようです。Oracle Database 10gR1でルール・ベース・オプティマイザがサポートされなくなって以来、コスト・ベース・オプティマイザと賢く付き合うことが性能安定の必須条件になりましたが、実行計画が意図しない方向に変わらないか心配だという声が多く、これがバージョンアップを躊躇する理由の1つとなっています。
どうしてもマイナス面の影響を心配してしまうコスト・ベース・オプティマイザですが、本来はデータの偏りや量に基づいて最適な実行計画を選択するために実装された機能なので、バージョンが上がれば当然その精度も上がるはずです。通常はデータベースのバージョンアップとハードウェアの更改を同時に行うことが多いため、SQLのレスポンスが良くなってもオプティマイザが注目されることは少ないのですが、見えないところで確実に進化を続けています。
以下の表は、12cにおけるオプティマイザ関連の新機能と、非推奨の機能をまとめたものです。新機能には、以前「連載:徹底解説!Oracle Database 12cのすべて」の中で解説した適応計画や自動再最適化をはじめ、より最適な実行計画が選択されやすくなる機能が多く実装されています。非推奨となった機能に注意しつつ、これらの新機能を活用していけば、以前のバージョンよりも安定した実行計画でデータベースを運用できるはずです。
| 機能名 | 概要 |
|---|---|
| 適応計画 (※1) | 問合せ実行時に収集した統計を基に、プランの一部を実行時の条件に適したサブ・プランに切り替えられる。 |
| 自動再最適化 | 問合せ実行時に収集した統計が見積りと大きく異なる場合、カーソルに情報を記録。次回の問合せ実行時に記録した統計を使用してプランを作成できる。 |
| SQL計画ディレクティブ | 問合せ実行時にカーディナリティが誤って見積もられた場合、SYSAUX表領域に情報を記録。この情報を基に、DBMS_STATSプロシージャで拡張統計が収集できる。 |
| 動的統計の拡張 | すべてのSQLに対して使用する動的統計レベルを自動的に決定できる。 |
| バルク・ロードのオンライン統計収集 | バルク・ロードの操作の中で統計を自動的に収集できる。 |
| オプティマイザ統計の自動収集 | 複数の表、パーティション、サブ・パーティションに対して統計情報を並行して収集できる。 |
| グローバル一時表のセッション固有統計 | グローバル一時表の統計を共有するか、セッション固有のものにするか選択できる。 |
| 新しいヒストグラム | 上位頻度ヒストグラム、ハイブリッド・ヒストグラムを作成できる。 |
| SPM展開アドバイザ | SQL計画管理(SPM)の検証と承認を日次メンテナンス・ウィンドウで実行できる。 |
(※1)マニュアルによって「適合計画」や「適用計画」と表記されている場合もありますが、本稿では『SQLチューニング・ガイド』に従って「適応計画」とします。
| 機能名 | 代替手段 |
|---|---|
| ストアド・アウトライン | SQL計画管理を使用する。 |
|
初期化パラメータ CURSOR_SHARING=SIMILAR |
同パラメータの値をFORCEに設定する(※2) |
(※2)ただし、ソフト解析時に共有プール内で類似文を検索するというオーバーヘッドが生じるので、使用にあたっては注意が必要です。
今回は、動的統計の拡張と新しいヒストグラムに着目し、12c以前のバージョンとの違いについて説明していきます。
動的サンプリング(Dynamic Sampling)はOracle 9i Databaseから実装されている機能で、コスト・ベース・オプティマイザがSQLを解析する際に動的に統計情報を収集するというものです。作成されたばかりの表や、長期間統計情報が収集されていない表でも適切な実行計画を選択できるようになりますが、初期化パラメータのoptimizer_dynamic_samplingを0から10のどれにするかによって動作が変わるため、適切な設定を判断しにくいという課題がありました。そのため、0(無効)またはデフォルト値である2に設定されているケースがほとんどで、有効活用されているとは言いにくい機能でした。
| 値 | 動的サンプリングの動作 | サンプリングされるブロック数 |
|---|---|---|
| 0 | 動的サンプリングを行わない。 | なし |
| 1 |
以下の条件を満たす場合のみ、統計情報が収集されていないすべての表に対して動的サンプリングを実施。 ・非パーティション表。 ・索引が存在しない。 動的サンプリングのブロック数より、表全体のブロック数が多い。 |
32 |
| 2 | 統計情報が収集されていないすべての表に対して動的サンプリングを実施(2がデフォルト)。 | 64 |
| 3 | 統計情報が収集されていない表、または収集済でもWHERE句の述語で使用される式が1つ以上ある場合に動的サンプリングを実施。 | 64 |
| 4 | 「3」に該当する表、またはWHERE句で2つ以上の列に対する条件が指定されている場合に動的サンプリングを実施。 | 64 |
| 5~10 | 「4」に該当する場合に動的サンプリングを実施。 |
5の場合:128 6の場合:256 7の場合:512 8の場合:1024 9の場合:4086 10の場合:すべてのブロック |
12cでは、動的サンプリングから動的統計(Dynamic Statistics)という機能名に変更され、さらにoptimizer_dynamic_samplingに11という新しい値が追加されました(若干ややこしいのですが、初期化パラメータ名はoptimizer_dynamic_"sampling”のままです。statisticsではありません)。
optimizer_dynamic_samplingを11に設定すると、オプティマイザが必要だと判断した場合に自動的に統計が収集されるようになります。いわゆるお任せ設定で、サンプリングのブロック数を含めてすべて自動的に判断されます。これにより、optimizer_dynamic_samplingを0から10のどれにするか悩むのではなく、11に設定してすべてオプティマイザに任せるという新しい選択肢が増えました。この機能はOracle Database 11gR2(以下、11gR2)のターミナル・リリースである11.2.0.4にも搭載されているため、12cへのバージョンアップ前に使用することもできます。
それでは、簡単な検証でoptimizer_dynamic_samplingを11に設定した時の効果を確認してみましょう。今回は100,000行ある社員表の中から、名前が「A」で始まる社員の情報だけを検索するというSELECT文を実行します。その際、optimizer_dynamic_samplingを11に設定して動的統計を発生させ、オプティマイザが正しい行数を見積もれるのかを確認してみます。なお、名前が「A」で始まる社員の情報は100,000行のうち2,000行あり、それらのデータは特定のデータ・ブロックに集中しないよう分散されているものとします。
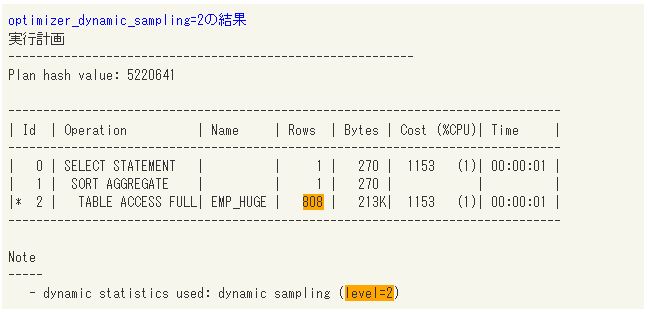
まずは、12cのデフォルトであるoptimizer_dynamic_sampling=2の結果から確認します。2に設定した場合はサンプリングのブロック数が64と少ないため、今回のように行数の多い表にはあまり向いていません。名前が「A」ではじまる社員の情報は2,000行ありますが、オプティマイザによる見積り結果は808行となっており、かなりの開きがあります。
|
optimizer_dynamic_sampling=2の結果 |
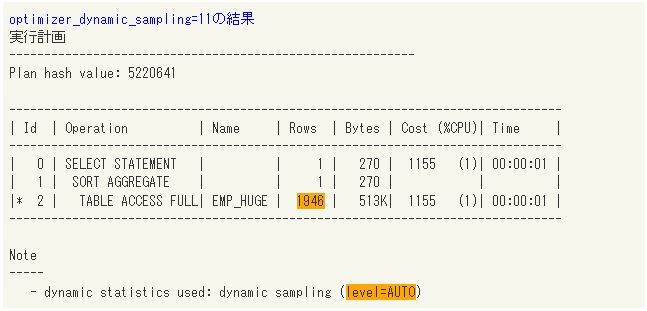
続いて、新しく設定できるようになったoptimizer_dynamic_sampling=11の結果を確認します。11に設定すると、動的統計の動作がオプティマイザによって自動的に制御されるため、2に設定した時よりも柔軟に対応できるはずです。今回の検証では見積り結果が1,946行となっており、optimizer_dynamic_sampling=2の場合よりも正確な値が出ることを確認できました。
|
optimizer_dynamic_sampling=11の結果 |
適切なタイミングで統計情報を収集しているデータベースでは出番のない機能かもしれませんが、何らかの理由で統計情報と実際のデータに大きな差異が生じてしまった場合には、最適な実行計画を得るための一助となってくれるはずです。ただし、オプティマイザのトレースを取得しても詳細な情報が出力されないなど、ユーザから見えにくい部分も多少あります。自動化とのトレードオフとして許容できるかどうか見極めたうえで使用することをお勧めします。
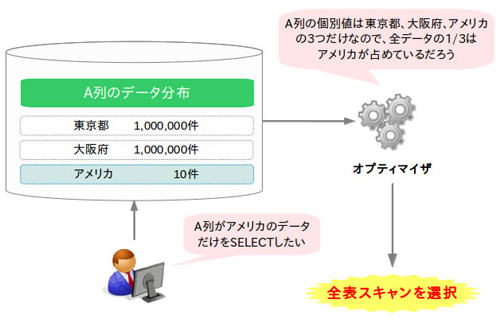
ヒストグラムは、列データの分布状況を表現したもので、データにどの程度偏りがあるのかをオプティマイザに伝えるという役割を果たします。例えば以下のような表がある場合、ヒストグラムがなければオプティマイザはデータが均等に分布しているものと判断するため、最適な実行計画を選択できないことがあります。
|
ヒストグラムがない場合の動作 |
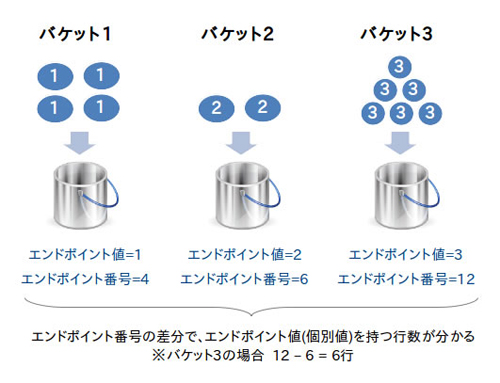
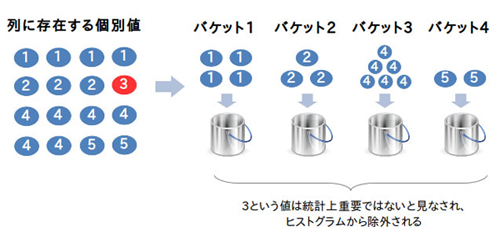
11gR2の時点で使用できるヒストグラムには、「頻度ヒストグラム」「高さ調整済ヒストグラム」の2種類があります。頻度ヒストグラムは、列の個別値がヒストグラム収集時に指定したバケット数以下の場合に生成され、各バケットにそれぞれ個別値を格納します。何だか難しく聞こえるかもしれませが、以下のようにバケット(=バケツ)の中に値を1つひとつ入れるだけというシンプルな方法です。頻度ヒストグラムでは個別値の分布をほぼ正確に把握できますが、バケット数が最大254までという制限があるため、個別値が多い列には使用できません。
|
頻度ヒストグラム |
高さ調整済ヒストグラムは、列の個別値がヒストグラム収集時に指定したバケット数より多い場合に作成され、各バケットにあらかじめソートした値を同数ずつ格納します。頻度ヒストグラムのようにそれぞれの個別値が何行あるのかまでは分かりませんが、以下のようにバケットに格納された最後の値を記録していくことで、おおよその分布を把握することができます。
|
高さ調整済ヒストグラム |
12cでは、先ほど説明した2つに加え、新しく「上位頻度ヒストグラム」と「ハイブリッド・ヒストグラム」が追加されました。上位頻度ヒストグラムは、その名のとおり頻度ヒストグラムから派生したもので、個別値の中でも特に割合の多いものだけを対象としたヒストグラムです。
11gまでは列の個別値がヒストグラム収集時に指定したバケット数より多い場合に、高さ調整済ヒストグラムが作成されていましたが、12cでは上位n個の個別値がデータの大半を占めているような場合には、上位頻度ヒストグラムが作成されます。これにより、上位n個についてはオプティマイザが正確に行数を見積ることができます。
|
12c新機能:上位頻度ヒストグラム |
もう1つの新機能であるハイブリッド・ヒストグラムは、高さ調整済ヒストグラムと頻度ヒストグラムを組み合わせたものです。まず、高さ調整済ヒストグラムのように各バケットに同数ずつ値を格納していき、そのあとで同じ値が複数のバケットに入らないよう調整を行います。そうしてできたバケットに格納されている最後の値が何行あるのかを記録していくことで、頻出する値に対して正確な見積りができるようになります。
|
12c新機能:ハイブリッド・ヒストグラム |
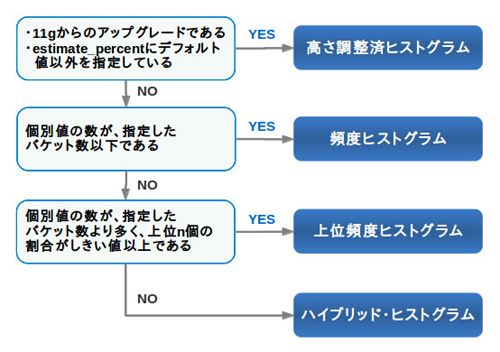
上位頻度ヒストグラムとハイブリッド・ヒストグラムを加えると、12cでは全部で4つのヒストグラムが存在することになりますが、このうちどれが作成されるか以下のフローに従って決まります。高さ調整済ヒストグラムは「レガシー」という位置づけになり、11gからアップグレードしたデータベースである場合や、estimate_percentをデフォルト値以外に指定した場合を除いて作成されなくなっています。11gまで高さ調整済ヒストグラムが作成されていたケースにおいては、上位頻度ヒストグラムまたはハイブリッド・ヒストグラムが作成されるようになるので、これらの動作を抑えておくと、ヒストグラムによる効果がイメージしやすくなります。
|
12cにおいて作成されるヒストグラム |
12cで追加されたヒストグラムのうち、上位頻度ヒストグラムについては「頻度ヒストグラムを上位n件に絞ったもの」と考えれば分かりやすいのですが、一方のハイブリッド・ヒストグラムについては説明を読んでも動作がイメージできない方が多いと思います。
そこで今回は、高さ調整済ヒストグラムと比較しながらハイブリッド・ヒストグラムの動作とその効果について見ていきます。検証に使用するのは以下の表で、A列が1のデータが10件、2のデータが20件、3のデータが30件というように偏りを発生させています。
|
サンプル表の構造 |
まずはじめに、高さ調整済ヒストグラムを作成します。バケット数には個別値よりも少ない40を指定し、estimate_percentには100を指定します。ヒストグラムを作成したら、USER_TAB_COL_STATISTICSビューやUSER_TAB_HISTOGRAMSビューから情報を確認します。
|
高さ調整済ヒストグラムの作成 |
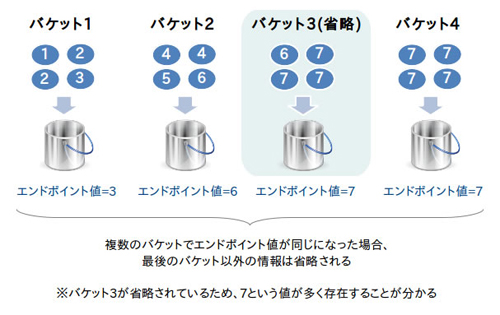
USER_TAB_HISTOGRAMSビューを確認すると、ENDPOINT_NUMBER(エンドポイント番号)列が0,1,2,3と1ずつ増えていますが、途中で20,22,23と値が飛んでいることが分かります。これは21と22のENDPOINT_VALUE(エンドポイント値)がともに37であったため、21が省略されていることを意味します。つまり、高さ調整済ヒストグラムではA列が37であるデータをポピュラー値として認識しているということです。オプティマイザによる見積り結果から、ヒストグラムの効果を確認してみましょう。
|
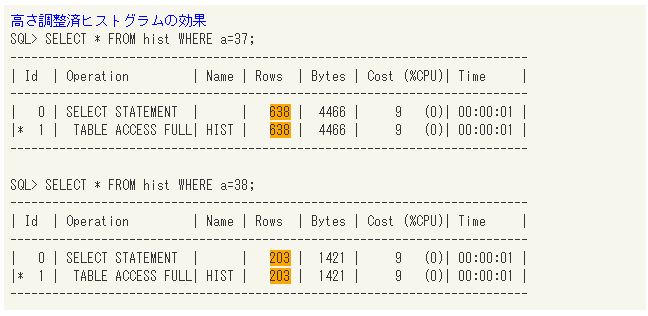
高さ調整済ヒストグラムの効果 |
A列にポピュラー値である37を指定したケースでは、実際の行数である370行に対して見積り結果が638行となっており、若干多めの数値が出ています。一方で、非ポピュラー値である38が指定されると見積り結果が203行になっており、こちらは若干少なめです。高さ調整済ヒストグラムではおおよその分布しか把握できないため、このように見積り結果にばらつきが生じてしまいます。
同じ状況において、12cのハイブリッド・ヒストグラムがどのような動作をするのか確認してみましょう。
|
ハイブリッド・ヒストグラムの作成 |
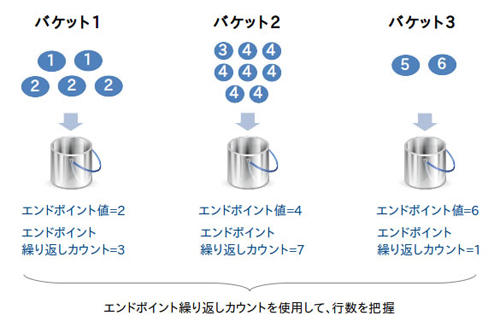
ハイブリッド・ヒストグラムでは、ENDPOINT_REPEAT_COUNT(エンドポイント繰り返しカウント)列にエンドポイント値がそのバケット内にいくつ存在するのかを記録します。先ほどの高さ調整済ヒストグラムで思うような見積り結果が出なかったエンドポイント値36や37を見てみると、ENDPOINT_REPEAT_COUNT列に実際の行数と同じ値が入っていることが分かります。オプティマイザはこれを見て行数を見積もれば良いので、正確な結果が出ます。
|
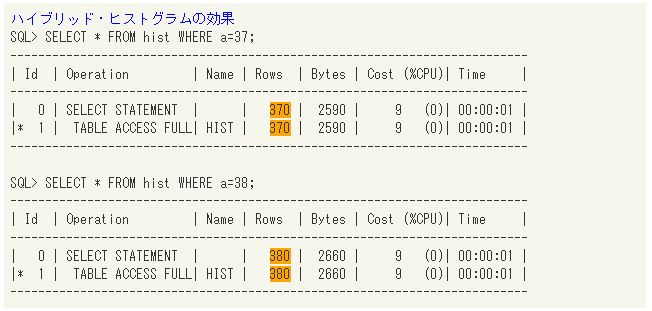
ハイブリッド・ヒストグラムの効果 |
このように、高さ調整済ヒストグラムでは見積り結果にばらつきがあった検索条件でも、ハイブリッド・ヒストグラムであれば正確な見積りができる場合があります。今回はシンプルなケースでの効果をご紹介しましたが、11gからバージョンアップを行う際には、新しいヒストグラムによる効果に是非着目してください。
次回は12cで新しく追加されたバックアップ関連の機能についてご紹介します。
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.1
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.2
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.3
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.4
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.5
・移行前に知っておきたい、Oracle Database 12c新機能のオモテとウラ Vol.7
|
|
関 俊洋
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

OCIを何から学べばよいか迷っている方に向けて、無料オンデマンド動画「OCI入門者向けウェビナー」をご紹介します。全5回の概要とおすすめの視聴ルートを通じて、OCIの基本や強み、データベース、セキュリティ、VMware移行のポイントを分かりやすくご案内します。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

