


- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
シャーディングとは、複数のサーバを使用して単一の論理データベースを構成する手法のことです。特長は、各サーバがハードウェアを共有することなく論理データベースを構成できる点にあります。そのため、必要に応じて後からサーバを追加し、ハードウェアの制限がない大規模なスケールが可能となります。シャーディングはオープンソースのデータベースで使用されるケースが多いですが、Oracle DatabaseでもOracle Database 12c Release 2(以下、12c R2)からシャーディングの機能が提供されました。Oracle Databaseのシャーディングについて機能と特長をご紹介します。
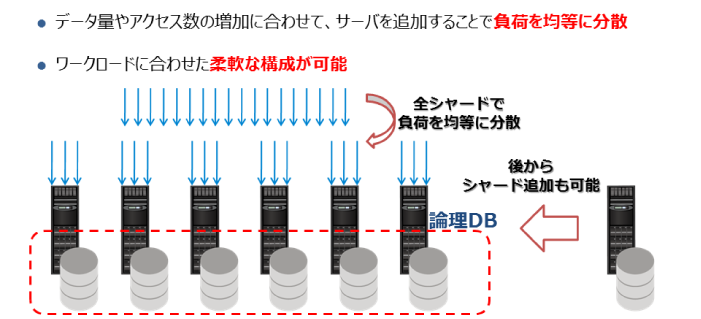
一般的にシャーディングのメリットとして挙げられるのが「スケーラビリティ」です。シャーディングを構成する各サーバには単一の物理データベース(以下、シャード)が存在します。例えば、システムをスモールスタートしてデータ量やアクセス数の増加に合わせ、後からシャードを追加することができます。また、セール期間など一時的な高負荷が予測されるようなシステムでは、シャードを一定期間だけ追加して後から削除することもできるため、柔軟な構成が可能となります。
サーバを用意してデータベースを都度作成するよりも、ボタン一つで簡単にサーバやデータベースを用意できるクラウド環境で利用するのに適したアーキテクチャと言えます。
12cの“c”はクラウドを表しており、Oracle社はクラウドと相性がいいアーキテクチャを12c R2で実装したのではないでしょうか。
|
図1:シャーディングのメリット1 |
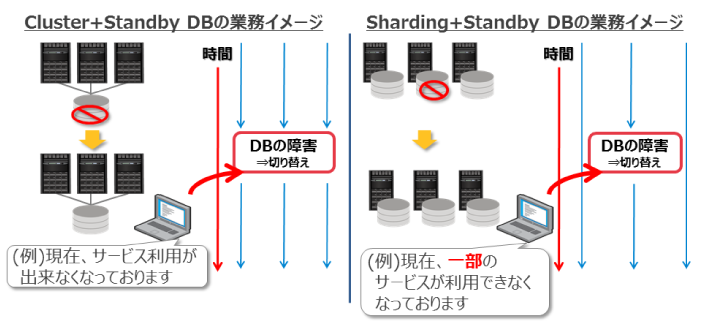
その他にシャーディングのメリットとして挙げられるのが「可用性」です。シャーディング構成の場合、それぞれのサーバは独立して存在しているため、単一のサーバに障害が発生してもその他のサーバは影響を受けることがありません。そのため、障害が発生していないサーバへアクセスする処理は継続できます。図2のように、障害範囲を極小化することで高い可用性を得ることができます。
|
図2:シャーディングのメリット2 |
では、シャーディングを利用する場合、一般的にどのような課題が考えられるでしょうか。以下にいくつか例を挙げます。
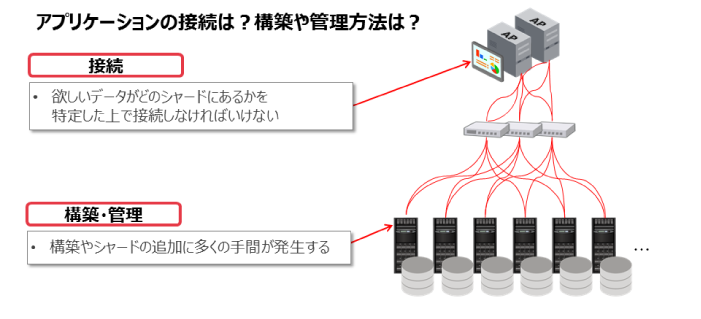
シャーディングを利用する場合はアプリケーションからの接続方法やデータの配置方法などいくつかの課題にぶつかります。
|
図3:シャーディングの課題 |
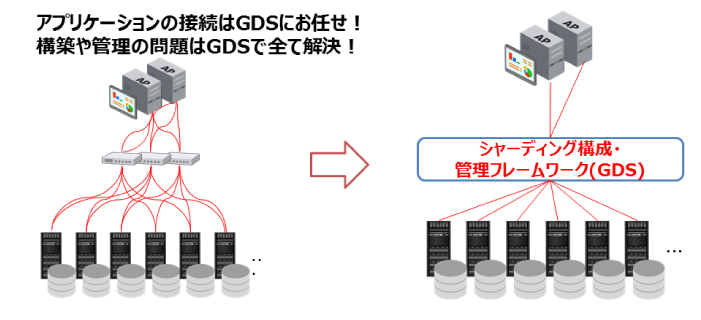
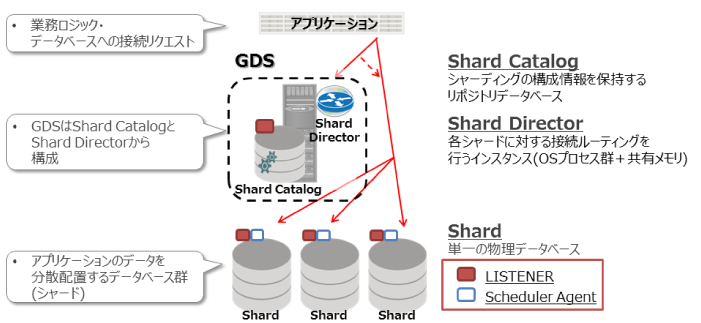
Oracle Databaseのシャーディング(以下、Oracle Sharding)には、先ほど挙げた課題を解決する独自の仕組みである「Global Data Services」(以下、GDS)が存在します。このGDSがOracle Shardingの肝となる機能です。
|
図4:Oracle Shardingの肝 |
例えば、特定のデータにアクセスしたいケースを考えてみましょう。普通であれば対象となるサーバやデータベース名などを特定しなければデータにアクセスすることができません。しかし、Oracle ShardingではGDSがどのシャードにどのデータが格納されているかを管理しているため、GDSに接続を行うと、欲しいデータが格納されているシャードにルーディングしてくれます。また、GDSの機能により自動で複数シャードを構築することも可能で、シャードの追加や削除時はデータの再配置が自動で行われます。
では、ここでOracle Shardingの構成パターンをご紹介します。データベースへの接続を行うアプリケーションとデータを格納しているシャードの間に先ほどご紹介したGDS用のサーバを構築します。
|
図5:Oracle Shardingの構成例 |
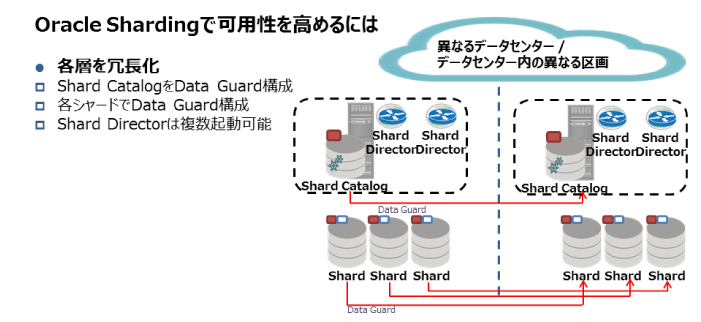
実際のシステムでは、Oracle Shardingの重要な機能であるGDSやシャードの可用性を高める必要があります。Oracle Databaseには高可用性を保証するData Guardと呼ばれる機能があり、Oracle Shardingでも利用することができます。また、接続のルーティングを担うShard DirectorがボトルネックにならないようにShard Directorを複数起動することもできます。実際のシステムで考えられるイメージが図6になります。
|
図6:Oracle Shardingで可用性を高めるには |
特にData Guardを構築する場合は複雑な手順が必要となりますが、Oracle Shardingでは1コマンドで構築することができます。実際に、筆者も検証用に図6で示している各シャードとData Guard環境を約1時間で構築できました。このように管理者の負荷が少なく非常に短時間で環境構築が行えるのも特長の一つだと思います。
ここからは、データ分散の仕組みを確認していきましょう。シャーディングでは、各サーバにかかる負荷を均等にするためにデータの分散方法が非常に重要になってきます。Oracle Shardingのデータ分散は、ハッシュとコンポジット分割に対応しています。
| 項目 | 説明 |
|---|---|
| ハッシュ分割 | ハッシュ関数を使用して、データを均一に分割する方法 |
| コンポジット分割 | 「レンジ分割※1+ハッシュ分割」または「レンジ分割+リスト分割※2」の組み合わせでデータを分割する方法 |
※1 レンジ分割はデータを期間や範囲で分割する方法
※2 リスト分割は「任意の値のリスト」を指定することでデータを分割する方法
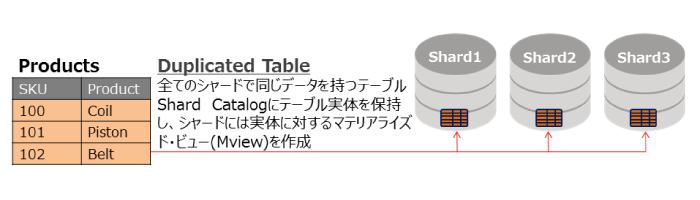
また、シャーディングで扱われるテーブルには大きく2種類あります。Duplicated TableとSharded Tableです。Duplicated Tableは全てのシャードで同じデータを持つテーブルです。Shard Catalogにテーブル実体を保持し、各シャードには実体に対するマテリアライズド・ビューが作成されます。一般的にマスターデータで使用するのがDuplicated Tableになります。図7では、「Products」表をDuplicated Tableとして表しています。
|
図7:データ分散の仕組み1 |
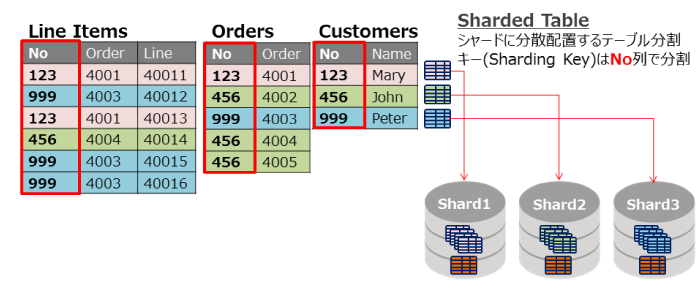
Sharded Tableは、各シャードに分散配置されるテーブルです。全てのSharded Tableは共通する分割キー列(以下、Sharding Key)を持つ必要があります。一般的にトランザクションデータで使用するのがSharded Tableになります。図8ではハッシュ分割を例に、Sharded Tableを「Line Items」表と「Orders」表、「Customers」表の3つで表しています。Sharding KeyにはNo列を指定しています。Sharding Keyを指定すると、No列の値が「123」の行データはShard1に、値が「456」の行データはShard2に、値が「999」の行データはShard3へ分散されています。
|
図8:データ分散の仕組み2 |
どのシャードにどのデータが格納されているかは先ほどご紹介したGDSが管理しているので、ユーザがデータ配置場所を把握する必要はありません。
では、分散されたデータがシャード内でどのように管理されているかを見ていきましょう。シャード追加時はシャード内にデータが格納されていないため、追加したシャードにもデータが分散されるように検討する必要があります。
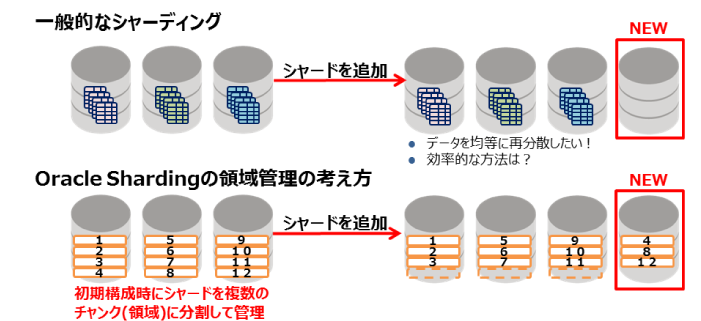
この際、Oracle Shardingで重要になってくるのが、「チャンク」という考え方です。各シャード内は、初期構築時に複数のチャンクという論理的な単位で分割され、チャンクの数は均等になるように管理されています。以降で新たにシャードを追加した際はチャンクの単位でデータの移動が行われます。特長は、シャードを追加した時に、適切なデータ再分散が自動的に行われる点です。
筆者も検証してみたところ、簡単なコマンド操作だけでシャードの追加や削除ができ、またデータの再配置も自動で行われるため、管理者の作業負荷が大きく軽減されるという印象を持ちました。
|
図9:シャード領域の管理 |
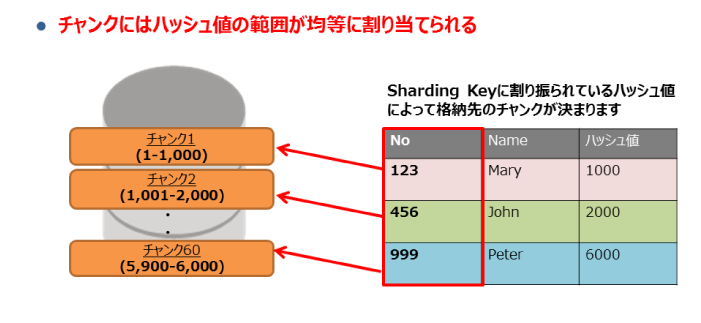
先ほどご紹介したチャンクにはSharding Keyに割り振られているハッシュ値の範囲が均等に割り当てられています。Sharding Keyのハッシュ値によってチャンクを格納しているシャードが分かるため、Sharding Keyを指定すれば必ずデータ格納先のシャードにアクセスすることができます。ちなみに、Sharding Keyとハッシュ値のマッピング情報はGDSで管理しています。その為、シャード追加時にチャンクの移動が行われる場合もGDSのマッピング情報が更新されるためアプリケーションには透過的です。
|
図10:チャンクの構造 |
ここまでご紹介したとおり、Oracle Shardingでは構築やシャード追加の作業が非常に簡単になる仕組みが備わっています。また、シャード追加後の作業負荷を軽減する仕組みになっていることから、Oracle Shardingがいかに拡張性を重視しているかを感じていただけたかと思います。
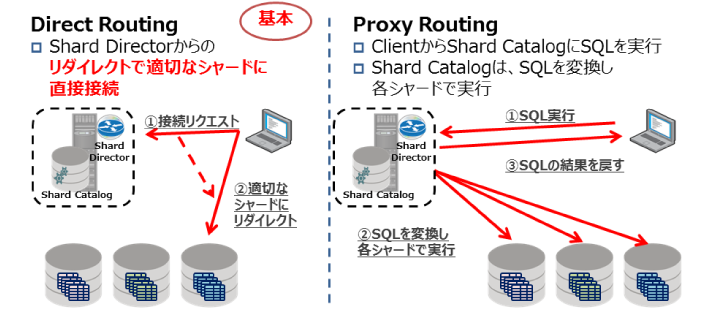
最後にシャードへの接続方法をご紹介します。シャードへの接続方法は2種類あります。Direct RoutingとProxy Routingです。
|
図11:Oracle Shardingへの接続 |
Direct Routingは、GDSからリダイレクトしたシャードでSQLを実行します。実行されるトランザクションは接続したシャード内で完結する必要がありますが、単一サーバでSQLを実行することによりパフォーマンスの向上が期待できます。また、Direct Routingはコネクションプールにも対応しています。別シャードへデータの移動が行われた場合は、GDSと連携して接続を切り替えるためのAPIも提供されており、Oracle Shardingでの基本的な接続方法になります。
Proxy Routingは、複数のシャードでSQLを分割して実行できます。クライアントからShard CatalogにSQLを実行するとSQLの変換が行われます。変換されたSQLは各シャードで実行され、その結果はShard Catalogが集計を行った後にクライアントに結果を返します。
オンライントランザクション処理は、接続の振り分けも自動で行えるDirect Routingを使用し、各シャードにあるデータを集計するような処理はProxy Routingを使用するなどの使い分けができるのも魅力の一つではないでしょうか。
ここまでご紹介した内容以外にもOracle Shardingには魅力的な機能があります。例えば、OPatchautoを使用すると、全シャード環境に一括でパッチを適用することが可能です。また、監視や管理では12c R2対応のDatabase Plug-inによって、Enterprise Manager Cloud Control からシャーディング環境の一元監視や管理が可能です。
他にも多くの機能が搭載されていますので、ぜひ皆様も12c R2ではじめられるOracle Shardingを触ってみてください。
|
|
川合 祐太
|
最後までご覧いただきありがとうございました。
本記事でご紹介した製品・サービスに関するコンテンツをご用意しています。また、この記事の他にも、IT技術情報に関する執筆記事を多数公開しておりますのでぜひご覧ください。


■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

