

- Oracle Database
- Oracle Cloud
【環境構築編】既存DBに手を加えずAI活用!OCI上にSelect AI × Sidecar環境を構築する方法
既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。
![]()






|
|
アシストの笠原です。
ExadataのSQLチューニングをトピックにしたブログも第3回となり、今回で最後となりました。
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(Smart Scan 編)
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(パラレルクエリー編)
Exadataをフル活用しよう!性能をさらに引き上げるチューニング方法(ハッシュ結合編) ★本記事★
第1回ではフルスキャンと索引スキャンの使い分け、第2回ではパラレルクエリーで更なる高速化を目指す方法をご紹介しました。最後は、表の結合方法に関わるチューニングポイントをご紹介し、実際に検証して効果を見ていきます。
Exadataでは通常のOracleよりも索引が必要なケースが少ないため(第1回参照)、表同士の結合は表もしくは索引のフルスキャン同士の結合となります。また、フルスキャンはパラレルクエリーによってアクセスするようにチューニングします。(第2回参照)
今回のトピックは、複数の表を結合する際のチューニングの考え方です。
少量データ同士の結合では、逐次処理を行うNested Loops結合が好ましいのですが、それ以外は一括処理を行うHASH結合の方がパフォーマンスが向上しやすくなります。Exadataでは、少量データ同士の結合以外は基本的にHASH結合に変更することをお奨めしています。
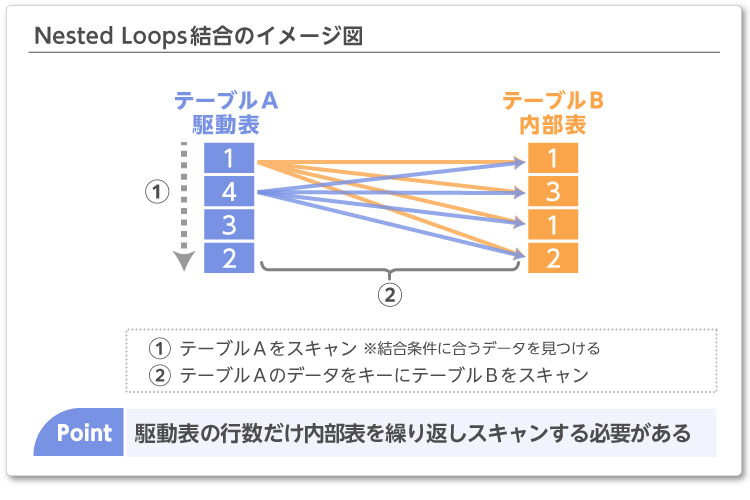
そもそも、Nested Loops結合とHASH結合はどのようなものか見ていきましょう。
Nested Loops結合は、駆動表から1行データを取り出し、条件に合うデータを内部表から検索する結合方法です。そのため、駆動表のデータが少量の場合に効果的な結合方法となります。
|
|
通常は索引を使って少量のデータを範囲検索しますが、Exadataにおいてはフルスキャンで大量データ同士の検索を行うと、内部表をスキャンする回数が膨大になってしまい、Exadataであっても性能が出ない結果となり得ます。
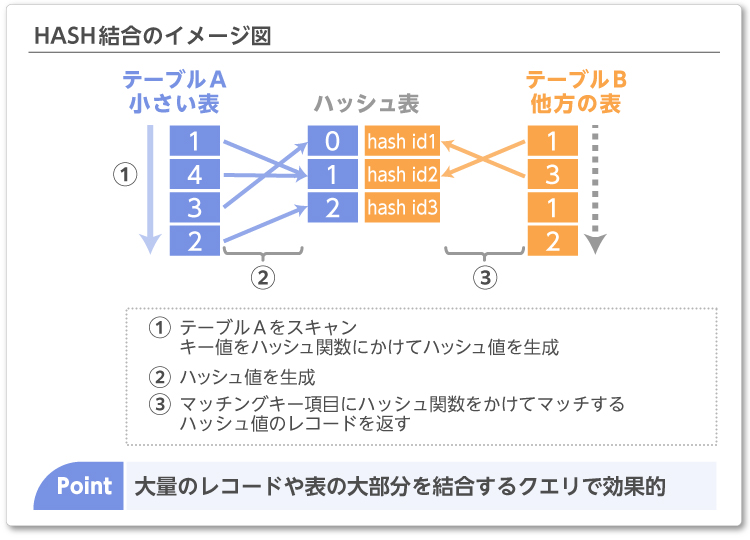
HASH結合は、駆動表を1度スキャンし、ハッシュ表を内部的に構築します。
そのあと、内部表を1度スキャンし、ハッシュ表と突き合わせる動作になります。
|
|
データ量の少ない表(上記例の左側の表)にアクセスし、WHERE条件にあうデータをハッシュ表(上記例の中央の表)をセッションのプライベートメモリ(PGA)に構築します。
内部表を1回スキャンする際、ハッシュ表とデータを突き合わせて結合しますので、全体的にディスクIOの回数を抑制することができます。
WHERE句の条件に「=」の等価条件がある必要はありますが、データ量が多い場合は、外部表と条件に合うデータがあるか毎回内部表に繰り返しアクセスするNested Loops結合よりも効率的な結合方法です。
□ NESTED LOOPS結合からHASH結合への変更を検討する
□ 2つの結合方法の違い
| 結合の種類 | 有効なシーン | 条件 |
|---|---|---|
| HASH | 結合結果が大量 | 結合条件が等価のみ使用可能 |
| NESTED LOOP | 結合結果が少量 | 大規模な表に索引が必要 |
Exadataでは表または索引の
フルスキャン同士の結合が有効
です。
少量なデータ同士の結合以外はHASH結合へ誘導しましょう。
それでは、実際に結合方法によるパフォーマンスの変化を見ていきたいと思います。
検証にあたって用意したデータは Smart Scan編と同様の構成です。約7億件(5Gバイト)、約1億5千万件(2.7Gバイト)のデータを持つ2つの表を用意しました。
TABLE_NAME NUM_ROWS TBL SIZE(GB) -------------- ------------ ------------- ORDER_ITEMS 716651816 5.38645935 ORDERES 142979000 2.77339935
これらの表を結合し、1179件のデータが合致するSQLを実行してみます。
元表に対して非常に少ない件数のデータを抽出するため、非Exadata環境を想定した場合、索引を使用したNested Loops結合が向いていると考えられます。
SQL> SELECT /*+ USE_NL(o,oi) INDEX(o,ORDER_ID_PK) */ COUNT(order_total) FROM orders o , order_items oi
WHERE o.order_id = oi.order_id and
o.order_id between 90000000 and 140000000 and
o.order_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD') and
oi.dispatch_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD');
COUNT(ORDER_TOTAL)
------------------
1179
Elapsed: 00:03:13.48 ←SQLの処理時間は処理時間 3分13秒
Execution Plan ←SQLの実行計画
----------------------------------------------------------
Plan hash value: 1563008460
--------------------------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
--------------------------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 37 | 233K (1)| 00:00:10 | | |
| 1 | SORT AGGREGATE | | 1 | 37 | | | | |
|* 2 | FILTER | | | | | | | |
| 3 | NESTED LOOPS | | 9789 | 353K| 233K (1)| 00:00:10 | | | ←Nested Loopsが選択されている
| 4 | NESTED LOOPS | | 19264 | 353K| 233K (1)| 00:00:10 | | |
| 5 | PARTITION HASH ALL | | 9632 | 206K| 185K (1)| 00:00:08 | 1 | 32 |
| 6 | TABLE ACCESS BY LOCAL INDEX ROWID BATCHED| ORDERS | 9632 | 206K| 185K (1)| 00:00:08 | 1 | 32 |
| 7 | SORT CLUSTER BY ROWID | | 9632 | | 176K (1)| 00:00:07 | | |
|* 8 | INDEX RANGE SCAN | ORDER_ID_PK | 9632 | | 176K (1)| 00:00:07 | 1 | 32 |
|* 9 | INDEX RANGE SCAN | ITEM_ORDER_IX | 2 | | 3 (0)| 00:00:01 | | |
|* 10 | TABLE ACCESS BY GLOBAL INDEX ROWID | ORDER_ITEMS | 1 | 15 | 5 (0)| 00:00:01 | ROWID | ROWID |
--------------------------------------------------------------------------------------------------------------------------------
上記の結果を比較元としましょう。続いてハッシュ結合に変更してみます。
結合方法を強制するためには、USE_HASHヒントをSQLに埋め込んで実施します。
SQL> SELECT /*+ USE_HASH(o,oi) FULL(oi)*/ COUNT(order_total) FROM orders o , order_items oi WHERE o.order_id = oi.order_id and o.order_id between 90000000 and 140000000 and o.order_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD') and oi.dispatch_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD'); COUNT(ORDER_TOTAL) ------------------ 1179 Elapsed: 00:00:27.25 ←SQLの処理時間は処理時間 27秒 Execution Plan ---------------------------------------------------------- Plan hash value: 3668956807 ------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 37 | 297K (3)| 00:00:12 | | | | 1 | SORT AGGREGATE | | 1 | 37 | | | | | |* 2 | FILTER | | | | | | | | | 3 | PARTITION HASH ALL | | 9789 | 353K| 297K (3)| 00:00:12 | 1 | 32 | |* 4 | HASH JOIN | | 9789 | 353K| 297K (3)| 00:00:12 | | | ←HASHが選択されている |* 5 | TABLE ACCESS STORAGE FULL| ORDERS | 9632 | 206K| 100K (3)| 00:00:04 | 1 | 32 | |* 6 | TABLE ACCESS STORAGE FULL| ORDER_ITEMS | 5745K| 82M| 196K (3)| 00:00:08 | 1 | 32 | -------------------------------------------------------------------------------------------------------------
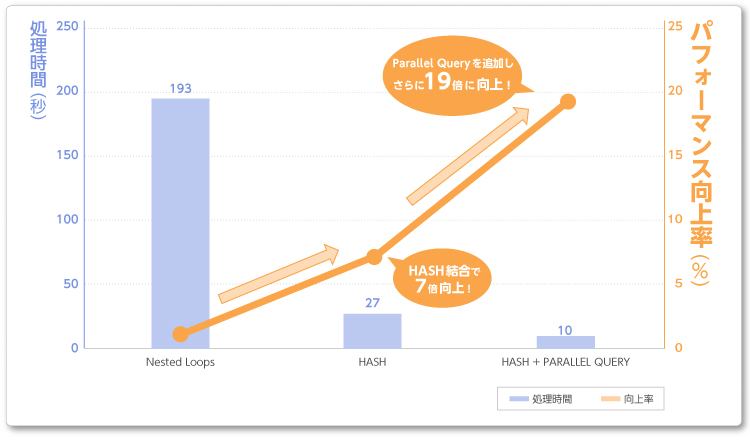
実行時間は27秒。Nested Loops結合より 7倍高速化しました!
HASH結合により大幅に高速化しました。
改めて実行計画を確認すると2つの表は全表スキャンをしていました。
------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | ------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 37 | 297K (3)| 00:00:12 | | | | 1 | SORT AGGREGATE | | 1 | 37 | | | | | |* 2 | FILTER | | | | | | | | | 3 | PARTITION HASH ALL | | 9789 | 353K| 297K (3)| 00:00:12 | 1 | 32 | |* 4 | HASH JOIN | | 9789 | 353K| 297K (3)| 00:00:12 | | | |* 5 | TABLE ACCESS STORAGE FULL| ORDERS | 9632 | 206K| 100K (3)| 00:00:04 | 1 | 32 | |* 6 | TABLE ACCESS STORAGE FULL| ORDER_ITEMS | 5745K| 82M| 196K (3)| 00:00:08 | 1 | 32 | -------------------------------------------------------------------------------------------------------------
全表走査をする場合、Exadataではパラレル機能を利用できることを第2回でご紹介しました。
ということで、更にパラレルクエリー化して改善できるか確認します。
SQL> SELECT /*+ USE_HASH(o,oi) FULL(oi) PARALLEL(4)*/ COUNT(order_total) FROM orders o , order_items oi WHERE o.order_id = oi.order_id and o.order_id between 90000000 and 140000000 and o.order_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD') and oi.dispatch_date between to_date('2012-5-01','YYYY-MM-DD') and to_date('2021-05-31','YYYY-MM-DD'); COUNT(ORDER_TOTAL) ------------------ 1179 Elapsed: 00:00:10.92 ←SQLの処理時間は処理時間 10秒 Execution Plan ---------------------------------------------------------- Plan hash value: 2847314721 ------------------------------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop | TQ |IN-OUT| PQ Distrib | ------------------------------------------------------------------------------------------------------------------------------------------------- | 0 | SELECT STATEMENT | | 1 | 37 | 82490 (3)| 00:00:04 | | | | | | | 1 | SORT AGGREGATE | | 1 | 37 | | | | | | | | |* 2 | PX COORDINATOR | | | | | | | | | | | | 3 | PX SEND QC (RANDOM) | :TQ10001 | 1 | 37 | | | | | Q1,01 | P->S | QC (RAND) | | 4 | SORT AGGREGATE | | 1 | 37 | | | | | Q1,01 | PCWP | | |* 5 | FILTER | | | | | | | | Q1,01 | PCWC | | |* 6 | HASH JOIN | | 10182 | 367K| 82490 (3)| 00:00:04 | | | Q1,01 | PCWP | | | 7 | JOIN FILTER CREATE | :BF0001 | 9632 | 206K| 27927 (3)| 00:00:02 | | | Q1,01 | PCWP | | | 8 | PART JOIN FILTER CREATE | :BF0000 | 9632 | 206K| 27927 (3)| 00:00:02 | | | Q1,01 | PCWP | | | 9 | PX RECEIVE | | 9632 | 206K| 27927 (3)| 00:00:02 | | | Q1,01 | PCWP | | | 10 | PX SEND BROADCAST | :TQ10000 | 9632 | 206K| 27927 (3)| 00:00:02 | | | Q1,00 | P->P | BROADCAST | | 11 | PX BLOCK ITERATOR | | 9632 | 206K| 27927 (3)| 00:00:02 | 1 | 32 | Q1,00 | PCWC | | |* 12 | TABLE ACCESS STORAGE FULL| ORDERS | 9632 | 206K| 27927 (3)| 00:00:02 | 1 | 32 | Q1,00 | PCWP | | | 13 | JOIN FILTER USE | :BF0001 | 19M| 282M| 54552 (3)| 00:00:03 | | | Q1,01 | PCWP | | | 14 | PX BLOCK ITERATOR ADAPTIVE | | 19M| 282M| 54552 (3)| 00:00:03 |:BF0000|:BF0000| Q1,01 | PCWC | | |* 15 | TABLE ACCESS STORAGE FULL | ORDER_ITEMS | 19M| 282M| 54552 (3)| 00:00:03 |:BF0000|:BF0000| Q1,01 | PCWP | | -------------------------------------------------------------------------------------------------------------------------------------------------
最終的に、処理時間は10秒となり、Nested Loops結合のみの時よりも約19倍高速化しました!
|
|
第3回の記事はいかがでしたでしょうか。
今回ご紹介した内容はExadata環境でのSQLチューニングの基本的な考え方となりますが効果は絶大でしたね。
最後は第1回~第3回まででご紹介した方法を全て駆使しSQLのパフォーマンスを改善することができました。
ExadataでのSQLチューニングの基本について理解が深まれば幸いです。今後も、Exadataに関連する様々な情報をお伝えしていきます。
よろしくお願いします。

|
|---|
2003年入社。10年以上Oracle Databaseの技術サポートに従事したのちフィールドエンジニア部隊に配属。Exadata X7、X8、X8M、Exadata Cloud at Customer(ExaCC)を使用した基幹システムのリプレースプロジェクトに携わる。お客様の要件にそった設計、最適化、運用支援、データ移行、DB・SQLチューニングまで幅広く対応。...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

既存DBに手を加えずに、OCI上でSelect AI × Sidecar構成を構築する方法を解説します。Oracle Autonomous AI Databaseの作成から、BaseDBとのプライベートDB Link接続、Select AIの初期設定、自然言語での実行確認までを、実際の手順に沿って紹介します。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

![[260717T]脱・PostgreSQL運用の不安!EDBのPEM管理術:GUIでの障害特定から監視まで](/db_blog/__icsFiles/afieldfile/2026/06/17/EDB_blog-bannar-260717a_176x250px_1.png)

