

- クラウドサービスとのデータ連携
HULFT Square×Dify:RESTでファイルをナレッジに自動登録してみた
本記事では、HULFT Squareが社内外のデータを収集し、DifyのナレッジベースへREST APIで自動登録して活用する手順を紹介します!
![]()






|
|
<目次>
▶システムの冗長化で検討すべきポイント
▶DataSpiderの冗長化構成
▶冗長化構成のご相談はぜひアシストへ!
ビジネスの運用のためにITシステムが欠かせない現代において、各企業では自社が提供しているサービスや自社内のシステムが継続的に稼働できるよう可用性を高めたシステム構築が大切です。そのためにシステム障害が起きた際のシステム継続の運用プロセス(=冗長化)を検討することが重要です。
システムの冗長化構成を検討する際は、各システムの連携をバックエンドで支えるデータ連携基盤の冗長化も合わせて検討すべきです。特に、基幹系周りの重要な連携では、データ連携基盤で発生した障害がシステム全体に大きな影響を及ぼします。
今回はEAIツール「DataSpider」を例にしたデータ連携基盤の冗長化における検討ポイントをご紹介します。
その前にまず、一般的にシステムの冗長化構成を検討するにあたり、どのような観点で構成を検討する必要があるのかを挙げてみます。
それぞれについて以下解説していきます。
障害発生時やメンテナンスのタイミングでのシステム停止時間がどの程度許容できるのかという要素です。24時間365日停止することが出来ない思想で冗長化構成を検討するのか、半日は停止が許容される、または、1時間以内であれば停止が許容されるといった前提でダウンタイムを検討します。
障害発生時の待機系への切り替え方についての検討です。障害の検知から待機系への切り替えを人手を利用して実施するのか、夜間など、業務時間外の障害検知を考慮し自動で待機系へ切り替えを行うのかなどを検討します。
耐障害性を意識し、本番系、待機系の2台で構成するのか、負荷分散を意識し本番系を複数台で稼働させつつ、片方のシステムに障害起きた場合にも対応できるようにするなど、複数台のシステム構成について検討します。
システムやシステム周辺の仕組みに関してどの部分までを対象システムの障害と見なし監視するのかを決定します。アプリケーション単体を対象とするのか、H/WやOS、ネットワークや関連する外部システムも含めて障害の対象とするのかなどを検討します。
|
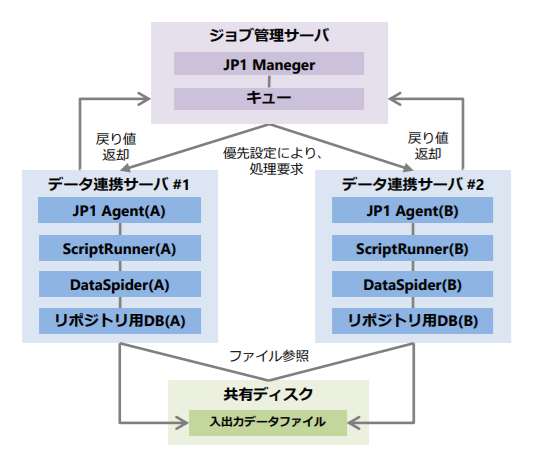
※上図は本番系2台、もう一台への切り替えとジョブの振り分けをジョブ管理製品「JP1」で実装した例 |
本番系のデータ連携サーバを2系統以上で構築することで、高いサービスレベルでDataSpiderを運用することが可能です。障害発生時やメンテナンス時において、稼働しているサーバで継続した運用(縮退運用)が可能なため、ダウンタイムが許容されないミッションクリティカルなシステム連携でお勧めの構成です。
本番系を複数台で運用することが前提のため、待機系への切り替えもなく、連携処理の負荷分散を意識した構成で運用することも可能です。
※Act-Actで構成している場合も、障害時においては実行するデータ連携サーバの切り替え、タスクの振り分け制御は必要となります。
Active-Activeの構成でサーバを構築する場合、「追加CPUライセンス」の購入が必要です。
|
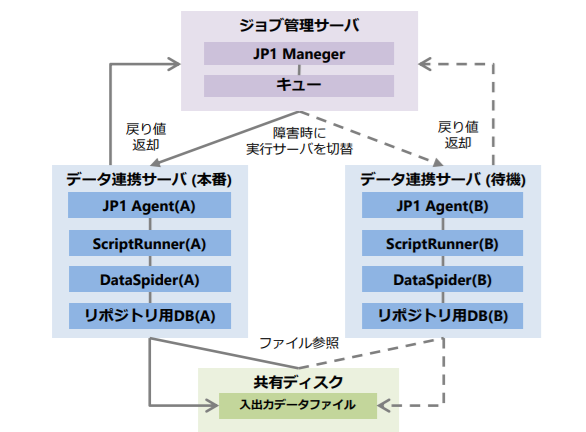
※上図は本番系と待機系で2台構成、待機系への切り替えをジョブ管理製品「JP1」で実装した例 |
待機系をコールドスタンバイ(=DataSpiderプロセスを停止した状態)で用意し、障害発生時にはJP1にて待機系のプロセス起動と切り替えを自動で行い、待機系で運用を継続させる構成です。障害発生時にダウンタイムが発生するため、Active-Activeの構成よりサービスレベルは低くなります。
しかし、DataSpiderでは待機系をコールドスタンバイで用意する場合、追加ライセンス費用が発生しないためライセンス費用を安く抑えることが出来るメリットがあります。
待機系でのダウンタイムが許容されない場合に利用される構成です。一見Active-Activeと似ていますが、Active-Activeの構成は本番系を複数台運用して負荷分散処理させることが前提のため、負荷分散を考慮しない場合、Active-HotStandbyでの検討となります。
この構成では「ホットバックアップライセンス」の追加が必要となりますが、「追加CPUライセンス」と同額であり、かつホットバックアップライセンスは待機系用のライセンスであるため本番適用できません。そのため基本的には負荷分散の考慮が可能な追加CPUライセンスの利用を推奨します。
サーバの構成はActive-ColdStandbyのとき同様、待機系への切り替えの仕組みを含めたジョブ管理製品を含む構成での検討が必要です。
DataSpiderでは障害発生時に処理のフェイルオーバーができないため、実行環境の切り替え後に、どのように処理を再実行させるかはデータ連携処理の設計段階で検討すべき事項です。
(例)
・DataSpiderのスクリプトを分割し、ジョブ管理製品から呼び出せる再実行ポイントを数か所設ける
・中間ファイルを適宜出力し、再実行時にそのファイルを利用する
また、再実行時のDBへのCRUD処理も許容すべきかどうかも合わせて検討する必要があります。
今回ご紹介したDataSpiderの冗長化構成は一例です。加えてジョブ管理系やN/W、共有ディスクの冗長化も考慮する場合、「どのような状態を障害と判断するか」をより深く検討する必要がでてくるでしょう。
アシストはDataSpiderの冗長化構成についてのノウハウを提案を通して対応してきた実績があります。構成についてお悩みがございましたら是非アシストにご相談ください。
勿論オンラインでのお打合せも可能です。どうぞ下記リンクよりお気軽にお問い合わせください!
https://www.ashisuto.co.jp/pa/contact/DataIntegration_online.html
|
|
本記事では、HULFT Squareが社内外のデータを収集し、DifyのナレッジベースへREST APIで自動登録して活用する手順を紹介します!


この記事では、SaaSとオンプレミス間のファイル転送を実現するHULFT Squareについて紹介します。


