HULFT Squareが社内外のデータを収集し、DifyのナレッジベースへREST APIで自動登録して活用する手順を紹介します。DataSpiderや各種ワークフローからも横展開しやすい、シンプルな実装パターンです。なお、実環境のAPIキーやIDは伏せた形で記載しています。
※HULFTSquareにつきましては下記をご参照ください。
記事の埋め込み
はじめに
本記事では、クラウド上のDify環境にナレッジ(Knowledge Base / Dataset)を用意し、HULFT Square(RESTコネクター)からファイルをアップロードしてドキュメント化する流れを解説します。ナレッジに格納した情報は、後段のチャットやRAGなどのアプリから参照・検索に活用でき、社内文書の自己解決や問合せ対応のスピードアップが期待できます。
Difyの概要と利用用途
ナレッジ(Dataset)機能により、PDF等のファイルをドキュメントとして取り込み、API経由での登録・更新が可能です。ベースURLは https://api.dify.ai/v1 を利用します。
想定される利用用途(本記事のパターン)
- HULFT Squareが社内外のデータを収集して(PDF等のファイルとして)夜間バッチやイベント契機でDifyのナレッジへ自動登録
- HULFT Squareで取得・生成したファイル(例:SalesforceやKintone等のクラウド上のファイル、DBの抽出データをファイル出力したもの)を入力データとして取り込み、定期/随時のナレッジ更新に活用
- 登録済みナレッジを、チャット/RAGアプリから横断検索し、社内FAQや手順説明の即時回答に活用
- 複数ファイルの一括投入による、最新ドキュメントの継続反映(差し替え運用)
全体構成と前提条件
構成イメージ
- HULFT Square(RESTコネクター)→ Dify API(/v1/datasets/{dataset_id}/document/create-by-file)
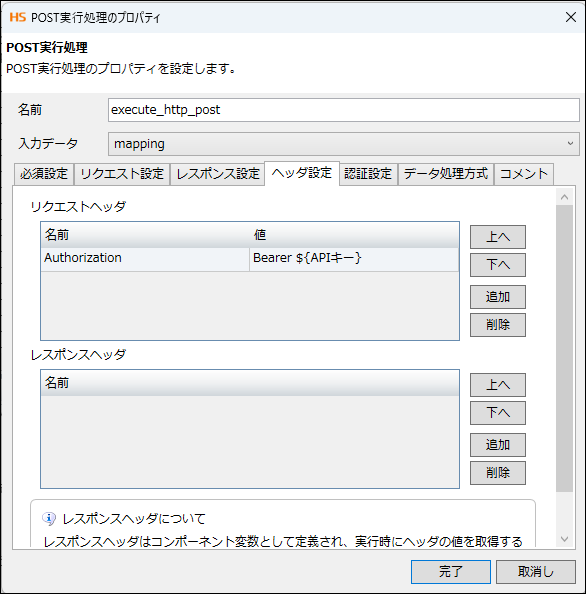
- 認証はサービスAPIキー(Authorization: Bearer ...)を使用
前提条件
- Difyクラウド環境のアカウント作成が完了していること
- 空のナレッジベース(Dataset)を作成済みで、対象のデータセットIDを控えていること(Dataset画面のURLから取得可能)
- DifyのサービスAPIキーを発行済みであること
手順1:Dify側の準備(環境・ナレッジ・API)
1. Difyにサインインし、組織/ワークスペースを作成
2. 空のナレッジベース(Dataset)を1つ作成
3. サービスAPIキーを発行し、控えておく(後続のAuthorizationヘッダに使用)
4. データセットIDをURLから取得
例)cloud.dify.ai/datasets/{DATASET_ID}/documents の {DATASET_ID} 部分
手順2:API呼び出し例(curlサンプル)
以下はローカルからの単発テスト例です。multipart/form-data でファイル本体と処理ルール(JSON)を送ります。
curl --request POST \
--url "https://api.dify.ai/v1/datasets/<DATASET_ID>/document/create-by-file" \
--header "Authorization: Bearer <API_KEY>" \
--form 'data={"indexing_technique":"economy","process_rule":{"mode":"custom","rules":{"pre_processing_rules":[],"segmentation":{"separator":"###","max_tokens":500}}}}' \
--form "file=@/path/to/your/test.pdf"
ポイント
- エンドポイント:/v1/datasets/{DATASET_ID}/document/create-by-file(Dataset単位で登録)
- Authorizationヘッダ:Bearer <API_KEY>(サービスAPIで発行)
- form-dataのdata項目:JSONで処理ルール(インデクシング手法、分割ルールなど)を指定可能
処理ルールの例(dataに渡すJSON)
{
"indexing_technique": "economy",
"process_rule": {
"mode": "custom",
"rules": {
"pre_processing_rules": [],
"segmentation": {
"separator": "###",
"max_tokens": 500
}
}
}
}
curlコマンドを実行しファイルが格納されるか確認
手順3:HULFT Squareの設定ポイント
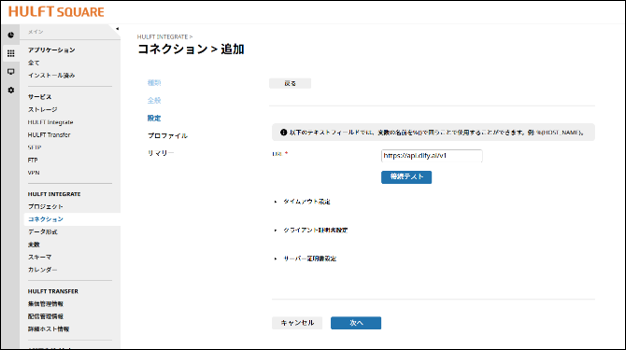
1. コネクション設定
ベースURL:https://api.dify.ai/v1
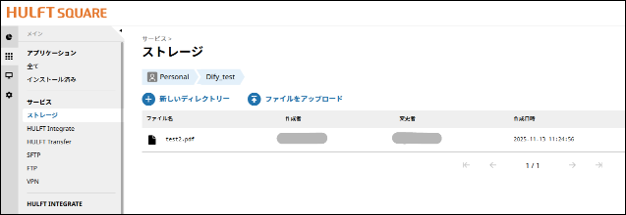
2. ストレージにファイル格納
取り込み対象のPDF等を所定のストレージ(ディレクトリ)へ配置
3. スクリプト作成(変数)
変動要素(APIキー、データセットID、ファイルパス、処理ルールJSONなど)は変数化
例:処理ルールJSONは上記の通り(separatorやmax_tokensは用途に合わせて調整
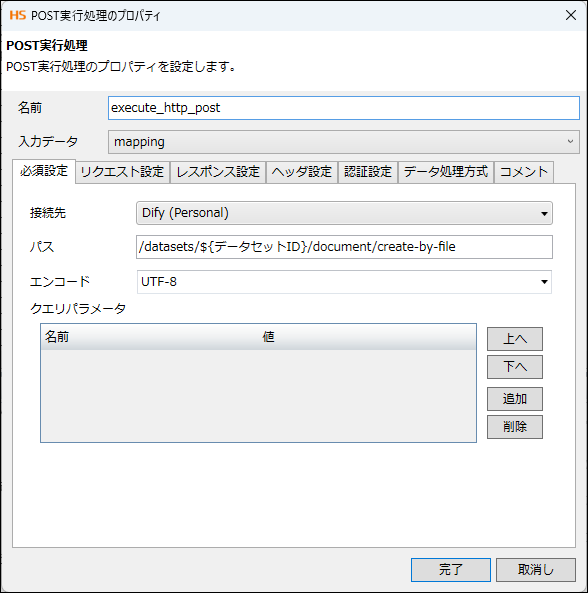
4. スクリプト作成(REST POST)
- メソッド:POST
- パス:/datasets/${DATASET_ID}/document/create-by-file
- ヘッダ:Authorization: Bearer ${API_KEY}
- Content-Type:multipart/form-data
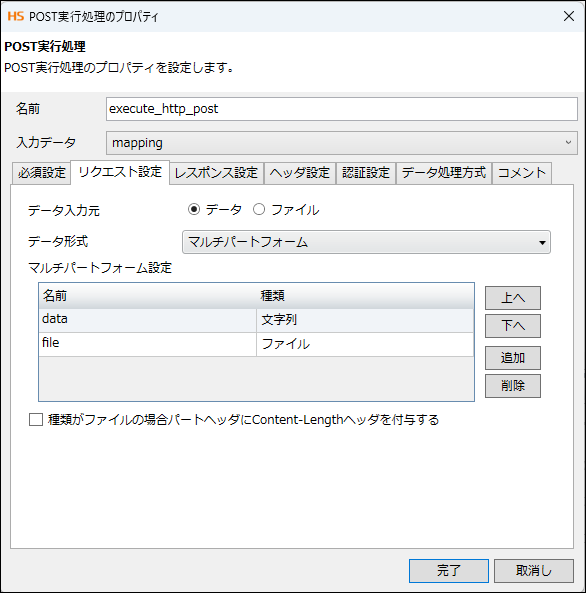
- ボディ:file(バイナリ)、data(JSON文字列)
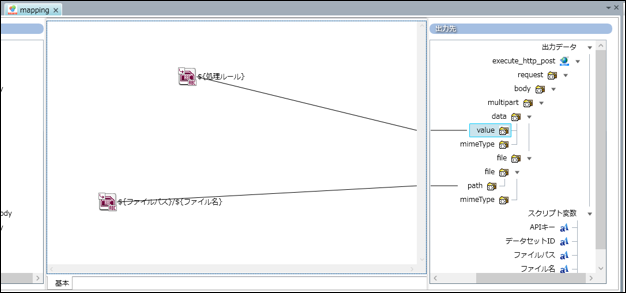
5. スクリプト作成(マッピング)
ファイルパス→fileパート、JSON文字列→dataパートへ割り当て
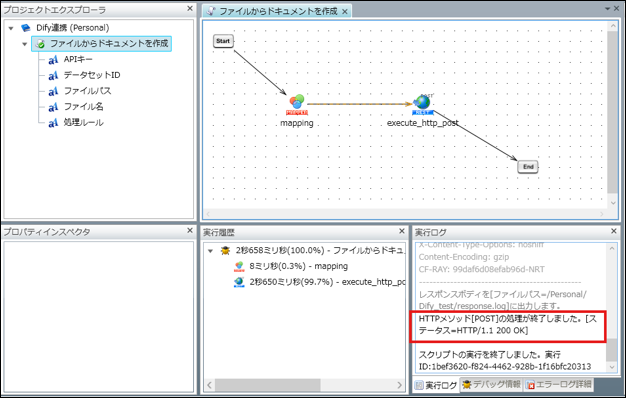
6. スクリプト作成(実行と確認)
実行し、正常終了を確認
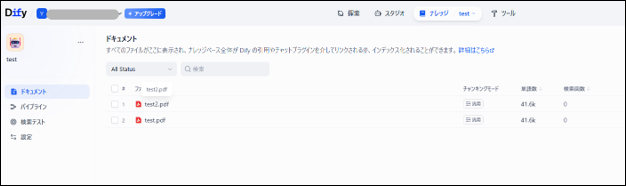
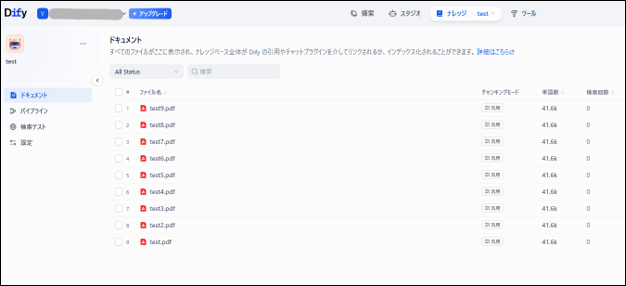
正常終了後、DifyのDataset画面で対象ファイルがドキュメントとして登録されているか確認
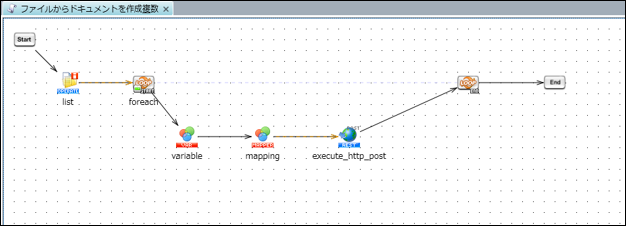
7. スクリプトを少し改造して複数ファイルを一括でDifyへ連携できるようにしてみる
8. 実行と確認
さらなる活用に向けて
- 複数ファイルの連続処理
HULFT Squareのループ処理などを組み合わせることで、ディレクトリ内の複数ファイルを一括でDifyに登録可能です。
- クラウドサービス、DBに蓄積されているデータの連携処理
HULFT SquareのコネクタによりSalesforceやKintone、各種クラウドストレージ、DBに格納されているデータ、ファイルを収集し、Difyに登録可能です。
- 取り込みルール(区切り文字、最大トークンなど)は、文書の粒度や回答精度に影響するため、数パターンを試して最適化するのがおすすめです。
- HULFT SquareのRESTコネクタでは、ナレッジベースへのファイル格納API以外にもDifyのワークフローを制御するAPIの実行も可能です。
まとめ
- Difyはクラウド版へサインイン後すぐに利用開始でき、ナレッジ(Dataset)へREST APIでファイル登録が可能です。
- HULFT Square(RESTコネクタ)からは、Authorizationヘッダとmultipart/form-dataでfile/dataを送るだけのシンプルな構成で連携できます。
- 処理ルール(分割・前処理)を調整することで、検索性・回答品質の向上が見込めます。まずは小さく始め、最適な分割粒度と投入タイミングを検証しましょう。
HULFT Squareについて、ご質問・ご相談をお受けしています。
下記URLよりお気軽にお問い合わせください。追って担当者より回答いたします。
<HULFT Squareお問い合わせフォーム>
執筆者情報:
Glean(革新的な生成AIサービス)
株式会社アシスト
Gleanは情報検索と組織内の知識共有を促進するツール。ユーザが必要な情報を迅速に見つけることができ、生産性の向上に寄与します。
2023年5月からアシストに仲間入りし、現在は「生成AI機能」も提供。
関連ブログ:
「ナレッジ共有」と「情報検索」における課題を解決!アシストの生成AI導入までの軌跡