








“スピーディなデータ準備” でデータ活用を変える「データ仮想化」の仕組みとは?
2023.5.10

|
|---|
<執筆者> 矢野 一栄 Yano Kazushige
DX推進技術本部 技術統括1部
Qlik技術部 部長
新卒で入社した製造業では工場での品質管理や市場での品質保証の業務に従事。
2002年、アシストに中途入社。
アシスト入社以来、BI、AIとデータ活用分野を中心に担当。
前回のコラム
執筆時はまだ大学4回生だった息子が、今年の4月からシステム会社に就職してプログラム研修を受講中。
口を挟みたいところを何とか我慢している。

|
|---|
<執筆者> 三村 佑 Mimura Yu
ビジネスソリューション本部
ビジネスソリューション統括部 西日本顧客支援部
2001年、アシストに新卒入社。
アシスト入社以来、BI、ETLなどのデータ活用分野を中心に担当。
2021年より、顧客支援部として、お客様の技術全般の窓口として活動。
2022年より、データ仮想化立ち上げプロジェクトに参画。
週末に4歳と1歳の娘と走り回ることで、年間5kgの減量を目指している。
クラウド時代におけるデータドリブンの課題
こんにちは。DX推進技術本部の矢野です。
「DX推進技術本部」ということもあり、お客様からDX推進に関するお悩みをよく聞きます。
DXにおいて「
データドリブン※」が注目されていますが、データドリブンの実現はまだまだ遠いとおっしゃる方が多いです。
※アシストが考える「データドリブン」とは
ビジネス活動に関わる全ての人が、データに基づき業務を推進すること
参考:コラム「データドリブンの実現に!データリテラシーを向上させる方法
」
ではなぜデータドリブンが実現できないのか、お客様訪問時の活動ログから課題を抽出してパターン化してみました。
アシストの年間約14万件の顧客接点から見えた課題
|
|
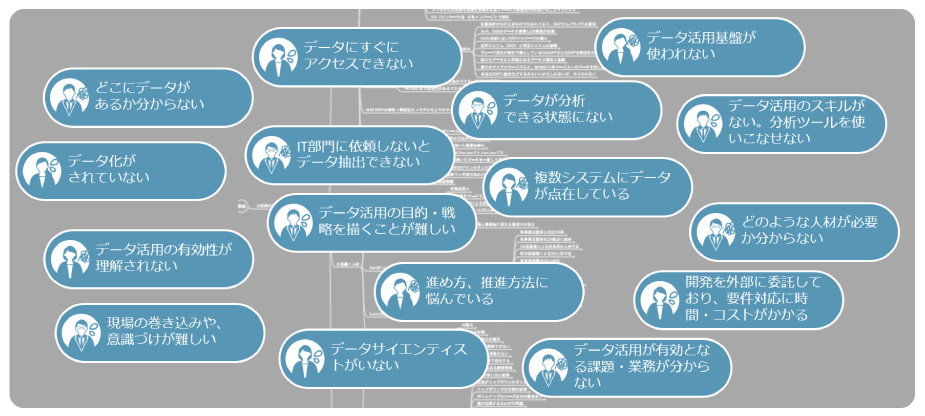
この中で「データ」に関する課題を、システム部門とユーザー部門の視点で整理してみましょう。
システム部門(データを提供する側)の視点
・対象システムが増加、データがサイロ化している
※システム(データ)の種類、データの量が増加しているため
・データ統合に時間がかかる
※ウォーターフォール型での開発のため
ユーザー部門(データを利用する側)の視点
・利用したいデータの所在と取得方法が分からない
・欲しいデータをリアルタイムに取得できない
・システム部門を介してデータを収集するため時間がかかる
DX推進も相まって、ユーザー部門は迅速で柔軟なデータ活用を求めています。
その一方で、システム部門は散在するデータの統合に時間とコストを要するというジレンマが生じています。
このジレンマを解決する一つの手法が「
データ仮想化
」です。
そこで本日は、データ仮想化の基礎やユースケースなどの情報をお届けしたいと思います。
データ仮想化とは ~物理統合と仮想統合の違い~
データ仮想化とは何か、物理統合と比較して見てみましょう。
データの物理統合と仮想統合
|
データを物理的にコピーや統合(データ加工と蓄積)することで |
データを物理的にコピーや統合(データ加工と蓄積)することなく |
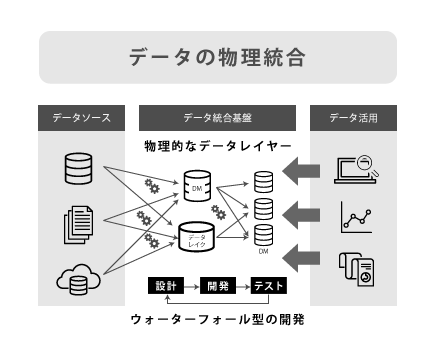
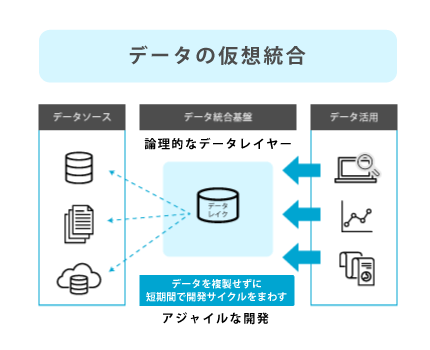
このように、データ仮想化は「物理的にデータを複製しない」ため、以下のようなメリットがあります。
・データを複製しないため、リアルタイムなデータを提供できる
・データを仮想的につなぐため、開発工数を抑えてアジャイル的なアプローチができる
そのため、ユーザー部門が求める「迅速で柔軟なデータ活用」と、システム部門が求める「時間とコストを抑えたデータ統合」の両方を満たすことができるでしょう。
アシストのデータ仮想化への対応
アシストでは、データ活用基盤の構築として
「つなぐ」「ためる」「とどける」「いかす」
という4つの視点で提供するソフトウェアを「
aebis(エビス)
」と総称してご紹介しています。
すべてのソフトウェアが必要というわけではなく、目的や課題にあったソフトウェアを適材適所に組み合わせてご提案しています。
アシストが提案するデータ活用基盤「aebis(エビス)」
|
|
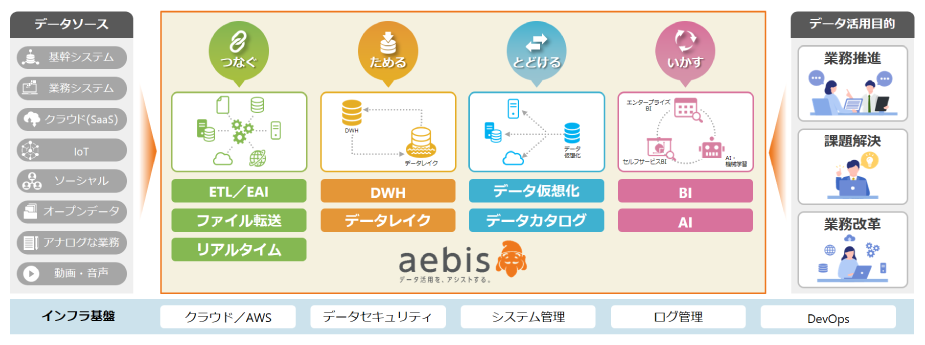
✓ つなぐ(ETL)、ためる(DWH)…… データの物理統合
✓ とどける …… データの仮想統合
データ活用のスピードアップが叫ばれる中、アジャイル的な開発でスピーディにデータを提供できる「データ仮想化」は重要だと考えています。
そこで、元々は「つなぐ」「ためる」「いかす」の3つの分野に注力していましたが、新たに「
とどける
」分野を追加しました。
「とどける」分野のソフトウェアとして、2022年5月より「
TIBCO Data Virtualization
」の取り扱いを開始しています。
データカタログ機能を搭載し、ガバナンスとセキュリティを担保しながら、迅速なデータ提供ができる製品です。
「数年前に話を聞いた時は、データ仮想化なんて言ってなかったのに……」という方は、ぜひ改めて情報提供させてください。
ちなみに、「いかす」分野に関しては、私が担当するBIツール「
Qlik
」があります。
Qlikでは「つなぐ」「ためる」「とどける」部分なしでもデータ活用が可能です。
DWHなしでクラウドを含む各業務データに接続し、アジャイル的なデータ分析/データ活用を実現します。
担当製品なのでもっとアピールしたいところですが、これ以上書くとデータ仮想化の話から外れて売り込み色が強くなってしまいますので、この辺りで止めておきます(笑)。
データ仮想化のユースケース
こんにちは。ビジネスソリューション本部の三村です。
私からは、「データ仮想化」立ち上げプロジェクトや、お客様とのアポを通じて学んだことをお伝えしたいと思います。
まずは、データ仮想化の代表的なユースケース「データレイク/DWH」についてご紹介します。
前述の『データ仮想化とは ~物理統合と仮想統合の違い~』では、「データレイク/DWHの代わりにデータ仮想化」というイメージでお伝えしていましたが、実際には「既にデータレイク/DWHがある」お客様が多いです。
そこで、既存のデータレイク/DWHを活用したデータ仮想化について考えてみましょう。
データレイク/DWHを使って「データの物理統合」をする場合は、以下の流れが一般的とされています。
① システム部門が、DWHにテーブルを作成する
② システム部門が、ETLツールでDWHにデータを集める仕組みをつくる
③ システム部門が、ETLツールを実行するジョブを作成し、定期実行させる
④ ユーザー部門が、BIツールなどでDWHのデータを活用する
しかし、せっかく工数をかけて公開しても、以下のような「よくある課題」が原因で活用されないケースが多いです。
「データの物理統合」におけるよくある課題
|
|
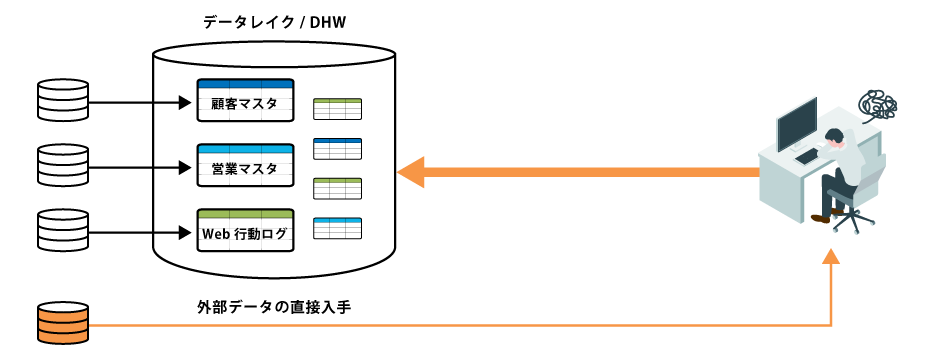
データの追加が大変
ユーザー部門から要望を出しても、データを1つ追加するだけで数ヵ月かかる
システム部門の中でも、スキルがある担当者に依頼が集中してしまう
データを探すのが大変
ユーザー部門ではどこにデータがあるか分からず、探し出すのに時間がかかる
ITガバナンスを効かせるのが大変
ユーザー部門が独自にデータを調達してしまう
誰かが作成したデータを使いまわしてしまう
そこで、データ仮想化の出番です。
「データ仮想化」では、あらゆるデータを複製することなく、仮想的につなげて公開します。
ユーザー部門からデータ追加要望があった場合を考えてみましょう。
物理統合で必要な以下の手順を短縮し、必要なデータをとどけるまでの時間を大幅に短縮できます。
① システム部門が、DWHにテーブルを作成する
② システム部門が、ETLツールでDWHにデータを集める仕組みをつくる
→ データ仮想化ツールに仮想ビューを作成するだけ
③ システム部門が、ETLツールを実行するジョブを作成し、定期実行させる
→ データを複製する必要がないため、不要
さらに、データ仮想化ツールの機能である「データカタログ」や「データアクセスの一元管理」を活用すれば、よりユーザー部門が使いやすいシステムになります。
「データ仮想化」による課題解決
|
|
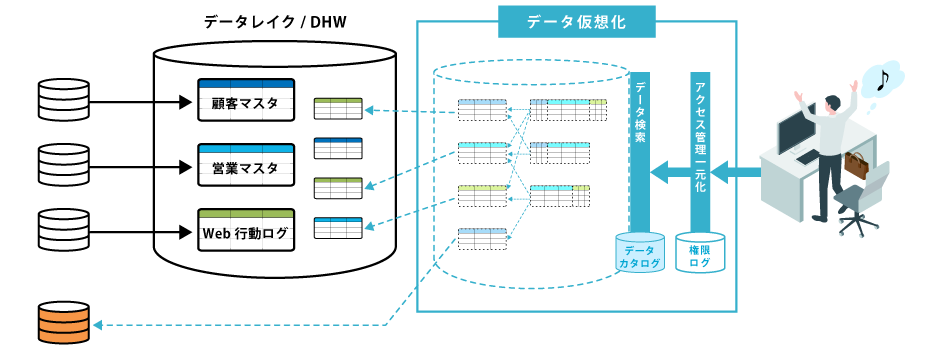
データの追加が簡単
数週間かけてETLジョブを開発するのではなく、数時間でビューをGUI開発できる
データを探すのが簡単
データカタログを使うことで、エクスプローラーのようにフォルダ検索したり、Googleのように項目検索ができる
ITガバナンスを効かせるのが簡単
データアクセスを一元管理・公式化することで、必要なユーザーに必要なデータを簡単に共有できる
セル(行×列)レベルでのアクセス制御や、利用ログの取得も可能
ユーザー部門からデータ追加要望があったとしても、一度きりの利用かもしれません。
そんな要望には、データ仮想化のアジャイル的なアプローチが効果的です。
他にも、データ仮想化は以下のようなケースで活用できます。
・データレイク/DWHに貯めていない基幹業務システムのデータを統合する
→ 既存のDWHに統合せずに仮想統合することで、短期間でデータ公開ができる
・物理統合を行う前のプロトタイピング基盤として利用する
→ 利用頻度や重要度の高いデータを精査した上で、物理統合するデータを決定できる
・ライブデータ混合の参照基盤として利用する
→ 履歴データもライブデータも、データ仮想化ツールを通して提供することで、
ユーザーのニーズに合わせた鮮度でデータを提供できる
・ユーザーによってデータを制御して公開する
→ ポリシーに準拠した認可設定を一括管理することで、効率的な運用ができる
データ仮想化について様々なユースケースをお伝えしましたが、データ仮想化はあくまでも「一時的に仮想データを見せる」手法です。
「永続的にデータを貯めていく必要がある」と明確になれば、従来の物理統合でデータレイク/DWHにデータを貯めるようにしましょう。
さいごに
私は、データ仮想化ツール「TIBCO Data Virtualization」のプリセールスを担当しています。
プリセールスをしている中で感じることは、「データ活用のスピードアップ」を求めるお客様がとても多いということです。
この流れは今後も加速していくと思われる中、「データ仮想化」はまさに発想の転換で、多くのお客様から共感を得ています。
一般的なデータ仮想化のメリットはもちろん、
・不用意なデータの複製がなくなるので、不要なデータを保持しなくて良い
・物理統合に伴う既存バッチを減らせる
・データ仮想化ツールを「データ活用の玄関」とすることで、アクセス制御などの統制をかけやすい
という点も評価いただいているポイントです。
変わり続ける情勢の中で、データ活用に必要な要件も日々変わってきています。
本コラムで「データドリブンを加速させるために、データ仮想化が一つの武器になる」というメッセージを多くの方に「とどける」ことができたら幸いです。
本ページの内容やアシスト西日本について何かございましたら、お気軽にお問い合わせください。
