








データベースのアシスト
Database OneDay Seminar 開催報告
~リレーショナル・データベースの進化を見逃すな!~
去る11月7日、アシストでは「リレーショナル・データベースの進化を見逃すな!」と題し「データベースのアシスト:Database One Day Seminar 」を開催しました。特別講演として、東京大学生産技術研究所の喜連川優先生にご登壇いただき「データベースに携わることは人類に貢献するということ ~ ビッグデータとデータベース ~」 をテーマにご講演を賜りました。
喜連川先生は国立情報学研究所の所長を務め、東京大学教授でもあります。6月からは情報処理学会会長も務め、国家レベルのプロジェクトにも数多く参画されています。「ビッグデータ」という言葉が一般的になる以前から「情報爆発」という言葉を使い、日本のビッグデータに関する取り組みを牽引されてきたデータベースの第一人者です。喜連川先生が所長を務める国立情報学研究所(以下、NII)は日本唯一の情報学の学術総合研究所としてITに関する研究を行っています。このNIIが構築、運用する学術情報通信ネットワークであるSINET4は日本で最も大きなアカデミックネットワークの運用母体であり、ノーベル賞を受賞した小林/益川理論の実証実験や地震/天文学の膨大な観測データの転送など、最先端の学術研究を支える情報インフラとして国内外で活用されています。膨大なデータをサイエンスが直接扱う時代になったと喜連川先生。ビッグデータは科学の世界ではもはや当たり前の時代なのです。
|
|

講師プロフィール
国立情報学研究所 所長
東京大学 生産技術研究所 教授/工学博士 喜連川 優 氏
1983年東京大学工学系研究科情報工学専攻博士課程修了、工学博士。
東京大学生産技術研究所教授、東京大学地球観測データ統融合連携研究機構長、2013年4月より国立情報学研究所所長、2013年6月より情報処理学会会長を務める。データベース工学の研究に従事。内閣府最先端研究開発支援プログラムの中心研究者として推進中。情報処理学会功績賞、ACM SIGMOD E.F. Codd Innovations Award受賞。ACM、IEEE、電子情報通信学会ならびに情報処理学会フェロー。
データベースは契約社会を支える上で不可欠なソフトウェア
ソフトウェアには「あれば嬉しいソフトウェア」と「買わざるを得ないソフトウェア」の2種類があり、巷にあるほとんどのソフトウェアが前者に相当します。一方「買わざるを得ない、必要不可欠なソフトウェア」の1つがデータベース・ソフトウェアです。データベースを使っていない企業はまずありません。例えば、商品購入の契約成立を実現しているものは何かというと、100%データベースで、データベースを管理するソフトウェアがなかったら今の経済あるいは契約社会は成り立たないわけです。経済の根幹とも言うべきこうしたデータベースのソフトウェアに携わっている方は人類の活動そのものを支えていると言えるでしょう。
コンピュータの世界には色々な技術がありますが、データベースほど美しい技術はないですし、これほど世の中に役立つ技術はありません。無限とも言える莫大な量のデータの中から、高度なインデックス処理で必要なデータを取り出すサーチはデータベースが実現しています。またコンピュータ・サイエンスの中で、何が起こっても元の状態に戻せる技術は、データベース以外にありません。「永続性」と「回復可能性」を実現可能なのはトランザクションと呼ばれるデータベース技術だけなのです。
超巨大ビッグデータ時代到来⇒ビッグデータのご利益とは
ビッグデータという言葉があちこちで聞かれる時代となりました。ビッグデータは、新しいナチュラル・リソースと定義できます。このビッグデータのご利益についてカーナビを例にお話ししましょう。これまでのカーナビは渋滞情報を単に知らせるものでした。例えば、第1世代のカーナビは地図上の最短経路だけを表示していたのに対し、続く第2世代のカーナビはダイナミックに変わる渋滞状況を逐次表示するクラウドの地図へとシフトしていきました。ところが「今A地点で渋滞が起こっている、それでもそのA地点の渋滞に向かって進め!」というのが第3世代のいわゆるビッグデータ時代のカーナビなのです。これは一体どういうことでしょう。
車に搭載されたGPSの情報やつぶやき情報など、バラエティ豊かで膨大なデータを活用します。つぶやき情報など意味がないと思いがちですが、渋滞に巻き込まれた時こそ、人は苦情を書き込むので貴重な情報源になるのです。例えばカリフォルニアはトラックの横転事故が多いのですが、トラックが搭載しているものによって復旧状況が全く異なります。搭載されていたものがトマトやブロッコリーなどの場合と比べると、LPGなどオイルであればなかなか復旧しません。そうした情報をつぶやき情報などから抽出し、過去のログ情報と合わせて、大体何時間で復旧するかの予測ができる。こんなことができるのがビッグデータ時代です。 たとえ「今A地点が混んでいても、渋滞は1時間半で解消される」とわかれば、そこに着くまでには充分時間があるという場合には、むしろ渋滞に向かって進む方が、賢明なソリューションとなるわけです。
ビッグデータに支えられるサイエンス
サイエンスの世界ではビッグデータを扱うのが当たり前で、「eサイエンス」、いわゆる「データ・セントリック・サイエンス」という言い方をしていますが、あらゆるデータ、例えば、天文等の観測データや、コンピュータのシミュレーション結果、論文などの情報を目の前に置いて、科学者たちが研究するスタイルになっています。皆さんがイメージしているような、実験設備の前で研究をしている人は相対的に少なくなっています。もちろんすべてのサイエンスが当てはまるわけではありませんが、データにシフトしていることは確実で、データ基盤を早くしっかりと築くことが科学的発見への近道になっていると言えるのではないでしょうか。
ビッグデータの最も大きな研究対象は、不確定要素の大きい「自然現象」です。2011年のタイの洪水や3月11日の東日本大震災について、研究者達が膨大な観測データから洪水や津波のメカニズムを洞察できるようになりつつあります。熱帯化する気候変動の激しさが増す中で、ダムの動的制御の研究を進めてきて、かなり実用レベルに達しつつあります。
このように我々は、地球環境の観測において、温暖化、水資源、農業、生物多様性など多岐にわたり多くのデータを基に様々な解析を行っています。サイロ的に蓄積された膨大なデータを統合し解析することで、多様な社会価値を生み出すことのできる時代になっているのです。
|
図1 地球環境情報爆発 |
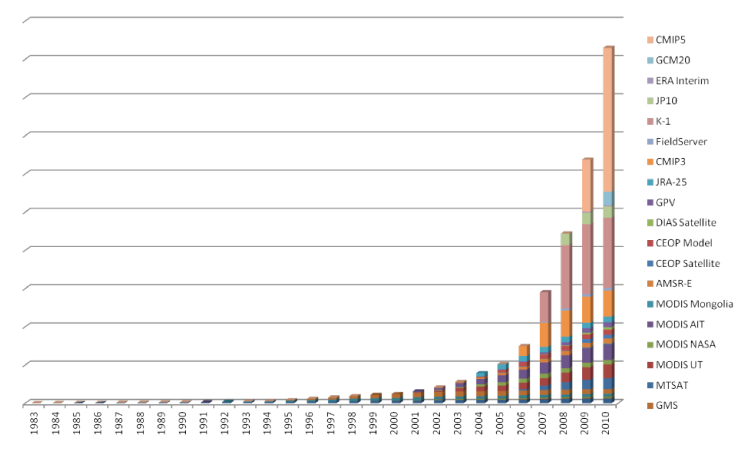
80年代初頭からデータの爆発が起こり、莫大な観測データを格納するストレージは20ペタを超えます。こうした20ペタものストレージを東京大学では運用していますが、大学の1つの研究室で運用しているというのは他に類がないのではないでしょうか。企業でもかなり大きな方になると思います。
爆発的に増加するビッグデータを活用するために
ビッグデータとは言え、ビッグになった分だけ活用に時間がかかるのではお話になりません。まだビッグデータという言葉がなかった2009年に応募し、我々東京大学は政府から総額40億円という予算をいただき最先端研究開発支援プログラム『超巨大データベース時代に向けた最高速データベース・エンジンの開発と当該エンジンを核とする戦略的社会サービスの実証・評価』の研究への取り組みを開始しました。データ解析系処理を高速化し、従来のシステムでは困難であった超巨大データに対する高速な解析処理の実現を目指しています。
|
図2 情報エネルギー生成基盤 |
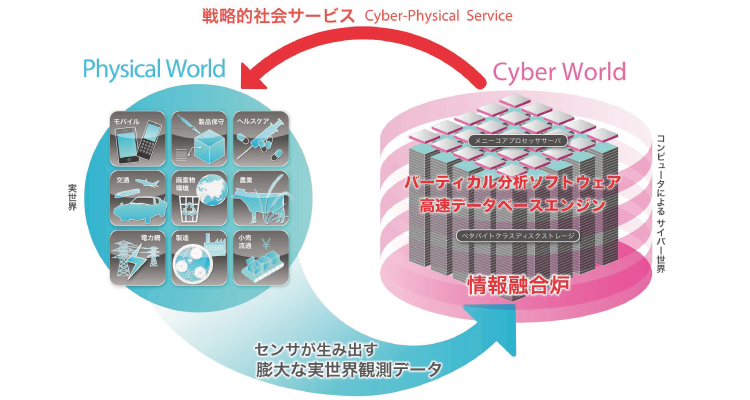
10年以内には、IT領域だけでなく、農業、医療、各種インフラ、交通、製造、流通、地球環境に至るまで、センサー・ネットワークを活用した膨大な実世界観測データが蓄積できるようになるでしょう。そして多くの産業分野で、データの超精細な観測が可能になり、クラウド上からリアルタイムにフィードバックされるという構造に変わってくるでしょう。このクラウドで一番重要となるのが、ビッグデータのための超高速なデータベースとそれを分析するためのバーティカルな解析エンジンです。
1,000倍高速になったら世界は変わる!ビッグデータを超高速に処理したい
この超高速データベース・エンジン開発のプロジェクトに参加いただいた日立製作所には「日立のHiRDBに比べて1,000倍速くしましょう」と提案しました。10倍、100倍では誰も驚きません。データの単位が変わる1,000倍を目指そうと考えたわけです。つまりメガバイトからギガバイト、ギガバイトからテラバイト、テラバイトからペタバイトといった具合です。データ量が1,000倍。しかし、処理時間も1,000倍では意味がないし、誰も使わない。逆に1,000倍速くすることで、今と同じスピードで1,000倍多くのデータ量を扱えるようにしようと考えました。つまり、これがビッグデータ時代のソリューションと考えたわけです。
|
図3 従来型と非順序型データベース・エンジン |
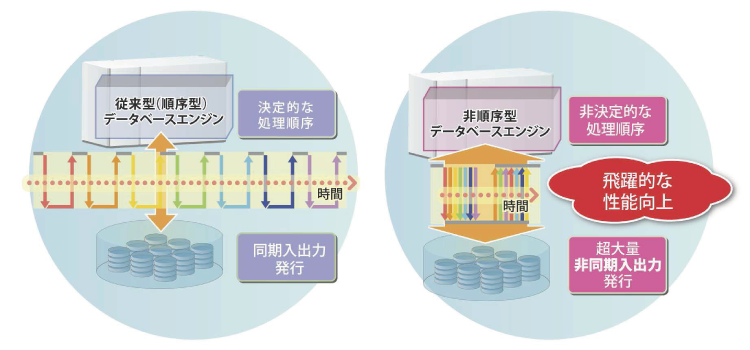
最適化されない選択率が中程度のデータベース利用領域を劇的に速くしようというのが我々の研究で、「非順序型実行原理」という新しいIT理論に基づき、非順序型(Out of Order Execution)データベース・エンジン(以下、OoODE)と称する高速データベース・エンジンの開発を進めています。OoODE の場合、問い合わせ処理をタスク分散する機能を有し、高多重のタスク並行実行と高多重の非同期入出力発行を行うことにより、従来の逐次的な実行方式による順序型(In Order Execution)データベース・エンジンと比較し、性能の飛躍的な向上を実現します。ハードウェア、メモリ、ディスクなど一切変えることなく、ソフトウェアだけ変えることによって、それが可能となります。
今後ますます加速度的に増大していくことが予想されるビッグデータ。巨大なデータを解析して社会へサービスを提供するためには超高速データベース・エンジンが必要不可欠です。こうしたビッグデータ時代において、データベースのソフトウェアが主役になるのは間違いありません。データベースに携わる者同士、これからも共に人類に貢献できる活動を続けて参りましょう。
※本Webページに掲載の本文ならびに図版は東京大学様に帰属するものです。図版等について、無断での引用、転載等を堅く禁じます。




