

- Oracle Cloud
- Oracle Database
Oracle AI World Tour Tokyo 2026に今年も出展しました!
今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。
![]()






|
|
昨今、長期保管が必要なデータが加速度的に増大しているかと思います。その背景には、「コンプライアンス対応」や「AIを使ったデータ分析」など、様々な理由が考えられます。
本記事では、そういった長期保管が必要なデータがデータベースに蓄積されていくことにより、通常業務の性能に影響が出てきているという課題をお持ちの方に、現場エンジニアがOracle Partitioningのメリットや効果をご紹介します。後半では、パーティショニングにより大幅にレスポンスが改善されたお客様事例をご紹介します。
Index
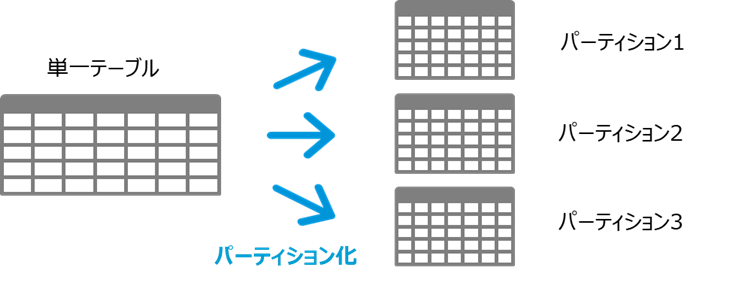
Oracle PartitioningはOracle8から登場した機能で、一つの表や索引を複数に分割して管理する機能です。
Oracle Database Enterprise Edition(以下、EE)の有償オプションで、アプリケーションからはパーティションを意識することなく、単一のテーブルとして扱うことができます。
|
|
パーティショニングには大きく三つの特徴があります。
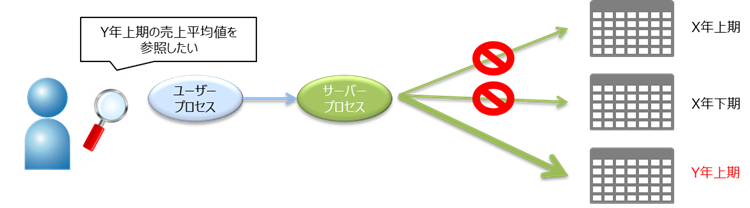
対象データが格納されているパーティションだけにアクセスし、ディスクI/O量を最小限に抑えることができます。これをパーティション・プルーニングと呼びます。このパーティション・プルーニングにより、パフォーマンスの向上に繋げることができます。
|
|
テーブルがパーティションごとに分割されるため、他のパーティションテーブルに影響を与えずにパーティションテーブルの追加が可能です。また、一部のパーティションテーブルだけをバックアップしたり、追加されたパーティションのみ統計情報を取得することも可能です。
|
|
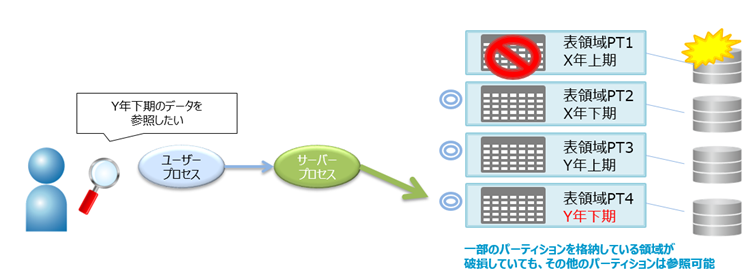
パーティションごとに表領域を分割することができるため、特定の表領域に障害が発生した場合も残りのパーティションは参照が可能です。
|
|
Oracle Partitioningには大きく三つの種類があります。
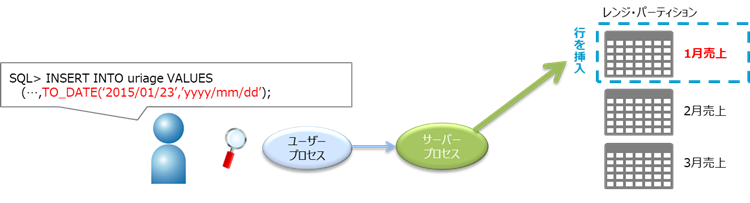
時系列(期間)や値の順序などを基準に格納するパーティションを決定する方法です。
例えば、月単位でデータを分割したい場合に利用します。
パーティショニング・キーの選定は、まずこのレンジでデータを分割できないかを検討することが多いです。
※パーティショニング・キー
テーブルデータをパーティションに分割するために使用される特定の列のことです。
|
|
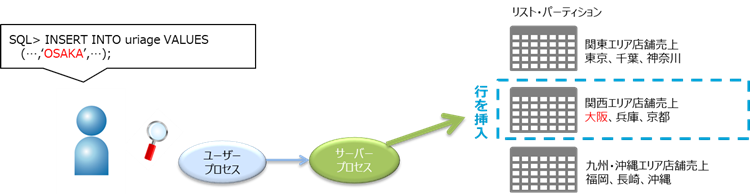
リストした値を基準に格納するパーティションを決定する方法です。
関東、関西、九州のように地域別にデータを分割したい場合に利用します。
|
|
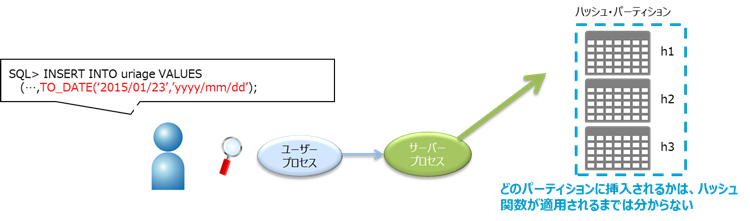
ハッシュ値を使って格納するパーティションを決定する方法です。
レンジやリストで分割できない場合や、各パーティションのデータ量を均一にしてI/Oを
分散させたい場合などに利用します。
|
|
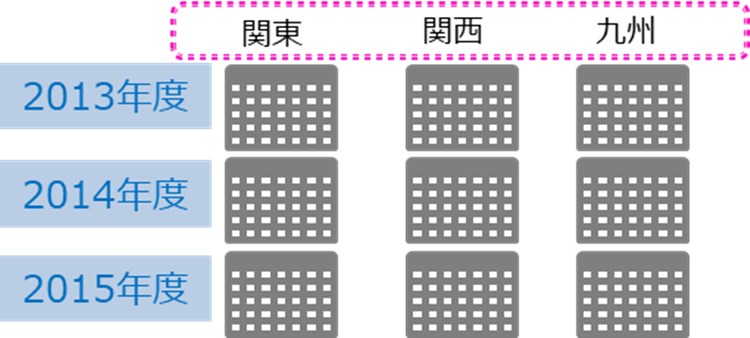
また、レンジ、リスト、ハッシュを組み合わせた、コンポジット・パーティション(複合パーティション)を定義することも可能です。
例えば、年ごとにデータを分割し、そこから関東、関西、九州と地域別にデータを細分化したい場合や、単一パーティションだけではパーテーション・プルーニングの効果が低いときに複数のパーティション・キーを組み合わせて利用する場合があります。
|
|
<参考>
Oracle Databaseのバージョンにより、コンポジット・パーティションで利用できる組み合わせには制限があります。
【Oracle Databaseのバージョンにより選択可能なパーティション構成】
| サブ | ||||
| レンジ | リスト | ハッシュ | ||
| メイン | レンジ | 11g | 9i | 8i |
| リスト | 11g | 11g | 11g | |
| ハッシュ | 12c | 12c | 12c | |
非パーティションテーブルとパーティションテーブルを作成し、約7億件のデータに対する処理時間を比較してみたいと思います。
パーティションテーブルは「レンジ・パーティション」で作成します。
TABLE_NAME NUM_ROWS TBL_SIZE(GB) ------------------------------ ---------- ------------ ORDER_ITEMS_NORMAL 716664493 51.6315384
7億件のデータ(6ヶ月分)から1ヶ月分のデータを範囲検索し、問い合わせ時間を確認します。
SQL> select count(return_date) from order_items
2 where dispatch_date between to_date('2012/01/01','yyyy/mm/dd') and to_date('2012/01/31','yyyy/mm/dd');
COUNT(RETURN_DATE)
------------------
3544139
経過: 00:00:44.25
実行計画
----------------------------------------------------------
Plan hash value: 2381286344
-----------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time |
-----------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 1766K (1)| 00:01:09 |
| 1 | SORT AGGREGATE | | 1 | 10 | | |
|* 2 | TABLE ACCESS FULL| ORDER_ITEMS_NORMAL | 3545K| 33M| 1766K (1)| 00:01:09 |
-----------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
2 - filter("RETURN_DATE" IS NOT NULL AND "DISPATCH_DATE"<=TO_DATE('
2012-01-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND "DISPATCH_DATE">=TO_DATE('
2012-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
統計
----------------------------------------------------------
1 recursive calls
0 db block gets
6488011 consistent gets
6486895 physical reads
0 redo size
586 bytes sent via SQL*Net to client
514 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
1 rows processed
実行時間は44秒、フルスキャンで範囲検索し、物理読込みブロック数は6,486,895ブロックでした。
次に、非パーティションテーブルからパーティションテーブルを作成してみましょう。
レンジ・パーティションで6ヶ月分のデータを1ヶ月ごとに分割してみたいと思います。
作成は、CREATE TABLE AS SELECT(CTAS)でやってみます。
SQL> CREATE TABLE "SOEPART"."ORDER_ITEMS_RANGE"( 2 "ORDER_ID", 3 "LINE_ITEM_ID", 4 "PRODUCT_ID", 5 "UNIT_PRICE", 6 "QUANTITY", 7 "DISPATCH_DATE", 8 "RETURN_DATE", 9 "GIFT_WRAP", 10 "CONDITION", 11 "SUPPLIER_ID", 12 "ESTIMATED_DELIVERY" 13 ) TABLESPACE "SOEPART" PARALLEL 16 PARTITION BY RANGE("DISPATCH_DATE") 14 ( PARTITION sales_q1_2012 VALUES LESS THAN (TO_DATE('2012/02/01','yyyy/mm/dd')) SEGMENT CREATION IMMEDIATE TABLESPACE "SOEPART" NOCOMPRESS, 15 PARTITION sales_q2_2012 VALUES LESS THAN (TO_DATE('2012/03/01','yyyy/mm/dd')) SEGMENT CREATION IMMEDIATE TABLESPACE "SOEPART" NOCOMPRESS, 16 PARTITION sales_q3_2012 VALUES LESS THAN (TO_DATE('2012/04/01','yyyy/mm/dd')) SEGMENT CREATION IMMEDIATE TABLESPACE "SOEPART" NOCOMPRESS, 17 PARTITION sales_q4_2012 VALUES LESS THAN (TO_DATE('2012/05/01','yyyy/mm/dd')) SEGMENT CREATION IMMEDIATE TABLESPACE "SOEPART" NOCOMPRESS, 18 PARTITION sales_q5_2012 VALUES LESS THAN (TO_DATE('2012/06/01','yyyy/mm/dd')) SEGMENT CREATION IMMEDIATE TABLESPACE "SOEPART" NOCOMPRESS 19 ) 20 AS 21 SELECT * FROM ORDER_ITEMS_NORMAL 22 ; 表が作成されました。 経過: 00:01:54.18 SQL> select count(*) from ORDER_ITEMS_RANGE; COUNT(*) ---------- 714147925
非パーティションテーブルからパーティションテーブルを作成するのに、1分54秒と短時間で
パーティションテーブルを作成することができました。
同様に7億件のデータ(6ヶ月分)から1ヶ月分のデータを範囲検索し問い合わせ時間を確認してみましょう。果たしてどうなるでしょうか!?
SQL> select count(return_date) from order_items_range
2 where dispatch_date between to_date('2012/01/01','yyyy/mm/dd') and to_date('2012/01/31','yyyy/mm/dd');
COUNT(RETURN_DATE)
------------------
3544139
経過: 00:00:15.12
実行計画
----------------------------------------------------------
Plan hash value: 3386248500
-------------------------------------------------------------------------------------------------------------
| Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | Pstart| Pstop |
-------------------------------------------------------------------------------------------------------------
| 0 | SELECT STATEMENT | | 1 | 10 | 437K (1)| 00:00:18 | | |
| 1 | SORT AGGREGATE | | 1 | 10 | | | | |
| 2 | PARTITION RANGE SINGLE| | 175M| 1673M| 437K (1)| 00:00:18 | 1 | 1 |
|* 3 | TABLE ACCESS FULL | ORDER_ITEMS_RANGE | 175M| 1673M| 437K (1)| 00:00:18 | 1 | 1 |
-------------------------------------------------------------------------------------------------------------
Predicate Information (identified by operation id):
---------------------------------------------------
3 - filter("DISPATCH_DATE">=TO_DATE(' 2012-01-01 00:00:00', 'syyyy-mm-dd hh24:mi:ss') AND
"DISPATCH_DATE"<=TO_DATE(' 2012-01-31 00:00:00', 'syyyy-mm-dd hh24:mi:ss'))
統計
----------------------------------------------------------
5 recursive calls
0 db block gets
1594036 consistent gets
1593775 physical reads
2392 redo size
586 bytes sent via SQL*Net to client
513 bytes received via SQL*Net from client
2 SQL*Net roundtrips to/from client
2 sorts (memory)
0 sorts (disk)
1 rows processed
物理読込ブロック数は、「6,486,895」から「1,593,775」と
約1/4
に減少し、
実行時間は44秒から15秒に短縮し、結果として
約3倍高速化
することができました。
パーティション・プルーニングが有効かどうかは、実行計画に出力される「
PARTITION RANGE SINGLE
」で確認できます。もし、「PARTITION XXX ALL」と実行計画に出力されている場合はパーティション・プルーニングが効いていない状態です。
パーティション・プルーニングが有効にならない場合は、以下の点をチェックしてみましょう。
など
パーティショニングを利用する場合でも、ノーマルテーブルと同じように統計情報の収集が必要ですが、大規模テーブルの場合は、自動オプティマイザ統計収集の実行時間内に統計情報の収集が終わらないことがあります。
統計情報が収集できていないと、適切な実行計画が選択されずパフォーマンスに悪影響を与える可能性があります。そのため、必ず統計情報を収集できるように、大規模なパーティショニングテーブルでは、手動での統計情報収集をオススメします。
パーティショニングの統計情報収集は、グローバル(テーブル全体)、パーティション(各パーティション)、サブパーティション(コンポジット・パーティション利用時に取得する統計)のレベルで収集できるため、どのレベルまで統計情報を収集するかの検討も必要です。
例
GATHER_TABLE_STATSプロシージャを使用してテーブル単位で統計情報を取得する場合
granularityオプションでどこまで統計情報を収集するのかを決定します。
など
検証では約3倍の改善でしたが、実際の業務ではどれくらいの効果があるのでしょうか。
弊社のお客様事例をご紹介します。
| 課題 | データ増加により、大量データのDELETE処理が遅くなっている(データ連携システム) |
|---|---|
| 対応 | 既にパーティショニングを利用していたが、効果が低い状況だったため、 コンポジット・パーティションに変更 し、さらに 索引をパーティション化 |
| 効果 | SQL1回あたりの実行時間が「86.6秒」から「36.1秒」に短縮し、 58%のレスポンス改善 。その他の処理についてもパーティション再設計の恩恵を受け、アプリケーションの実行時間は 約23%の短縮 を実現しています。 |
| 課題 | MERGE文を使用したバッチ処理が遅くなっている(分析系システム) |
|---|---|
| 対応 | パーティション単位を「 月次単位の分割 」から「 日次単位の分割 」に変更 |
| 効果 | アクセス対象の範囲が月次単位から日次単位に絞られたことで、SQL1回あたりの実行時間が「623.3秒」から「169.7秒」に短縮し、 73%のレスポンス改善 。結果、夜間バッチの遅延も解消されています。 |
| 課題 | 複数サーバーから同時実行されるINSERT処理の影響で索引のブロック競合が発生し、処理遅延が発生(料金計算系システム) |
|---|---|
| 対応 | ノーマルテーブルと索引を コンポジット・パーティション化(レンジ +ハッシュ) |
| 効果 | ブロック競合が緩和されたことで、SQL1回あたりの平均実行時間 × SQL実行回数の累積時間が「2234時間」から「111時間」に短縮し、 95%のレスポンス改善 。 |
今回の三つの事例から、改めてパーティショニングの効果をご理解いただけたかと思います。
EEの有償オプションであるパーティショニングをいきなり購入するのは費用面でハードルが高いが、「自社のシステムでパーティショニングの効果があるか試してみたい!」というお客様もいらっしゃるかと思います。
そのようなお客様にはOracle Cloudを利用した検証をオススメします。
Oracle Cloudでは、EEをサブスクリプションで利用できるため、検証に必要な費用を抑えられます。さらに、Oracle Cloud独自のライセンス体系で、様々なEEオプション込みのサービスが用意されているため、Oracle Partitoning以外の機能検証も可能です。
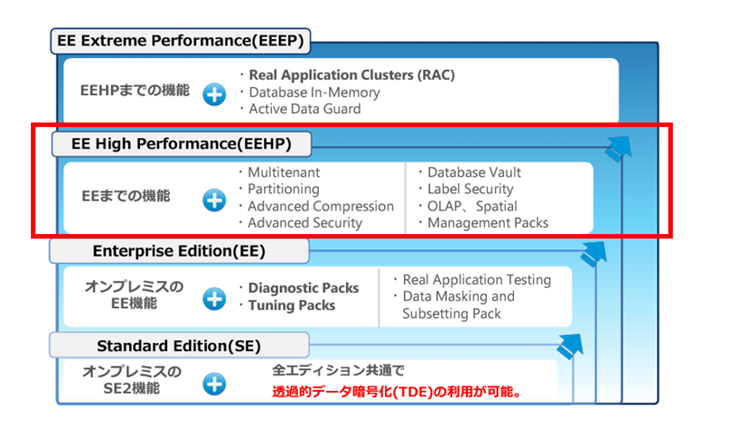
例えば、Oracle Partitiningを利用できる「EE High Performance」を選択するとOracle MultitenantやOracle Advanced Compression、Oracle Advanced Securityなどのオプションを追加費用無しで利用できます。
|
|
この他にもOracle Databaseの新バージョンへの移行検証や、今後のクラウド移行に向けた性能・運用検証も気軽にできるため、ぜひOracle Cloudのご利用をご検討いただければと思います。
今回はパーティショニングの機能と効果を、検証結果や事例を交えながらご紹介しました。
本ブログではご紹介しきれませんでしたが、パーティショニングを実装する場合には、設計時の考慮点や運用時の注意点もございます。
弊社では「パーティショニングを本格的に採用したい」「パーティショニングをうまく活用できていない」というお客様向けに、パーティショニング設計・実装支援やオリジナルテキストを使った教育支援を提供しております。
また、パーティショニング支援以外にもOracle Databaseの技術支援を豊富に取り揃えております。例えば、システム更改を控えたお客様にはExadataやOracle Database Applianceといったオラクル社のアプライアンス製品のご提案や実装支援も提供しておりますので、何かお困りごとがございましたら、弊社窓口までお気軽にご相談ください。
<参考記事>
クラウドサービス後発組ならでは!Oracle Cloud Infrastructure(OCI)の魅力とは?
https://www.ashisuto.co.jp/pr/west/article/column-202307.html
Exadata最新モデル「X10M」登場!圧倒的な拡張性を備えたOracle Databaseプラットフォームを徹底解説!
https://www.ashisuto.co.jp/db_blog/article/exadata-x10m.html
Oracle Database Applianceとは?大手企業の採用実績も豊富なODAのメリットを徹底解説!
https://www.ashisuto.co.jp/db_blog/article/oracle-database-appliance.html

|
|---|
2011年に中途入社。
西日本支社のデータベースの技術部門で、Oracle Databaseのフィールドエンジニアとして活動中。 2020年から重点顧客を担当し特定顧客向けにプリセールス活動も行っている。趣味は野球と食べ歩き。...show more
■本記事の内容について
本記事に記載されている製品およびサービス、定義及び条件は、特段の記載のない限り本記事執筆時点のものであり、予告なく変更になる可能性があります。あらかじめご了承ください。
■商標に関して
・Oracle®、Java及びMySQLは、Oracle、その子会社及び関連会社の米国及びその他の国における登録商標です。
・Amazon Web Services、AWS、Powered by AWS ロゴ、[およびかかる資料で使用されるその他の AWS 商標] は、Amazon.com, Inc. またはその関連会社の商標です。
文中の社名、商品名等は各社の商標または登録商標である場合があります。

今年もアシストはOracle AI World Tour Tokyo 2026に出展しました。「AIの真価はデータ基盤で決まる」をメッセージに、既存システムを改修しない「AIサイドカー戦略」をご紹介。AI活用やOCI移行に関するお客様の興味関心も増したイベントのハイライトを詳しくレポートします。

ランサムウェア対策では、バックアップを取るだけでなく守れることが重要です。本記事では、OCIのZRCVがなぜ有効なのかを、論理的エアギャップ、暗号化、削除阻止、完全性確認の観点から、仕組みとRMANの検証結果を交えて解説します。

生成AIブームの今、Oracle AI Database 26aiで提供される新機能であるSelect AIを使うことで、専門的なSQLスキルがなくても自然言語でDBに問い合わせて、即座にデータ分析ができるようになりました。本記事ではSelect AIの仕組みと具体的な活用シーンを分かりやすい例とともにご紹介します。


