


![]()





|
|
「DXのために社内外のデータ活用を促進させる!」
言葉では簡単ですが、なかなかすぐに解決できる課題ではありません。
デジタルトランスフォーメーション(DX)を推進していく中で、社内のデータ基盤を見直すという企業も増えているかと思います。しかし、社内で様々なデータベースやクラウドサービスを使用している場合、すでにデータの分散とサイロ化が進んでしまっているなどの理由で、DXへのハードルが高く感じられます。
この記事では、「サイロ化を防ぐにはどうしたらいいの?」「DXを推進すると言っても、データが散在していてどう連携させたらいいか分からない」といった課題解決のヒントとなるよう、「分散型のデータ基盤におけるデータ連携ツールの活用」というテーマでお話ししていきます。
<目次>
▶DX時代におけるデータ基盤の重要性
▶分散型データ基盤の特徴
▶分散型データ基盤のよくある課題
▶DataSpiderでサイロ化を防ぐ!
▶ツールの活用事例をご紹介
そもそもDXの目的とは何でしょうか。経済産業省が2018年12月に発表した「DX推進ガイドライン」によれば、DXの定義は下記の通りです。
「企業がビジネス環境の激しい変化に対応し、データとデジタル技術を活用して、顧客や社会のニーズを基に、製品やサービス、ビジネスモデルを変革するとともに、業務そのものや、組織、プロセス、企業文化・風土を変革し、競争上の優位性を確立すること」
参考:https://www.meti.go.jp/press/2018/12/20181212004/20181212004-1.pdf
まとめると、「データやデジタル技術の活用」を手段として、抜本的な「変革」を行いながら「競合優位性を確立」することです。この「競合優位性の確立」こそが、DXの最終的な目的です。
つまり、データやデジタル技術を活用することは、DX時代において変革の手段であり、大前提として捉えられます。データの活用は強固なデータ基盤なしには実現できませんから、DXの目的である「競合優位性の確立」を達成するためには、強固なデータ基盤の構築が必要不可欠なのです。
では、どのようにデータ基盤を構築すればよいのでしょうか。データ基盤を実現するアーキテクチャはいくつかありますが、この記事では日本企業に多い「分散型」のデータ基盤について述べていこうと思います。
分散型データ基盤は、社内外の様々なデータを複雑に連携させるアーキテクチャであり、例えば次のようなケースに向いています。
分散型データ基盤では、既存のシステム構成を大きく変えずに、データベースやアプリケーションの追加ができます。そのため自由度が高く、基盤構築のハードルも低いという特徴があります。
企業によっては既存のシステムに変更を加えるのが難しいケースがありますから、こうした実現のしやすさと柔軟性は、分散型データ基盤の長所と言えます。
基盤構築自体はハードルが低いと思える分散型データ基盤ですが、実は運用が非常に難しく、特にデータを連携する方法についてはよく考える必要があります。
その理由は、データの「サイロ化」が起きやすいからです。
データのサイロ化とは、各部門でシステムが個別最適化されてしまい、他部門と連携されずに独立して運用されている状態を指します。
日本企業に多い分散型データ基盤では、複数のシステムにデータが散在するという構成上、データガバナンスやデータ連携の方式が固まっていないと、システムごとに個別最適化が進み、サイロ化しやすいという欠点があります。
繰り返しになりますが、DXの目的は「データの活用」を進めながら、最終的には企業としての「競合優位性を確立」することです。システムごとの個別最適化は、全社的なデータの活用を妨げてしまうので、DXの推進とは真逆の方向に向かってしまいます。
ここまで話を進めていくと、分散型のデータ基盤にはデメリットが大きいというイメージを持たれるかもしれませんが、分散型データ基盤には柔軟性と拡張性が高いという長所があります。この長所を活かせば、社内外のデータ活用が促進され、DXへ向けての大きな一歩を踏み出すことができます。
では、分散型データ基盤において、データ連携を密に行い、サイロ化を防ぐためにはどうすればよいのでしょうか。
その答えが「データ連携ツールの活用」です!
弊社で取り扱っているデータ連携ツール「DataSpider」には、下記のような特徴があります。
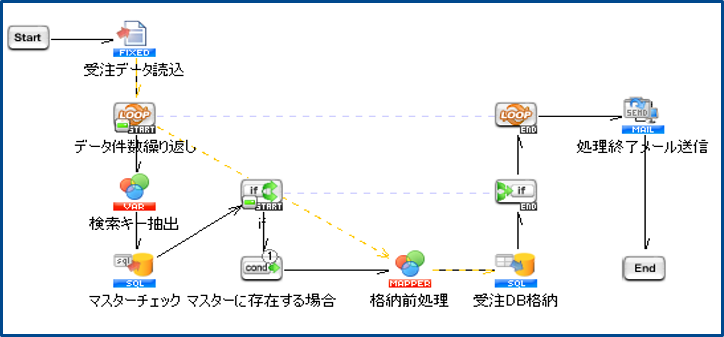
GUI画面のノンプログラミング開発により、すばやく簡単に社内外のデータを連携することができます。下記はDataSpiderにおける開発画面のイメージです。
|
|
データ連携にはスクラッチ開発という手段もありますが、データ連携ツールではアイコンベースで開発ができる環境を用意しているため、より簡単に各システム間のデータを連携させることが可能です。
さらに、このアイコンベースの開発環境により、視認性の高いスクリプトを作成することができるため、開発の属人化を抑えることもできます。
こうした開発生産性の高さや、保守管理のしやすさは、ノンプログラミング開発ならではの強みと言えます。
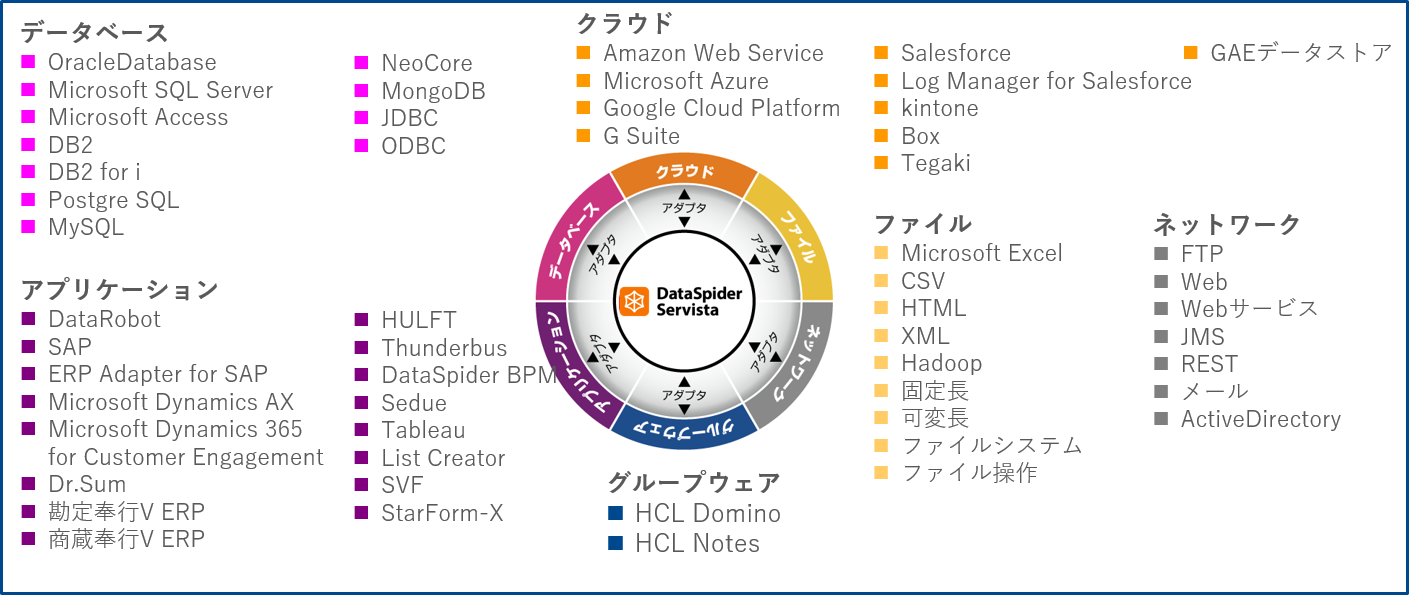
データ連携ツールは、データベースやアプリケーション、クラウドサービス等の様々な接続先をサポートしており、社内外の多様なデータ連携ニーズに応えることができます。例えばDataSpiderは、具体的に下記のような接続先をサポートしています。
※下記は2021年4月現在の情報です。
|
|
こうした多様な接続先に対しても、アイコンの設定から簡単に接続ができますので、スクラッチ開発よりも工数をかけずに連携処理を作成することができます。
分散型データ基盤の課題として運用負荷が高いというものがありましたが、データ連携ツールでは実行タイミング制御やユーザ管理など、運用管理の機能も搭載されています。そのため、開発負荷だけでなく、運用負荷も軽減することができます。
例)・月に一回処理を動かす設定にしたい!
・ジョブ管理ツールなどから処理を呼び出したい!
・複数人/複数チームで開発を行いたい!
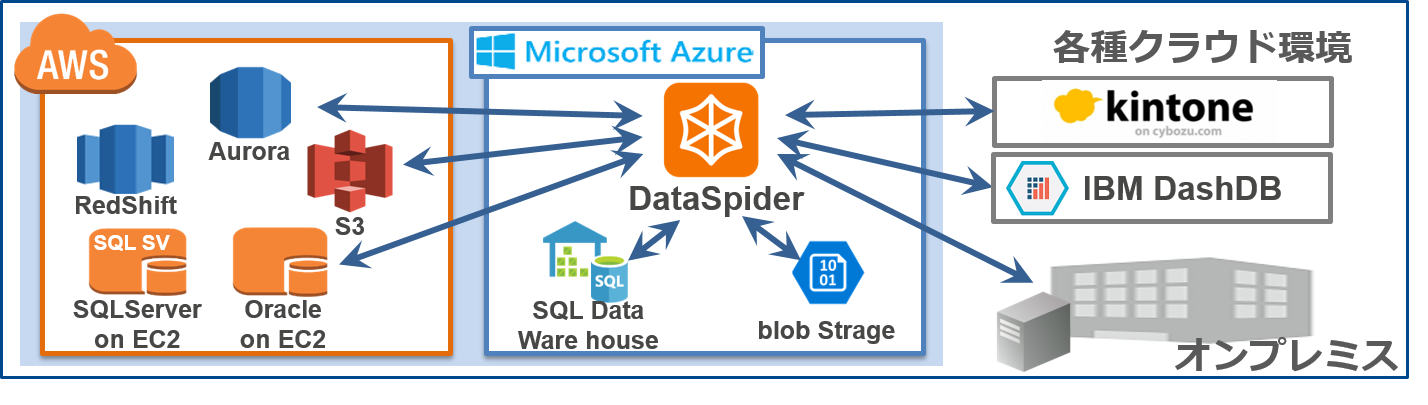
ここまで分散型データ基盤の特徴や、データ連携ツールの活用という観点でDXについて述べてきました。最後に、DataSpiderを活用してデータ基盤を構築した事例として、ゲオホールディングス様の事例をご紹介いたします!
ゲオホールディングス様ではDataSpiderを活用することで、各種クラウド間、およびクラウドとオンプレミス間のデータ連携を実現しています。
|
|
このような全社的なデータ基盤が整備できたことで、各システムに分散していたデータを活用する土台ができあがり、各部門からの要求に対しても柔軟な対応が可能になりました。DataSpider導入による具体的な効果は下記の通りです。
このように、データ連携ツールによって連携基盤を整えたことで、スピーディーな変革のサイクルへとつながっている事例となっております。
最後まで本記事をご覧いただきありがとうございました!DXやデータ活用について考えるうえで、少しでも参考になりましたら幸いです。また、DXに限らずデータ活用にお困りのことがございましたら、お気軽に弊社までご相談ください!
下記リンクでは、データ連携ツールを検討いただく際の選定ポイントや、そもそもデータ連携ツールでどのようなことができるのかなどを紹介している資料をご用意しております。情報収集の材料として、ぜひこちらの資料もご活用ください!
|
|