








Progress Corticon
【Corticon Tech コラム】
No.20 『機械学習をルールベースAI:Corticonで実装する』(2017年9月1日)
|
|

2016年4月からProgress製品を担当しています棚橋浩志です。昨今『AI』はじめ『深層学習』や『Deep Learning』という言葉をよく見かけるようになりました。一方で『機械学習
』という言葉はめっぽう減りました。 この単語の違いは何でしょうか?興味ある方は米NVIDIA社の2016年7月29日の公式ブログでマイケル・コープランド氏が「What’s the Difference Between Artificial Intelligence, Machine Learning, and Deep Learning?」を執筆しています。
さて話は変わりますが私たちにとっては長い長い子供達の夏休みがやっと終わりました。その夏休み中に愚息の水泳大会や剣道大会の引率をしましたが一日費やす割りに子供の出番は正味10分もありませんでした。そこで、その長い長い空き時間を利用して『深層学習』の本を数冊読んでみました。
4年前に、ある『機械学習』の製品を弊社取り扱いのQlikViewに取り込むConnectorを開発したときに『教師ありの学習』について学習しましたが、その時と比較して変わったことは
1) プログラミング言語が機械学習(深層学習)をサポートしはじめ身近に開発・利用できるようになった
2) CPUを使用しないでGPUで処理するようになった
3) 1次元で多要素の解析よりも多次元で要素の少ない解析が主流になってきた
ことでした。
教師あり学習
『機械学習』には『教師あり学習』と『教師なし学習』の2通りの方法があります。『深層学習』や『Deep Learning』は主に『教師あり学習』を指しています。
『教師あり学習』とは、教師となる模範データを多量に解析して傾向を見出して、新しい事象に適応する方法になります。 google社の『AlphaGo』は世界中の棋士の棋譜をCPUの処理速度を50倍程度上回るGPUで解析した結果と『さまざまな調整』を施して人間に勝利して有名になりました。 この『さまざまな調整』とは勝利するために多大な試行錯誤が行われた結果でありこの部分は確率統計学を極めないと手が出せない部分と思われます。 また解答が正しくない場合には、正しいデータを何度も取り込んで学習させる必要があります。 一方で模範データを多くすると『過学習』という負の面が現れて、事象の全体を見ることができなくなりますのでバランスの調整が必要になります。
このように『教師あり学習』とはある種『模範解答』が存在して、その解答にいかに近づけるかを『さまざまな調整』によって行うことで、この『さまざまな調整』は『教師あり学習』の中核を構成する部分になります。 そしてこの『さまざまな調整』をプログラミング言語が機械学習(深層学習)をサポートしはじめたとはいっても汎用化されたパラメータを使用するものであり、到底専用のアプリケーションとして精度不足になります。 そして精度不足の時に何をどのようにすればよいかという手法が見出せないところがまだまだ『機械学習』の試行錯誤の段階ではないでしょうか。 これは QlikView の Connector を開発していた時から実感していたことでしたが、今回読んだ書籍でもこの部分が簡単になったという記述はありませんでした。
教師なし学習
『教師なし学習』とは『教師あり学習』の逆で解答がないことを言います。 しかし解答がないといっても目標のようなものがないと学習できません。 『教師なし学習』の例としてGoogle DeepMindの「DQN」は、ブロック崩しゲームのルールをコンピュータが自分で学習し人間よりも高得点が得られるようになりました。
『教師なし学習』の場合には解答はないのですが、『高得点』という目標はあります。
『教師なし学習』のときに出てくる命題として『多腕バンディット』があります。この命題を考えてみましょう。
ある確率で"当たり"と"はずれ"の二者択一が抽選されるスロットマシーン(抽選機)があります。
今70%の確率で"当たり"が出るスロットマシーンAと40%の確率で"当たり"が出るスロットマシーンBがあります。
どのように選ぶと"当たり"の回数が最多になるでしょうか。
『教師あり学習』の場合には
1)スロットマシーンAを10,000回実行させると"当たり"が出る確率は70%位になります。
2)スロットマシーンBを10,000回実行させると"当たり"が出る確率は40%位になります。
3)スロットマシーンAとスロットマシーンBの結果を比較して、スロットマシーンAを初回から実行し続けると最大になる。
という結果になります。
しかし『教師なし学習』では利用できる情報は実行した結果しかありません。あなたならどうしますか?
教師なし学習 よくある手法
『確率のよいスロットマシーンを抽選する』が単純明快です。しかし『確率のよいスロットマシーン』に定義が不明確です。2回実行した結果や10回実行した結果という明確な定義がなければプログラムは記述できません。
例えば『累積結果を比較して確率のよいスロットマシーンを次回使用する。結果が同じ場合には別のスロットマシーンを次回使用する。』としましょう。ルールは明確です。
1)スロットマシーンAを実行する。
残念ながら30%の"はずれ"を引いてしまいました。
スロットマシーンAとスロットマシーンBの"当たり"を引いた累積結果を0%なので次回はスロットマシーンBを
使用します。
2)スロットマシーンBを実行する。
偶然にも40%の"あたり"を引いてしまいました。
スロットマシーンAの累積結果(0/1)0%とスロットマシーンB(1/1)100%と比較して次回はスロットマシーンBも
使用します。
3)スロットマシーンAの確率は0%のために以後スロットマシーンBを使用し続け最終的は40%位になります。
しかしこの方法は確率のよいスロットマシーンが初回抽選のときに"はずれ"を抽選した場合には誤った選択になる事を意味しています。
| 累積試行回数 | スロットマシーンA (70%) | スロットマシーンB (40%) | ||||
|
マシーン別 試行回数 |
結果 |
マシーン別 確率 |
マシーン別 試行回数 |
結果 |
マシーン別 確率 |
|
| 1 | 1 | はずれ | 0/1=0% | |||
| 2 | 1 | あたり | 1/1=100% | |||
| 3 | 2 | はずれ | 1/2=50% | |||
| 4 | 3 | はずれ | 1/3=33% | |||
| 5 | 4 | あたり | 2/4=50% | |||
| 6 | 5 | あたり | 3/5=60% | |||
| 7 | 6 | はずれ | 3/6=50% | |||
| 8 | 7 | はずれ | 3/7=42% | |||
| 9 | 8 | はずれ | 3/8=37% | |||
| 10 | 9 | はずれ | 3/9=33% | |||
人間は目標がわかっているから、何とか正しい方法で確率のよいスロットマシーンAを選ばせるように画策します。これが上記の『さまざまな調整』になります。これは『教師なし学習』も同じです。ある意味ずるいと感じる部分ですね。
教師なし学習 さまざまな調整
上記ルールに下記の条件を加えて見ましょう。
最初にスロットマシーンAを2回実行した結果とスロットマシーンBを2回実行した結果を比較して、
以後は確率のよいスロットマシーンを使用する
なかなかよい『調整』ですね。これは仮説検定のABテストになります。このように"スロットマシーンAを2回実行(検定)する"ことを『探索(EXPLORE)』と呼びます。 『探索(EXPLORE)』した後にその探索結果を基に特定のスロットマシーンを使用する事を『活用(EXPLOIT) 』と呼びます。
このコラムは確率・統計学ではないので私が計算したいところ 15%位でスロットマシーンBが選択されます。
『探索(EXPLORE)』は2回で十分でしょうか?10回にすれば十分でしょうか?根本的に確率だけではこの命題をとくことが難しいのです。何か違う策が必要になります。
教師なし学習 UCB1アルゴリズム
この命題をとく方法としては代表的な以下のアルゴリズムをはじめさまざまなアルゴリズムが生み出されています。
■Epsilon-Greedyアルゴリズム
■Softmaxアルゴリズム
■UCB1(Upper Confidence Bound 1 Algorithm)アルゴリズム
本稿ではアルゴリズムの解説ではないので各アルゴリズムの詳細は読者の皆様に調べてもらうことにしてUCB1アルゴリズムの計算式を評価してみましょう。
|
|
a "この"スロットマシーンで当たりがでた累積回数
n "この"スロットマシーンで抽選した累積試行回数
N すべてのスロットマシーンで抽選した累積試行回数
C 定数
このUCBアルゴリズムを『探索(EXPLORE)』に利用して以下のルールを机上で実践してみましょう。
初期値として全スロットマシーンを実行してUCB1値を出す
UCB1値が一番大きいスロットマシーンを選択する
UCB1値が一番大きいスロットマシーンが複数存在する場合は直前のスロットマシーンを選択する
定数Cを2とする
| 累積試行回数 | スロットマシーンA (70%) | スロットマシーンB (40%) | ||||||
|
マシーン別 試行回数 |
結果 |
マシーン別 確率 |
マシーン別 UCB1値 |
マシーン別 試行回数 |
結果 |
マシーン別 確率 |
マシーン別 UCB1値 |
|
| 1(初期値取得) | 1 | はずれ | 0/1=0% | 0 | - | |||
| 2(初期値取得) | 1.665 | 1 | あたり | 1/1=100% | 2.665 | |||
| 3 | 2.096 | 2 | はずれ | 1/2=50% | 1.982 | |||
| 4 | 2 | はずれ | 0/2=0% | 1.665 | 1/3=33% | 2.165 | ||
| 5 | 1.794 | 3 | はずれ | 1/3=34% | 1.798 | |||
| 6 | 1.893 | 4 | はずれ | 1/4=25% | 1.589 | |||
| 7 | 3 | あたり | 1/3=34% | 1.944 | 1.645 | |||
| 8 | 4 | あたり | 2/4=50% | 1.942 | 1.692 | |||
| 9 | 5 | あたり | 3/5=60% | 1.926 | 1.732 | |||
| 10 | 6 | あたり | 4/6=67% | 1.906 | 1.767 | |||
スロットマシーンAを選択する回数が多そうですね。偶然なのか必然なのかは試行回数を増やして検証する必要があります。
UCBアルゴリズムをCorticonで実装する
前節で使用したルールをCorticonで実装してみましょう。
まずはスロットマシーンを作成します。これは乱数発生器である下記演算子を使用します。
RandomGenerator.getRandomNumber
この演算子は0以上1以下の『デシマル』型の値を作成します。私はこの値の小数点以下第4桁の数字を取り出して、0から9迄の数字1文字を作成しました。
(((RandomGenerator.getRandomNumber * 10000).toInteger).mod(10)).toString
私の経験上乱数発生関数は結構値が偏る傾向が多いために『小数点以下第4桁の数字』を使用しています。 またルールテストで上記スクリプトを100万回実行を数回テストしましたが、生成される数字の出現率はほぼ1/10になる事を確認しました。
残りは抽選結果を累積保持するルールシートを加えます。表示結果としてスロットマシーンAおよびスロットマシーンBの実行回数および"あたり"の回数を表示させます。
bandit.ecore
|
|

語彙属性と設定値
| エンティティ名 | 属性名 | データ型 | 必須 | モード | 説明 |
| bandit | スロットマシーンになります | ||||
| latestN | 整数 | いいえ | 一過性 | 実行時の試行回数カウンター | |
| next | Boolean | いいえ | 一過性 | 次回使用するスロットマシーンはtrue 次回使用しないスロットマシンはfalseを保持する |
|
| number | 文字列 | はい | ベース | "あたり"と判定する数字の文字列 | |
| result | Boolean | いいえ | ベース | "あたり"の場合はtrue、はずれの場合はfalseを保持する | |
| try | 整数 | いいえ | ベース | マシン別の累積試行回数 | |
| ucb1 | デシマル | いいえ | 一過性 | UCB1値を計算して保持する | |
| win | 整数 | いいえ | ベース | マシン別の"あたり"を抽選した累積回数 | |
| wstring | 文字列 | いいえ | 一過性 | 乱数発生器で抽選した数字1文字 | |
| test | 検証環境になります | ||||
| expectedNumberOfTrials | 整数 | はい | ベース | 予定試行回数 | |
| numberOfTrials | 整数 | いいえ | 一過性 | 試行回数カウンター | |
| ucb1_c | デシマル | はい | ベース | UCB1値計算時に使用する定数Cの値 | |
| bandit(bandit) | banditと1:nの関連性を持たせる | ||||
Corticonで汎用的なルールを作成するために、latestN,nextという属性を作成しています。プログラミング言語で作成する場合には不要な変数です。
まずは属性を初期化するルールシートを2つ作成します。尚この2つの初期化ルールシートの実行順序は問いません。
initialize1.ers
|
|
testエンティティのnumberOfTrials属性をゼロクリアします。
initialize2.ers
|
|
banditエンティティのtry属性とwin属性をゼロクリアします。またnext属性をT(true)でクリアします。
いよいよ本処理部分のルールを作成します。まずは特定のスロットマシンを抽選するルールを作成します。
banditForLoop.ers
|
|
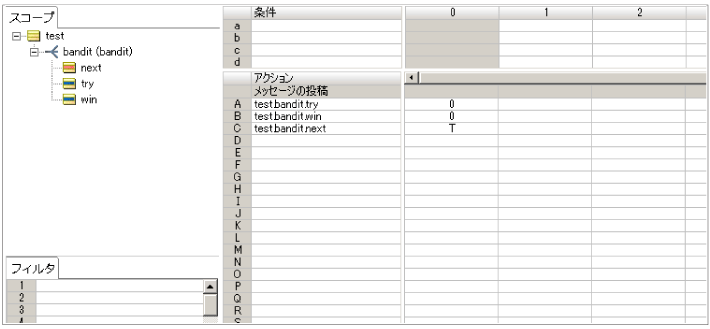
画像をクリックで拡大
0行目で bandits.wstring に乱数を基に、任意の数字1文字を作成しています。
加えて マシン別の累積試行回数 である test.bandit.try をカウントアップしています。また試行回数カウンターである test.numberOfTrials をカウントアップしています。 次に条件項目a列で作成された文字列 bandits.wstring が事前に設定した文字列 test.bandits.numberに存在するかどうか検証して存在する場合には"あたり"と判定して test.bandits.result に T(true) を設定します。また"あたり"の場合にはマシン別の"あたり"を抽選した累積回数をカウントアップします。
このようにスロットマシンの確率は test.bandits.number に設定された文字で決定されます。数字が7文字設定されていれば70%の確率に、4個設定されていれば40%になります。
UCB1値を計算するルールを作成します。
ucb1.ers
|
|
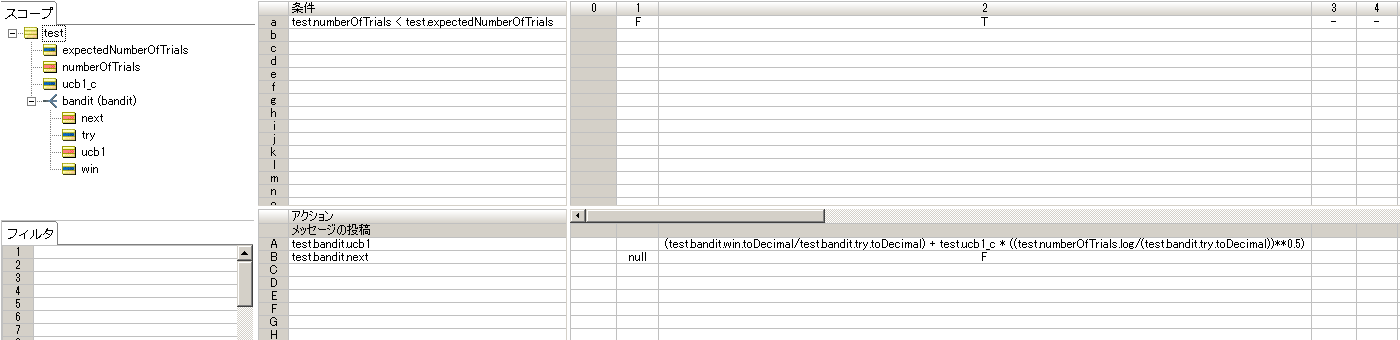
画像をクリックで拡大
抽選するスロットマシーンはフィルターを使用して bandits.next=T を設定します。初期処理の時には必ず全スロットマシーンを実行するので initialize2.ers で全スロットマシーンの bandits.next に T を設定しています。
初期処理以降は必ず1台 bandits.next に T を設定して、予定試行回数を超えた場合には null を設定しています。
予定試行回数以下の場合は全スロットマシーンのUCB1値を計算して test.bandit.ucb1 属性に格納し、次に実行するスロットマシーンを決定するために bandits.next を F クリアします。予定試行回数を超えた場合には null を設定します
次の実行するスロットマシーンを決定するルールを2段階で作成します。
next1.ers
|
|
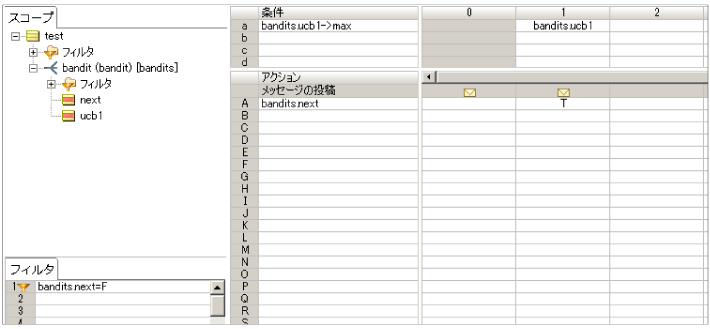
UCB1値が最大のスロットマシーンを選択する為に、コレクション演算子を使用して bandits.ucb1->max が bandits.ucb1 と同じスロットマシーンの bandits.next 属性に T を設定します。
次にUCB1値が同値の場合には、直前のスロットマシーンを使用するというルールを実装します。
next2.ers
|
|
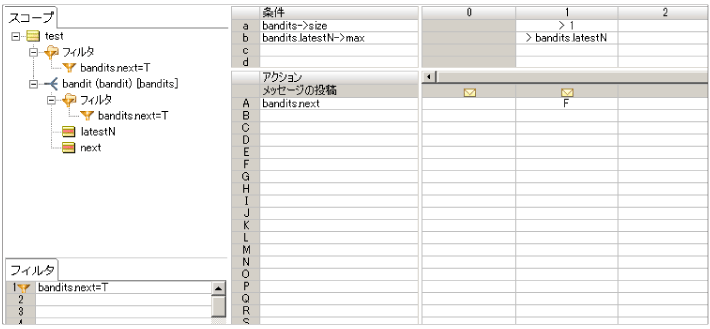
抽選の都度、使用されたスロットマシーンの bandits.latestN 属性に test.numberOfTrials を設定しているので、(直前のスロットマシーン) = (bandits.latestN 値が大きいスロットマシーン) になります。
上記ルールシートをルールフローで制御します。
test.erf
|
|
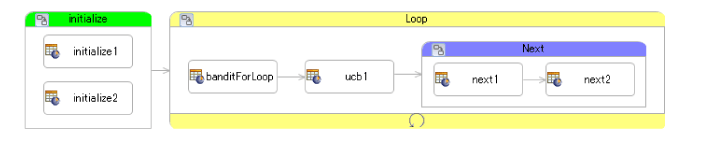
Loopというサブフローを作成してループ部分を格納します。最後にこのLoopサブフローにループ設定をしてます。
※ brms.propatiesのループ設定
ルールの設定は以上になります。いよいよテストを実施しますが試行回数を50,000回を想定してます。Corticonのデフォルト設定ではループの最高回数が100回に制限されているのでこの値を引き上げる必要があります。
com.corticon.reactor.rulebuilder.maxloops=1000000
上記設定は上限を1,000,000回にする設定です。プロパティファイルを上書きしてください。 詳しくは『Corticon Studio:クィックリファレンスガイド』 P13、または『Corticon Server:インテグレーション& デプロイメントガイド』『付録 C : Corticon のプロパティおよび設定の構成』"オーバーライド ファイル brms.properties の使用"を参照ください。
それではテストを設定します。
予定試行回数である text.expectedNumberOfTrials に 50000 を設定します。 スロットマシン2台を設定します。 test.bandit を2つ作成します。 抽選確率を2台のスロットマシーンに設定します。1台は70%なので test.bandit(bandit).number に文字列 "1246890" という数字7文字を設定しました。抽選確率が70%になります。 1台は40%なので test.bandit(bandit).number に文字列 "2468" という数字4文字を設定しました。抽選確率が40%になります。
それでは実行してみましょう。
test.ert
|
|
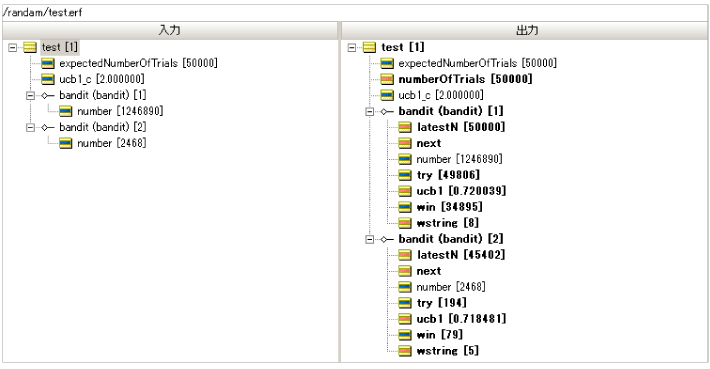
| 項目 | スロットマシーンA bandit(bandit)[1] |
スロットマシーンB bandit(bandit)[2] |
| マシン別の累積試行回数 | 49806 | 194 |
| マシン別の"あたり"を抽選した累積回数 | 34895 | 79 |
| マシン別の"あたり"の確率 | 34895 / 49806 = 0.701 | 79 / 194 = 0.407 |
| マシンを選択した割合 | 49806 / 50000 = 0.996 | 194 / 50000 = 0.004 |
スロットマシーンAの確率が70%で、スロットマシーンBの確率が40%になります。
そして驚くべき値としてスロットマシーンAを選択した割合が97%近くになりました。
信じられない数値が出たので100,000回で検証してみましょう。
test.ert
|
|
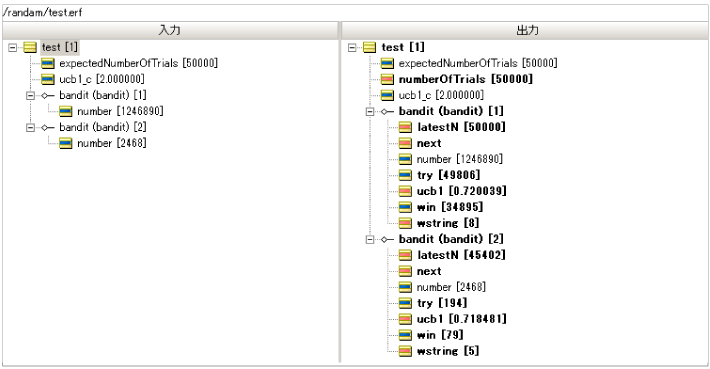
| 項目 | スロットマシーンA bandit(bandit)[1] |
スロットマシーンB bandit(bandit)[2] |
| マシン別の累積試行回数 | 99785 | 215 |
| マシン別の"あたり"を抽選した累積回数 | 69882 | 88 |
| マシン別の"あたり"の確率 | 69882 / 99785 = 0.700 | 88 / 215 = 0.409 |
| マシンを選択した割合 | 99785 / 100000 = 0.998 | 215 / 100000 = 0.002 |
それでは回数を大幅に減らして100回で検証してみましょう。
test.ert
|
|
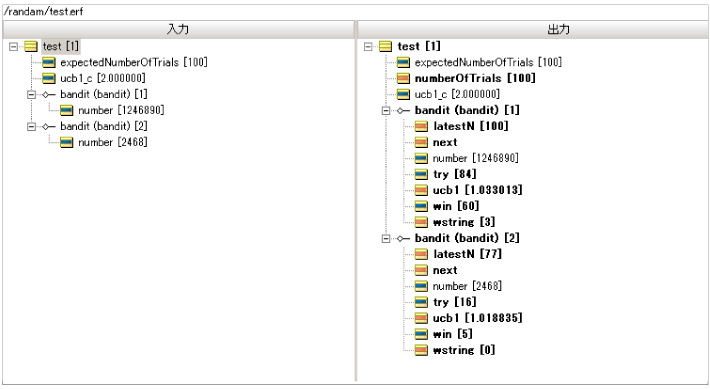
| 項目 | スロットマシーンA bandit(bandit)[1] |
スロットマシーンB bandit(bandit)[2] |
| マシン別の累積試行回数 | 84 | 16 |
| マシン別の"あたり"を抽選した累積回数 | 60 | 5 |
| マシン別の"あたり"の確率 | 60 / 84 = 0.714 | 5 / 16 = 0.313 |
| マシンを選択した割合 | 84 / 100 = 0.84 | 16 / 100 = 0.16 |
今度は確率20%のスロットマシーンCと確率10%のスロットマシーンDを増やして50,000回の再度検証してみましょう。
test.ert
|
|
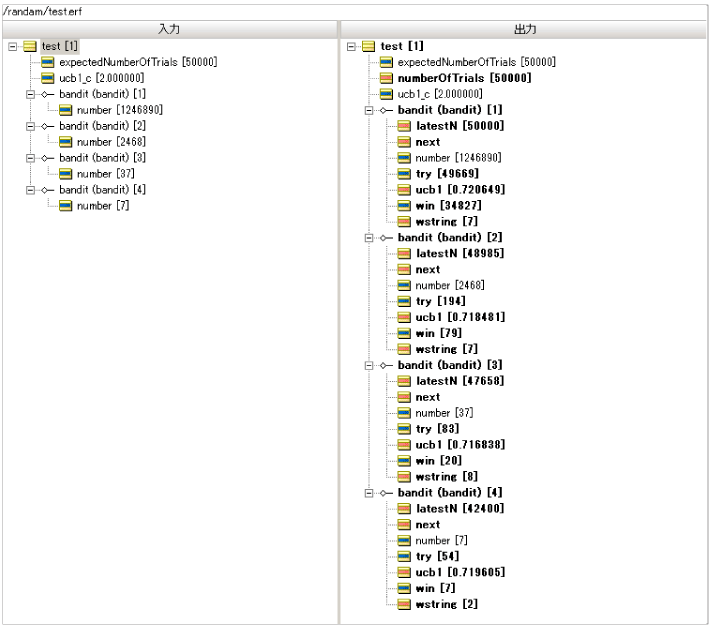
| 項目 | スロットマシーンA bandit(bandit)[1] |
スロットマシーンB bandit(bandit)[2] |
スロットマシーンC bandit(bandit)[3] |
スロットマシーンD bandit(bandit)[4] |
| マシン別の累積試行回数 | 49669 | 193 | 84 | 54 |
| マシン別の"あたり"を抽選した累積回数 | 34827 | 79 | 20 | 7 |
| マシン別の"あたり"の確率 | 34827 / 49669 = 0.701 | 79 / 194 = 0.407 | 20 / 83 = 0.241 | 7 / 54 = 0.123 |
| マシンを選択した割合 | 49669 / 50000 = 0.9936 | 194 / 50000 = 0.004 | 83 / 50000 = 0.001 | 54 / 50000 = 0.001 |
さいごに
教師なし学習のアルゴリズムは今後改良が加えられたり、あるいは別のアルゴリズムが出てくるかもしれませんが、UCB1(Upper Confidence Bound 1 Algorithm)アルゴリズムはとても優秀でビジネスでもいろいろ応用できそうですね。
一方でビジネスで使用する場合には、定数Cの値の決定方法や計算された値をどの様に利用するかという部分での試行錯誤が必要になってきます。
「Corticondで機械学習できますか?」というご質問をよく頂きます。解答は上記の様に『できます』というものの、試行錯誤部分はCorticonではできません。すなわち定数Cを決定することや、計算された確率をどのように使用するかも決定でません。
仮にCorticonが多数のアルゴリズムと定数Cを数パターン搭載したテンプレートを実装したとしても、最後には人間がどのアルゴリズムのどの定数Cを採用して、計算された値をどう使用するか意思決定する必要があり、この部分までの自動化は残念ながらできません。
また機械学習ではなぜその結果が導き出されたかと分析することはほぼ不可能といわれています。逆を言えばアルゴリズムAとアルゴリズムBのどちらを採用するか、定数Cが 2.0 と 1.0のどちらを採用するかという事は簡単に判別することができません。
この辺りまだまだ機械学習は遠い存在となっている部分でもあると思われます。
「Corticon Tech コラム」記事一覧
|
|

お求めの情報は見つかりましたでしょうか。

お客様の状況に合わせて詳しい情報をお届けできます。お気軽にご相談ください。

- 2025.6.2
 アシスト、ルール開発効率を大幅に向上させる「Progress Corticon 7.1」を提供開始
アシスト、ルール開発効率を大幅に向上させる「Progress Corticon 7.1」を提供開始 - 2022.11.16アシスト、DXに欠かせないルールべースAI「Progress Corticon」の新バージョン6.3を提供開始
- 2022.4.7
 アシストがProgress社製品の販売活動において「Progress Accelerate Partner Distributor」を受賞
アシストがProgress社製品の販売活動において「Progress Accelerate Partner Distributor」を受賞 - 2022.2.16
 生命保険エコシステム リリース第2弾 「生命保険給付金支払いプラットフォーム」採用2社目
生命保険エコシステム リリース第2弾 「生命保険給付金支払いプラットフォーム」採用2社目 - 2021.11.17生命保険エコシステム リリース第1弾 「生命保険給付金支払いプラットフォーム」始動



