ケーススタディ


ケーススタディ
AWS上にデータレイクを構築し、すべてのデータをユーザー部門自身で分析できるように
課題
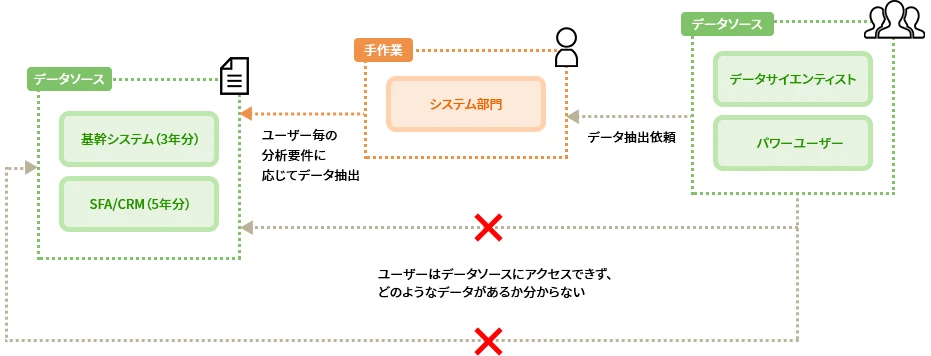
課題01:分析対象データの期間と粒度を揃えて分析できていなかった
課題02:新たな分析は、データの蓄積からシステム部門に依頼しなければならなかった
課題03:新たなビジネス発掘のために社内のデータを探索したいが、どのようなデータがあるのか分からなかった
AWSによる解決策
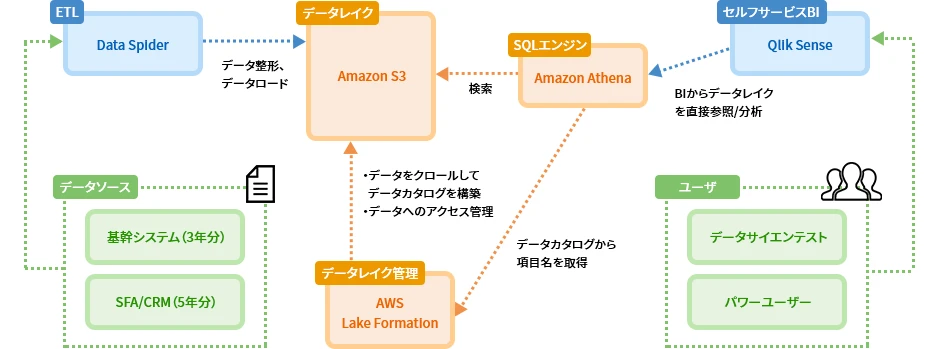
- Amazon S3をデータレイクとして採用し、各システムのデータを捨てずに全て蓄積した。
- Amazon Athenaを使用してデータレイクのデータをSQLで直接参照し、さらにQlik Sense(BI)で可視化/分析した。
- データレイクには最低限の整形のみを行った生データを保存し、AWS Lake Formationで蓄積されたデータのデータカタログを構築した。
導入効果
- これまでよりも長期間のデータを分析でき、新たな発見を得られるようになった。
- データレイクとデータカタログによって源泉データが一元管理されているため、新しい分析要件に対して柔軟に対応できるようになった。
- アシストから提供したデータレイク構築スタートアップ支援により、自分達でスムーズにデータレイクの構築と運用を推進できるようになった。
システム概要図
BEFORE
AFTER

お問い合わせ
CONTACT US
AWSのご相談・
お見積もりはこちら
AWSの導入や運用に関するお悩みはありませんか?
お見積もりやご相談は、簡単なフォームから受け付けています。