








Progress Corticon
【Corticon Tech コラム】
No.30 DBと連携する新機能ADCについて(2018年12月11日)
|
|

Corticon には、もともとディシジョン・サービス実行中にDBと連携するためのEDC (※)という機能があります。
Corticon 5.6からは、このEDCとは別に、新たなADC (Advanced Data Connector)というDBと連携する機能が追加されました。(もともとのEDC機能も従来と変わらずに使用できます。)
今回の記事では、Corticonのインストーラーに同梱されているADCを使用したサンプルをもとに、ADCの使い方と処理内容、EDCとの違いについて紹介します。
- ※Enterprise Data Connector の略です。機能の詳細はCorticon 5.6では製品マニュアル「Integration and Deployment Guide」に記載されています。また、本ブログの「No.6 Corticonの呼び出し方と処理速度について (大量データ処理EDC編) 」でも紹介しています。
[記事執筆環境]
Corticon 5.6.1
PostgreSQL 9.4
概要とサンプルの動作確認
ADCの機能を端的にまとめると、ルールフローのサービスコールアウト(※)の一つとして動作し、ディシジョン・サービス実行時にDBにアクセスし、DBのデータとルールの入出力値を連携します。
一般的なサービスコールアウトでは実行するプログラムをユーザー自身が実装する必要がありますが、ADCではプログレス社が提供しているADC用のJARファイルを使用するため、ADCを使用する場合はユーザーがJavaプログラムを開発する必要はありません。
- ※サービスコールアウトとはルールフロー処理中に外部のJavaプログラムを呼び出す機能です。機能の詳細は製品マニュアル「Guide to Creating Corticon Extensions」に記載されています。また、本ブログの「No.10 Corticonの【拡張演算子】と【サービスコールアウト】を使ったルール実装のしかた 」でも紹介しています。
ADCを使用するには、以下の準備を行います。
●語彙のエンティティ・属性・関連性とDBテーブルのスキーマ情報をマッピングします。
►これは従来のEDCと同じ考え方、同じ方法で実施します。
●ルールプロジェクトの「プロパティ」「Corticon Extensions」でプログレス社から提供されているADC用の
拡張機能JARファイルを設定します。
►指定するJARファイルは「<Corticon Studioインストールフォルダ>\addons\adasco\CcADASco.jar」です。
●ルールフローのサービスコールアウトで、ADC拡張機能を選択し適切なオプションを設定します。
●ルールの入力データとして取り扱う実データが入ったテーブルとは別に、ADC実行に必要な特殊なメタデータが
入ったテーブルが必要です。
►以降、本記事では前者を実データ用テーブル、後者をメタデータ用テーブルとします。
►実データ用テーブルとメタデータ用テーブルは同じDB内にあっても良いですし、別のDB内にあっても
かまいません。
●ルールシートの実装はEDC使用時のようにDB拡張やDBフィルタを意識する必要はありません。通常のルールと
同じように実装します。
●ルール実行時は、EDC使用時のように「DBアクセス」を設定する必要はありません。通常のルールと
同じように実行します。
►ただし、実行時にはADC用のデータソース設定ファイル(メタデータ用テーブルDBの接続設定)が必要です。
►また Corticon ServerでADCを使用したデシジョン・サービスを実行する際には、EDCオプションが有効な
ライセンスが必要です。
今回の記事では、「<Corticon Studioインストールフォルダ>\addons\adasco\samples\Sample Simple Keys」の「63-RetrieveABCD.erf」を動作させるためのより具体的な設定や手順と、その内部処理に関して解説します。
以下は、ADCの概要図です。
|
|
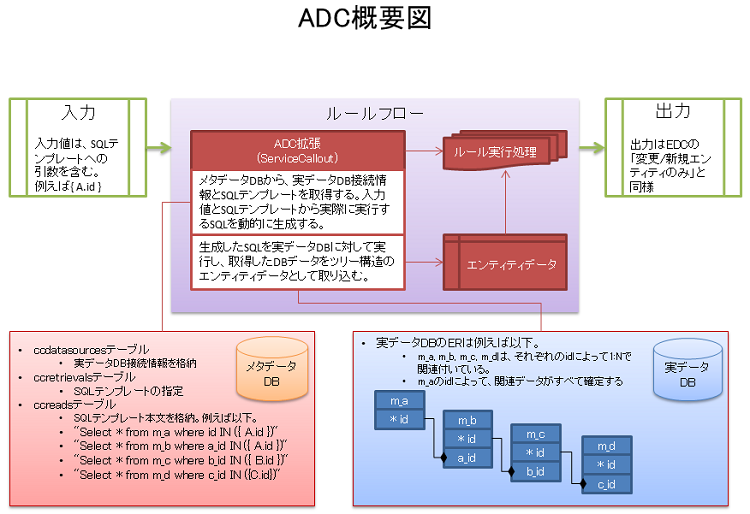
概要図内で例示しているデータ構造やSQLテンプレートは、前述した「Sample Simple Keys」の「63-RetrieveABCD.erf」ものです。
では、このサンプル「Sample Simple Keys」を動作確認してみましょう。
以下の手順が必要です。
1) メタデータ用テーブルと、実データ用テーブルを作成する
2) Corticon Studioでプロジェクトを作成し、ルールアセットをインポートする
3) 語彙マッピングの設定
4) ADC拡張機能の設定
5) ルールの実行と処理内容の確認
それぞれの作業で具体的にポイントとなる箇所をこれから解説します。
(1) メタデータ用テーブルと、実データ用テーブルを作成する
今回の記事では、メタデータ用のテーブルと実データ用のテーブルを、PostgreSQL 9.4内の同じDB「test」の「public」内に作成します。
なお、ADCの対応RDBMSはEDCと同じです。製品のシステム要件のページをご確認ください。
https://www.ashisuto.co.jp/product/category/brms/progress_corticon/detail/list/platform.html
メタデータ用テーブル作成のSQLは「<Corticon Studioインストールフォルダ>\addons\adasco\Core Database Metadata Tables\CreateTables.txt」です。このSQLをDB「test」で実行すれば、ADCで必要なメタデータ用テーブルが全て作成されます。ただし、RDBMSの種類によってはそのまま実行することができなかったり、ADC実行時に問題が発生したりします。例えば本記事では、PostgreSQL用にSQLを以下のように修正し実行しました。
<PostgreSQL向けに修正したメタデータ用テーブルを作成するCREATE文>
create table "ccdatasources"
( "id" integer not null ,
"name" varchar,
"driver" varchar,
"url" varchar,
"username" varchar,
"password" varchar,
constraint "ccdatasources_pk" primary key ("id")
);
create table "ccretrievals"
( "id" integer not null ,
"ccdatasources_id" integer not null ,
"name" varchar,
"addtopayload" varchar,
constraint "ccretrievals_pk" primary key ("id"),
constraint "ccretrieval_ccdatasource" foreign key ("ccdatasources_id")
references "ccdatasources" ("id")
);
create table "ccupdates"
( "id" integer not null ,
"ccdatasources_id" integer,
"name" varchar,
constraint "ccupdates_pk" primary key ("id"),
constraint "ccupdate_ccdatasource" foreign key ("ccdatasources_id")
references "ccdatasources" ("id")
);
create table "ccreads"
( "id" integer not null ,
"ccretrievals_id" integer,
"sequence" integer,
"sql" varchar,
"primary_entity" varchar,
"parent_entity" varchar,
"parent_rolename" varchar,
"enable" varchar,
constraint "ccread_pk" primary key ("id"),
constraint "ccread_ccretrievals" foreign key ("ccretrievals_id")
references "ccretrievals" ("id")
);
create table "ccinserts"
( "id" integer,
"ccupdates_id" integer,
"sequence" integer,
"sql" varchar,
"primary_entity" varchar,
"enable" varchar,
constraint "ccinserts_ccupdates" foreign key ("ccupdates_id")
references "ccupdates" ("id")
);
テーブル名やカラム名がすべて小文字になっていることに注意してください。これはPostgreSQLでテーブル名やカラム名を大文字で作成した場合、ADC実行時に問題が発生することがあるためです。
各テーブルとカラムの意味は、製品マニュアルに詳細が記載されていますが簡単にまとめると以下です。
● CCDATASOURCES
► 実データテーブルへの接続情報
● CCRETRIEVALS
► ADCサービスコールアウト(ルールフロー画面)で設定する、ルール実行時に処理したいクエリ群の定義
● CCUPDATES
► クエリ群内のUPDATEに関連する情報
● CCINSERTS
► クエリ郡内のINSERTに関連する情報。INSERT用のSQLテンプレートも含まれる。
● CCREADS
► クエリ郡内のSELECTに関連する情報。SELECT用のSQLテンプレートも含まれる。
なお、これらメタデータ用テーブルは、ADCサンプル「Sample Simple Keys」用の特有なテーブルではなく、ADCを使用する際はかならず同じスキーマのメタデータ用テーブルを使用します。
これらのメタデータ用テーブルを作成したら、各テーブルにADC用のメタデータを格納します。「Sample Simple Keys」を実行するために必要なデータ(INSERT文)は「<CcStudioインストールフォルダ>\addons\adasco\samples\Sample Simple Keys\Database Scripts\ InsertsIntoCoreMetadataTables.txt」です。こちらの内容に関しては「Sample Simple Keys」特有のデータです。もし別のルールで別のDBに対してADC機能を使用したければ、また別のメタデータを作成することになります。
また、こちらのINSERT文もRDBMSに合わせて修正します。例えば本記事では、PostgreSQL用にSQLを以下のように修正し実行しました。
(ccdatasourcesのDB名やユーザー名、パスワードも変更しています。)
<PostgreSQL向けに修正したメタデータ用テーブルにデータ格納するINSERT文>
insert into "ccdatasources" values (1,'Corticon','com.corticon.database.id.PostgreSQL',
'jdbc:progress:postgresql://localhost:5432;databaseName=test;','postgres','Ashisuto01');
Insert into "ccretrievals" values (1,1,'RETRIEVE_A','false');
Insert into "ccretrievals" values (2,1,'RETRIEVE_AB','false');
Insert into "ccretrievals" values (3,1,'RETRIEVE_ABC','false');
Insert into "ccretrievals" values (4,1,'RETRIEVE_ABCD','false');
Insert into "ccretrievals" values (5,1,'RETRIEVE_ABCD_THRESHOLD','true');
Insert into "ccreads" values (1,1,1,'Select * from m_a where id IN ({ A.id })','A',null,null,null);
Insert into "ccreads" values (2,2,1,'Select * from m_a where id IN ({ A.id })','A',null,null,null);
Insert into "ccreads" values (3,2,2,'Select * from m_b where a_id IN ({ A.id })','B','A','toB',null);
Insert into "ccreads" values (4,3,1,'Select * from m_a where id IN ({ A.id })','A',null,null,null);
Insert into "ccreads" values (5,3,2,'Select * from m_b where a_id IN ({ A.id })','B','A','toB',null);
Insert into "ccreads" values (6,3,3,'Select * from m_c where b_id IN ({ B.id })','C','B','toC',null);
Insert into "ccreads" values (7,4,1,'Select * from m_a where id IN ({ A.id })','A',null,null,null);
Insert into "ccreads" values (8,4,2,'Select * from m_b where a_id IN ({ A.id })','B','A','toB','true');
Insert into "ccreads" values (9,4,3,'Select * from m_c where b_id IN ({ B.id })','C','B','toC','true');
Insert into "ccreads" values (10,4,4,'Select * from m_d where c_id IN ({C.id})','D','C','toD','true');
Insert into "ccreads" values (11,5,1,'Select * from m_a where id IN ({ Parameters.value1 })','A',null,null,null);
Insert into "ccreads" values (12,5,2,
'Select * from m_b where a_id IN ( { A.id } ) and column2 < { Parameters.value2 }','B','A','toB',null);
Insert into "ccreads" values (13,5,3,
'Select * from m_c where b_id IN ({ B.id }) and column3 < { Parameters.value3 }','C','B','toC',null);
Insert into "ccreads" values (14,5,4,
'Select * from m_d where c_id IN ({ C.id }) and column4 > { Parameters.value4 } and column4 < { Parameters.value5 }',
'D','C','toD',null);
Insert into "ccupdates" values (1,1,'ZOUTPUT_1');
Insert into "ccupdates" values (2,1,'ZOUTPUT_1_AND_2');
Insert into "ccinserts" values (1,1,1,
'Insert into Z_OUTPUT1 (ID, TEMP01, TEMP02, TEMP03, TEMP04, TIMESTAMP) VALUES (zOutput1Sequence.nextval, {zOutput1.temp01} , {zOutput1.temp02}, {zOutput1.temp03}, {zOutput1.temp04}, TO_DATE(sysdate, ''YYYY/MM/DD HH:MI:SS''))',
'zOutput1',null);
Insert into "ccinserts" values (2,2,1,
'Insert into Z_OUTPUT1 (ID, TEMP01, TEMP02, TEMP03, TEMP04, TIMESTAMP) VALUES (zOutput1Sequence.nextval, {zOutput1.temp01} , {zOutput1.temp02}, {zOutput1.temp03}, {zOutput1.temp04}, TO_DATE(sysdate, ''YYYY/MM/DD HH:MI:SS''))',
'zOutput1',null);
Insert into "ccinserts" values (3,2,2,
'Insert into Z_OUTPUT2 (ID, TEMP01, TEMP02, TEMP03, TEMP04, TIMESTAMP) VALUES (zOutput2Sequence.nextval, {zOutput2.temp01} , {zOutput2.temp02}, {zOutput2.temp03}, {zOutput2.temp04}, TO_DATE(sysdate, ''YYYY/MM/DD HH:MI:SS''))',
'zOutput2',null);
なお、「Sample Simple Keys」の「63-RetrieveABCD.erf」を実行するだけであれば、上記データのうち「RETRIEVE_ABCD」群に関連するINSERT文だけ(1 - 2行目, 8行目, 17 - 20行目)を実行しても問題ありません。
それ以外のINSERT文は、「Sample Simple Keys」に含まれている「63-RetrieveABCD.erf」以外のルールフロー内で設定されている他のADCサービスコールアウトを実行する際に必要となる情報です。
次に、「Sample Simple Keys」で想定されている実データ用テーブルとその中身のデータを作成します。
実データ用テーブル作成のSQLは「<Corticon Studioインストールフォルダ>\addons\adasco\samples\Sample Simple Keys\Database Scripts\ CreateTables.txt」、データ内容のCSVが「<Corticon Studioインストールフォルダ>\addons\adasco\samples\Sample Simple Keys\Database Scripts\」にある4つのCSVです。ここまでのSQLと同様に、これらはRDBMSによっては修正する必要があります。例えば本記事では、PostgreSQL用にテーブル作成SQLを以下のように修正し、テーブル作成&データのインポートを行いました。
<PostgreSQL向けに修正した実データ用テーブル作成のCREATE文>
create table "m_a"
( "id" integer not null ,
"column1" integer,
"column2" integer,
"column3" integer,
"column4" integer,
"column5" integer,
constraint "a_pk" primary key ("id")
);
create table "m_b"
( "id" integer not null,
"a_id" integer,
"column1" integer,
"column2" integer,
"column3" integer,
"column4" integer,
"column5" integer,
constraint "b_pk" primary key ("id"),
constraint "b_to_a" foreign key ("a_id")
references "m_a" ("id")
);
create index "index_a_id" on "m_b" ("a_id");
create table "m_c"
( "id" integer not null,
"b_id" integer,
"column1" integer,
"column2" integer,
"column3" integer,
"column4" integer,
"column5" integer,
constraint "c_pk" primary key ("id"),
constraint "c_to_b" foreign key ("b_id")
references "m_b" ("id")
);
create index "index_b_id" on "m_c" ("b_id");
create table "m_d"
( "id" integer not null,
"c_id" integer,
"column1" integer,
"column2" integer,
"column3" integer,
"column4" integer,
"column5" integer,
constraint "d_pk" primary key ("id"),
constraint "d_to_c" foreign key ("c_id")
references "m_c" ("id")
);
create index "index_c_id" on "m_d" ("c_id");
なお、PostgreSQLでは、CSVのほうは修正する必要はありませんが、RDBMSの種類によってはCSVのほうも改行コードや区切り文字の修正が必要かもしれません。
CSVをインポートしたら、m_a, m_b, m_c, m_d各テーブルのデータ内容を確認します。
前述の概要図でも示していますが、これらのテーブルとデータは1:Nのツリー構造になっており、親に対する子はそれぞれ10個ずつ増えていくCSVデータになっているため、m_aは100件、m_bは1,000件、m_cは10,000件、m_dは100,000件というデータが作成されます。
(2) Corticon Studioでプロジェクトを作成し、ルールアセットをインポートする
Corticon Studioで新たにルールプロジェクト「ADCTest」を作成します。
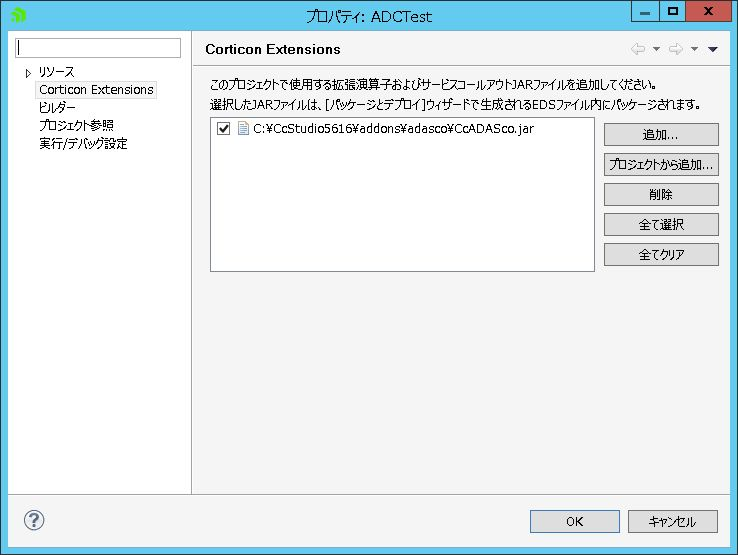
次に「ADCTest」プロジェクトを右クリックして「プロパティ」を選択します。
表示されたプロパティ画面で「Corticon Extensions」を選択し、「<Corticon Studioインストールフォルダ>\addons\CcADASco.jar」を追加します。これがあらかじめ用意されているADC機能用のJARファイルです。
<ルールプロジェクトのプロパティでADC用のJARファイル「CcADASco.jar」を設定したところ>
|
|
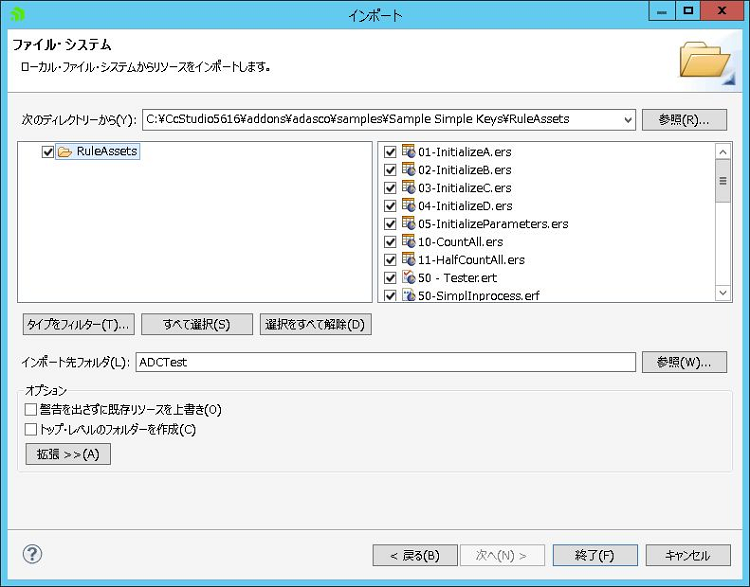
次に「<Corticon Studioインストールフォルダ>\addons\adasco\samples\Sample Simple Keys\RuleAssets\」以下の全ファイルを作成した「ADCTest」プロジェクトにインポートしてください。
<Corticon Studio(Eclipse)のファイルインポート画面>
|
|
(3) 語彙マッピングの設定
ファイルを全てインポートしたら、語彙「DatabaseSCO.ecore」を開きます。
この語彙は、すでにDBスキーマのマッピング済みになっていますが、新たに作成したPostgreSQL内のDBに合わせてデータソース設定やマッピング設定を修正する必要があります。
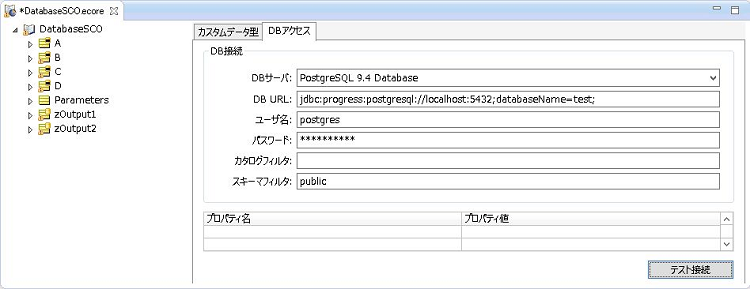
まずは「DBアクセス」タブで、接続先データソースの設定を修正します。
<DBアクセスタブの情報をPostgreSQL用に変更したところ>
|
|
次にCorticon Studioメニューの「語彙」「DBアクセス」「DBメタデータのインポート」で「すべてのテーブルをインポートする」を実行します。
「マッピングのエラーが見つかりました」という警告メッセージが表示されますので、語彙のエンティティ、属性の各マッピング設定を適切に修正します。
<DBメタデータのインポート時に発生する警告>
|
|
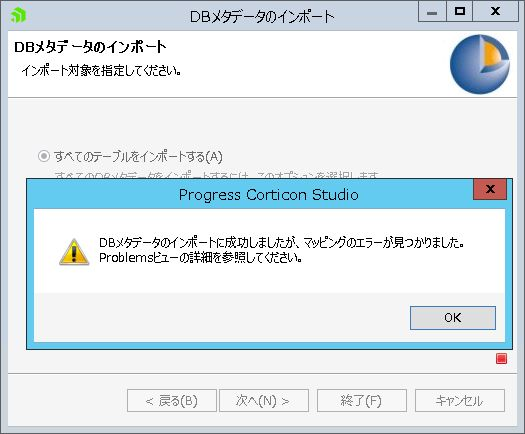
具体的には、PostgreSQL用に、テーブル名とカラム名を全て小文字にし、スキーマを「DATASYNC」から「public」にしたため、それにあわせてA, B, C, D各エンティティと各属性のマッピング設定をすべて修正する必要があります。
例として以下のように修正します。
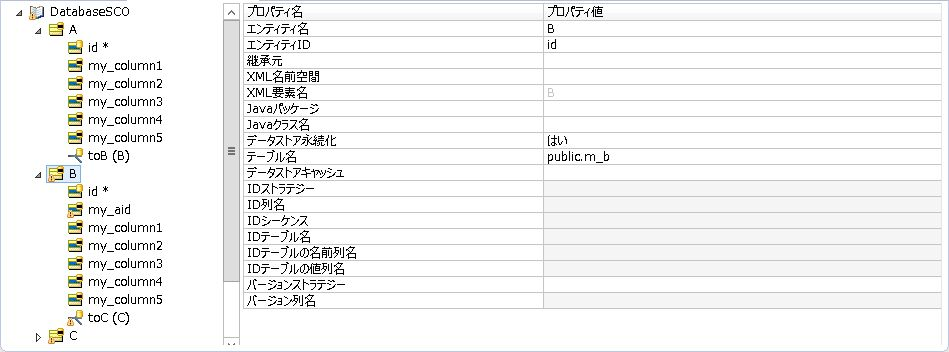
<エンティティBの修正箇所(テーブル名)>
|
|
<エンティティBの属性my_column1の修正箇所(列名)>
|
|
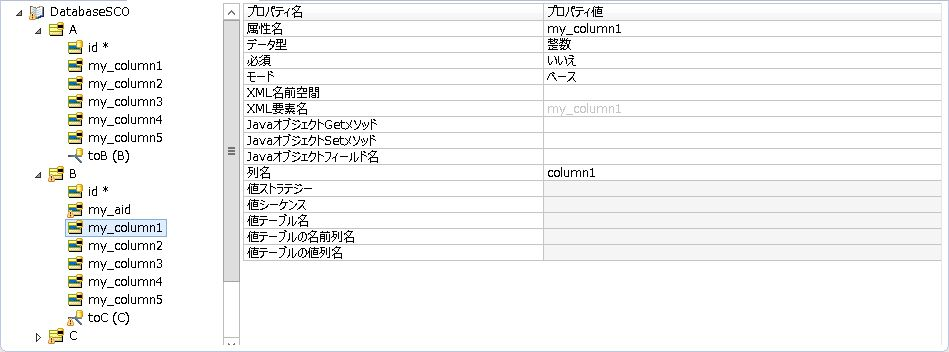
なおエンティティParameters, ZOutput1, Zoutput2に関しては、特に修正する必要はありません。
また、エンティティB, C, DのPostgreSQLでforeign keyに指定されている列は「外部キーは属性にマッピングできません」という警告が残りますが、ADCを使用する「Sample Simple Keys」では特に問題ないので、そのままにします。
(4) ADC拡張機能の設定
ルールフロー「63-RetrieveABCD.erf」を開いてください。
ここでADC機能のサービスコールアウト「Retrieve ABCD」を選択して画面したの「プロパティ」タブの内容を確認してください。(このルールフローではプロパティを設定済みなので内容を変更する必要はありません)
<ルールフロー「63-RetrieveABCD.erf」でサービスコールアウト「Retrieve ABCD」を選択したところ>
|
|
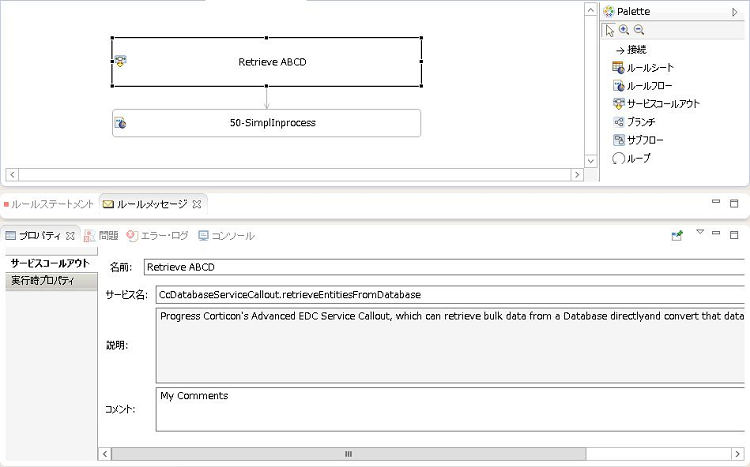
サービス名「CcDatabaseServiceCallout.retrieveEntitiesFromDatabase」は、プロジェクトの「プロパティ」「Corticon Extensions」にCcADASco.jarを追加すると設定可能になります。
また、実行時プロパティに「CcRetrievalsName」, 「RETRIEVE_ABCD」というプロパティと設定値が設定されていることを確認してください。
これは、メタデータ用テーブルCCRETRIEVALSに格納されているクエリ群の名前「RETRIEVE_ABCD」と対応しています。サービスコールアウト実行時にメタデータ用テーブルに格納されている「RETRIEVE_ABCD」に属するクエリが実行される、という設定になっています。
なお、サービスコールアウト実行後は別のルールフロー「50-SimplInprocess.erf」が配置されていますが、こちらは通常のルールフローです。
内容を簡単に解説すると、入力されたエンティティ「A」「B」「C」「D」データそれぞれの全個数および全個数を半分に割った数を算出し、エンティティZOutput1に出力する、というものです。
(5) ルールの実行と処理内容の確認
ルールフロー「63-RetrieveABCD.erf」を実行するには、メタデータ用テーブルに接続するためのデータソース接続設定ファイルを準備する必要があります。
設定ファイルのテンプレートは「<Corticon Studioインストールフォルダ>\addons\adasco\samples\CcADASco.properties」です。
今回はPostgreSQLのDB用に以下のように書き換えました。
<PostgreSQL用に修正したCcADASco.propertiesの内容>
# Properties related to connecting to the Corticon specific SCO Tables
corticon.servicecallout.lookup.name=Corticon
corticon.servicecallout.lookup.driver=com.corticon.database.id.PostgreSQL
corticon.servicecallout.lookup.url=jdbc:progress:postgresql://localhost:5432;databaseName=test
corticon.servicecallout.lookup.username=062032016061051000042048
corticon.servicecallout.lookup.password=015060011032039007059044111082
# (optional) If this is entered, this name will qualify the Table names in the SQL statement.
# This may be necessary based on the Database.
corticon.servicecallout.lookup.schema=public
なお、ドライバー名称や接続URLの値、およびユーザー名とパスワードの暗号化された数値の羅列は、Corticon Studioの語彙画面メニューの「語彙」「DBアクセス」「DBアクセスプロパティのエクスポート」機能や、「プロジェクト」「実行レコーディングスキーマの生成」から取得できます。
作成した「CcADASco.properties」ファイルを「<Corticon Studio WorkDir>」(※)直下に配置し、Corticon Studioを再起動してください。
- ※Corticon Studioインストール時に指定するワークフォルダです。Studio起動時に指定するワークスペースとは別ですので注意してください。
ここまで設定したら、ルールテスト「60 - Tester.ert」を開き、「RetrieveABCD」タブをアクティブにして、テスト実行してください。
<60 - Tester.ertのRetrieveABCD実行結果画面>
|
|
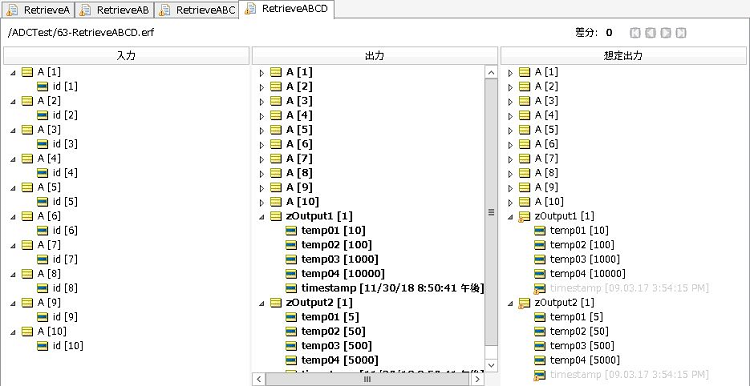
出力内容が想定出力と同じになっていれば、ADCが正しく実行されています。
簡単に処理内容を説明すると、入力値として与えられたAの情報10個に対して、Aに紐付いたB, C, Dの情報をDBから取得しツリー構造の入力データとしてルール内に取り込むところまでがADCの処理になります。Aからツリーが一段下がる毎に10個ずつデータが増えるため、最終的にルールの入力値として処理されるDエンティティのデータは10,000個です。
なお、EDCと異なり、ADC実行時は「ルールテスト」「テストシート」「DBアクセス」の設定は「なし」のままにします。変更する必要はありません。(逆に「DBアクセス」の設定を変更すると正しく動作しないことがあります。)
PostgreSQL側のログ設定を実行クエリ情報まで出力するように変更すると、ルール実行時にどのようなSQLがPostgreSQLで実行されたのか確認することができます。
(具体的な設定変更方法はPostgreSQLのマニュアルなどを参照してください。)
ここでは詳細なログ情報までは載せませんが、PostgreSQLのログから、ルール実行時にメタデータ用テーブル「CCREADS」に登録されている4つのSELECT文が実行されていることがわかります。
メタデータ用テーブルに登録されているSELECT文は{}でくくられた変数部分が含まれたSQLテンプレートであり、実際にSQLが実行される際にはこの変数部分が展開されるため、例えば4つ目のSQLは{C.id}が展開された結果(この場合C.idに該当するデータは1000個です)、かなり長大なSELECT文になります。
EDCとADCの比較
ここまでADCの設定方法と処理内容をみてきましたが、ADCを使用する際は、既存のEDC機能と全く同じ手順で、語彙とDBスキーマをマッピングする設定が必要です。この語彙のマッピング設定部分をADCとEDCで共有している以上、ルール実装の大変さやルール処理時間などの要素を度外視すれば、ADCを使用した全てのルールについて、EDCを使用したルールでも同じ入出力を実現することが可能だ、と言えます。
もちろん、この記事の基になっているサンプル「Sample Simple Keys」の「63-RetrieveABCD.erf」についても、EDCを使用し入出力が全く同じになるルールを実装することが可能です。本記事では比較検証のために、そのようなルールを実際に作成して実行してみました。
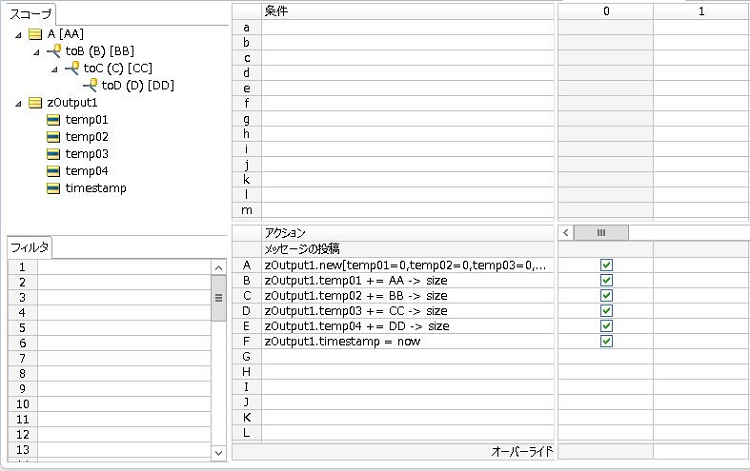
詳細な実装内容は今回の記事では省きますが、画像のようなイメージで、「10-CountAll.ers」, 「11-HalfCountAll.ers」ではADCのときには設定していなかったスコープ部分でツリーの設定(DB拡張)を行っており、テストシートでは「ルールテスト」「テストシート」「DBアクセス」の設定を「読み取り専用」にしています。
<EDCを使用するために修正した10-CountAll.ers >
|
|
<EDCを使用したルールを実行するテスト>
|
|
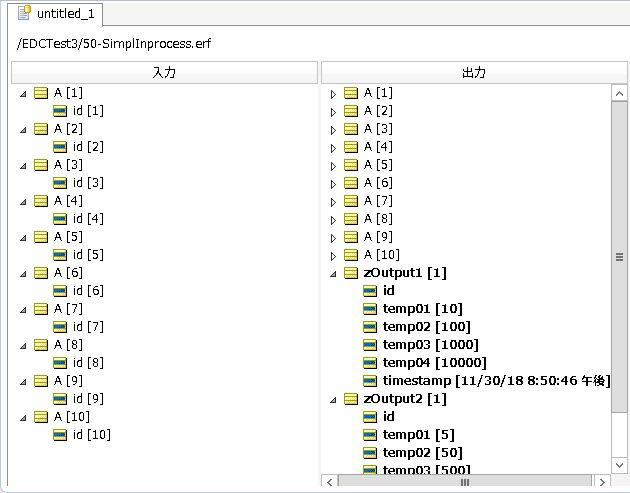
テストの出力を見ると、ADCを使用したルールと全く同じ結果を得られていることが確認できます。
しかし、EDCを使用した場合、この結果が出力されるのに、マシンの性能にもよりますがADCと比べてかなり時間がかかります。
時間がかかる原因を検証するために、ADCのテストと同様にPostgreSQL側のログを確認しました。すると、EDCを使用した場合は、実データテーブルに対して1111回もクエリが実行されていました。そのSQLの内容から、EDCを利用してツリー構造のデータを取得する際は、以下のような非効率的なDB処理が行われていることがわかりました。
<EDCとADCのツリー構造データ取得時の処理の違い>
|
|
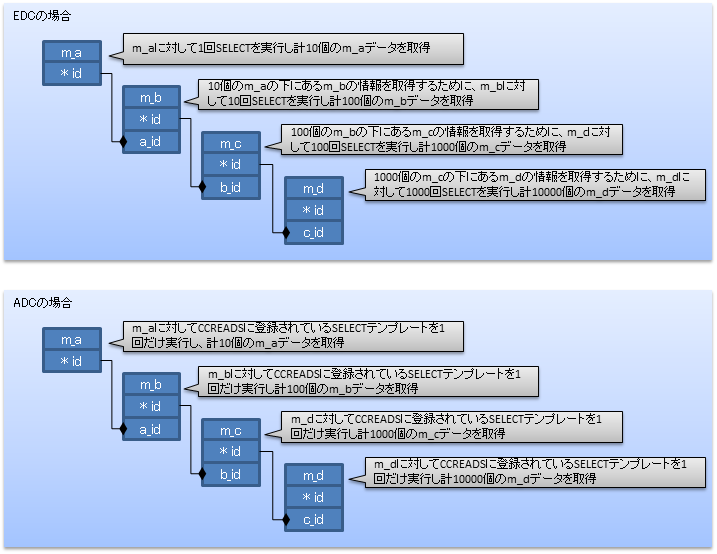
また、EDCではルールフロー内にデータベース拡張されたルールシートが多ければ多いほど何回もDBにアクセスしますが、ADCではルールフロー内でサービスコールアウトが実行されたときだけDBにアクセスするという特徴もあります。
実は、EDCを使ってツリー構造のデータをDBから取得する場合このような非効率な処理になることは、以前から知られており、それを解消するための機能が新機能ADCだ、ということもできます。
まとめ
今回の記事では、「Sample Simple Keys」を実際に動かしてみて、ADCで必要な準備と処理内容に関して紹介しました。
新機能ADCと従来のEDCと比べた際のメリットとデメリットを簡単にまとめると以下のようになります。
●メリット
►EDCに比べてツリー構造データの取得速度が早い
►SQLを記述することができる (※)
●デメリット
►EDCに比べて設定やルール実装が煩雑で難しい
►SQLを記述しないといけない
- ※SQLの記述に関してはメリットともデメリットとも言えるので併記しています。
本記事の内容でも確認できる通り、新機能ADCを利用するには、まだかなり難しく煩雑な設定やSQLの実装が必要です。しかし、どうしてもEDCの処理速度では対応できないような課題がございましたら、一度ADCを検討してみてください。
著者紹介
|
|
情報基盤技術統括部 技術4部 |

「Corticon Tech コラム」記事一覧
|
|

お求めの情報は見つかりましたでしょうか。

お客様の状況に合わせて詳しい情報をお届けできます。お気軽にご相談ください。




