








Modern Data Stackで変わるクラウドネイティブ時代のデータ活用基盤とは?
2024.08.08

|
|---|
<執筆者> 神﨑 崇 Kanzaki Takashi
DX推進技術本部 事業推進統括部 事業推進部 課長
兼 データイノベーションセンター プリセールスチーム マネージャー
前職では、WEBエンジニアとして販売管理・顧客管理システム等の設計・開発に従事。
2014年にアシストへ入社してからは、AIソリューション・データ活用基盤のプリセールスを担当。
収入に対して漫画関連の出費が多すぎることが最近の悩み。
現在のデータ活用基盤の課題
データ活用基盤のあるべき姿は長らく議論されており、データウェアハウスを中心としたシステムアーキテクチャが定着しました。
しかし、時間の経過に従って以下の3つの課題が明らかになってきました。
1.柔軟性の欠如
業務システムと同様のウォーターフォール型開発を採用したため、新たな要件や仕様変更が受けづらくなってしまっています。
また、ライセンス体系の都合上、データ量の増加に対して迅速な対応が難しいケースも多いです。
2.コストの肥大化
サーバーライセンスの場合、データ量やユーザー数で費用を事前に算出しますが、ある程度の拡張を見込んで大きめの基盤にすることが多いです。
しかし、柔軟性が欠如していることで想定よりも活用されず、結果として投資額に見合わない効果しか得られないことがあります。
3.運用負荷
日本企業では「IT関連コストの8割を既存システムの運用維持に投じている」と言われるほど、運用負荷が高いです。
さらに、ユーザー部門からのデータ抽出やデータ提供依頼に追われることで、攻めのDXにリソースを割くことができていません。
これらの課題を解決できるものとして注目されている考え方が「Modern Data Stack」です。
Modern Data Stack とは
Modern Data Stack(MDS)とは、
クラウドネイティブなサービス群によって構成される次世代データ活用基盤の方向性を示すコンセプト
です。
従来のオンプレミスからクラウドへのリフト&シフトではなく、新たにフルマネージドサービスを前提に構築する手法として注目されています。
その中核となるのは従来と同様にデータウェアハウスですが、SaaS型、つまりクラウドデータウェアハウスであることが特徴です。
Modern Data Stack の構成要素
|
|
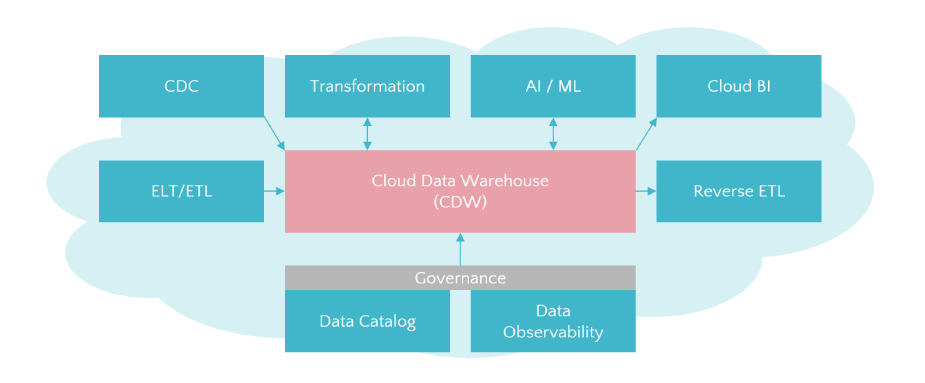
| 構成要素 | 役割 |
|---|---|
| ELT/ETL | クラウドデータウェアハウスにデータを格納する |
| Change Data Capture(CDC) | データベースのログを参照して業務システムのレプリケーションを実現する |
| Transformation | クラウドデータウェアハウスにSQLを発行してデータを加工する |
| AI/ML | クラウドデータウェアハウスに蓄積されたデータを機械学習で活用する |
| Cloud BI | クラウドデータウェアハウスに蓄積されたデータをクラウド型のBIで活用する |
| Reverse ETL | クラウドデータウェアハウスのデータを業務システムに戻す |
| Data Catalog | 組織内外のデータ資産を一元的に整理・管理・検索できるようにする |
| Data Observability | データパイプラインの品質・性能を監視することでデータの信頼性と一貫性を確保する |
Modern Data Stack は、クラウドサービスの特性を生かした以下のようなメリットがあります。
1.フルマネージドサービスで運用負荷を最小化
⇒ IT部門のリソースをDX推進に集中させることができる
2.スケールアップ/ダウンに柔軟に対応
⇒ ビジネス上の機会を最大限に生かすことができる
3.従量課金モデルへの転換
⇒ 利用状況に応じてコストを最適化できる
4.データ活用までのリードタイムを大幅に短縮
⇒ ビジネス施策を迅速に立案・実行できる
このようにメリットを列挙すると非常に魅力的に聞こえますが、あくまで「コンセプト」だと割り切って捉えるべきだと考えます。
なぜなら、実際に自社のデータ活用基盤として具現化させる上では、検討すべき点も多いからです。
Modern Data Stack 実現における検討事項
Modern Data Stack 実現においては、従来とは異なる様々な検討事項が存在します。
その中でも主な3つの検討事項について確認していきましょう。
1.クラウドデータウェアハウスをどう選ぶか?
選択肢は多いですが、3大パブリッククラウドが提供するサービスに加え、プラットフォームを限定しない「Snowflake」などが候補に挙がってくるでしょう。
クラウドデータウェアハウスの選択肢(一例)
・Amazon Redshift
/ アマゾン ウェブ サービス
・Azure Synapse Analytics
/ Microsoft Azure
・BigQuery
/ Google Cloud
・Snowflake
どのデータウェアハウスを選択するかの基準は、従来では主に「コスト」「処理性能」「拡張性」がポイントとなりました。
しかし、クラウドサービスではスケールアップ/ダウンが容易なため「拡張性」は重視されず、優劣がつけがたい「処理性能」も比較されることが少なくなっています。(あくまで製品間の比較がしづらいだけで、性能を重視する場合には、自社での利用を想定した性能評価はすべきだと考えます。)
逆に「コスト」や「全社標準のパブリッククラウドかどうか」は重要なポイントです。
コストについて Moder Data Stack では
「従量課金」がトレンド
です。
ただし、何に対する「従量」なのかはサービスによって異なるため、その点に留意する必要があります。
例えば、「データウェアハウスの稼働時間に対して課金」するサービスであれば、事前に費用を算出することは比較的容易と言えます。
ただ、中には
Snowflakeのように「一定時間クエリが飛んでこない場合、データウェアハウスを停止する」という機能を備えている
サービスもあります。
停止時間は課金されないため、よりコストを削減することができますが、事前に正確な費用を算出することは困難です。
つまり、単価が安ければ良いのではなく、自社の利用イメージに合致する従量課金体系のサービスを選ぶことが大切です。
2.どのようにしてクラウドデータウェアハウスにデータを連携するか?
データウェアハウスへのデータロードは、長らく「ETL」方式が主流となっていました。
オンプレミスのデータウェアハウスはリソースに限りがあるため、事前にデータを加工して受け渡し、データウェアハウスはBIツールなどからのクエリ処理に集中させる方が合理的だという考えです。
しかし、クラウドデータウェアハウスの登場によって
「誰がどのタイミングで加工をするか」
によって、以下の3つのパターンが検討されるようになりました。
クラウドデータウェアハウス時代のデータ加工・連携手段
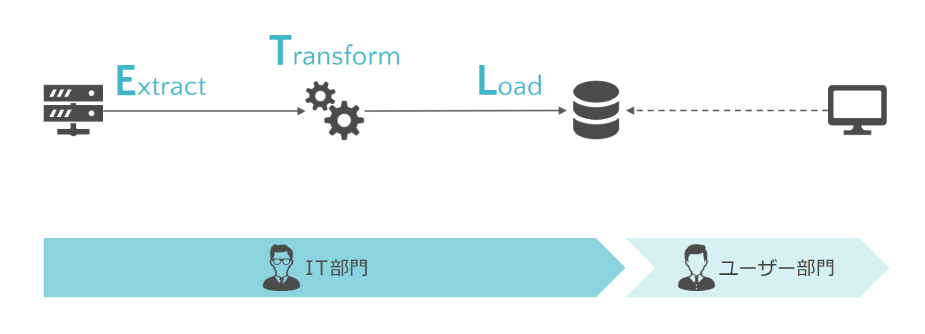
ETL方式
・データを抽出し(Extract)、最適な形にデータ加工した上で(Transform)、データウェアハウスにロードする(Load)
・複雑なデータ加工に加えて、多様なデータソースとの連携が可能なETLツールが用いられる
・IT部門が担う責任範囲が広く、ユーザーからの様々な要望に応える必要がある
<利用するツール例> DataSpider Servista
|
|
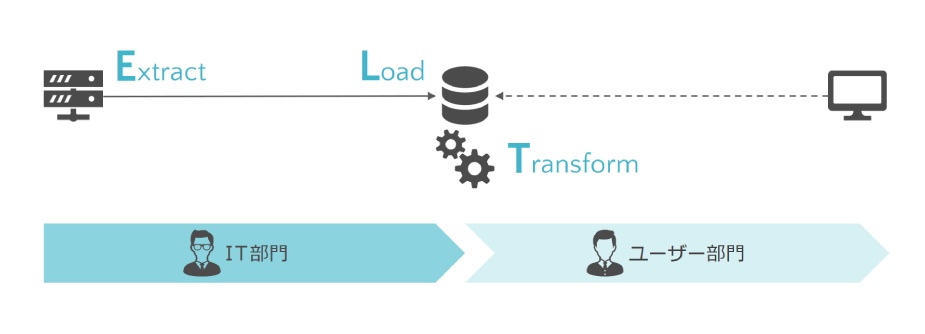
ELT方式
・データを抽出し(Extract)、データウェアハウスにデータロードをしてから(Load)、
クラウドデータウェアハウスの潤沢なリソースを生かしてデータ加工をする(Transform)
・ウォーターフォール開発にならざるを得ないETL方式と異なり、アジャイルなデータ活用基盤を実現できる
<利用するツール例> Fivetran
|
|
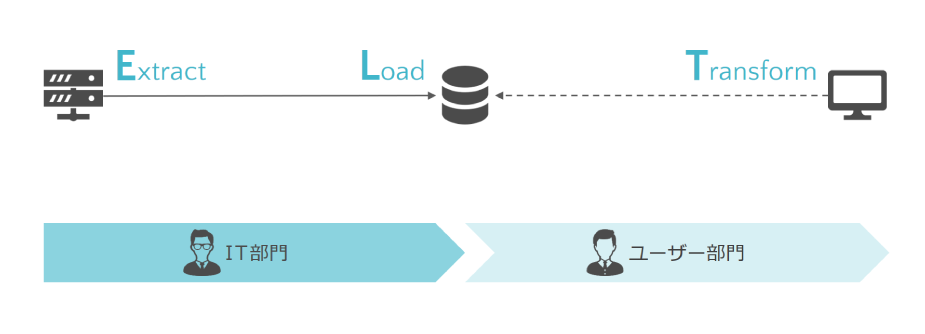
BIツール
・データ加工機能に優れたBIツールで加工することで、ユーザーごとに個別最適化したデータを準備する
・データウェアハウス本来の理念から逆行しているため、全てのデータ加工をBIツールに任せるのではなく、
ETL/ELT方式と組み合わせることが一般的である
<利用するツール例> Qlik Sense
|
|
どの方式を採用するかによって「いつ」「誰が」「どうやって」データを加工するのかが変わります。
そのため、データロード方式を選定する時には、既存ツールやデータ活用人材、体制などを踏まえて検討しましょう。
3.どのようにしてクラウドデータウェアハウスに接続するか?
クラウドサービスが日常的なものとなり、今や「クラウドだからこそ安全」という声もあるほどです。
しかしそれはクラウドサービス内部の話であり、クラウドへの経路、つまりネットワーク設計に関してはユーザー自身が責任を負うことになります。
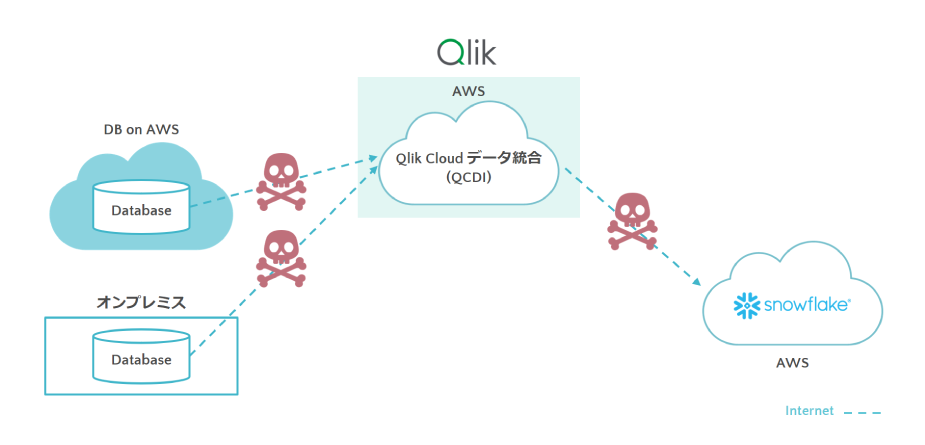
例えば、オンプレミスのデータベースと、AWS上のデータベースからデータを抽出し、Qlik Cloud データ統合(QCDI)
でデータ加工をし、クラウドデータウェアハウスSnowflakeへロードする場合を検討してみましょう。
単純にインターネット経由で接続すると、セキュリティが担保された設計とは言えません。
インターネット経由で接続
|
|
しかし、
各サービスが提供している仕組みを活用することで、セキュアなネットワークを構築する
ことができます。
各データベースをプライベート接続(Private Link)や専用線(Direct Connect)※ で繋ぎ、データの中継地点(Qlik Data Gateway
)を経由すれば、一度もインターネットを通ることなくデータの連携ができます。
※参考コラム:AWS Direct Connectとは?~概要と実装の方法を解説~
プライベート接続/専用線で接続
|
|
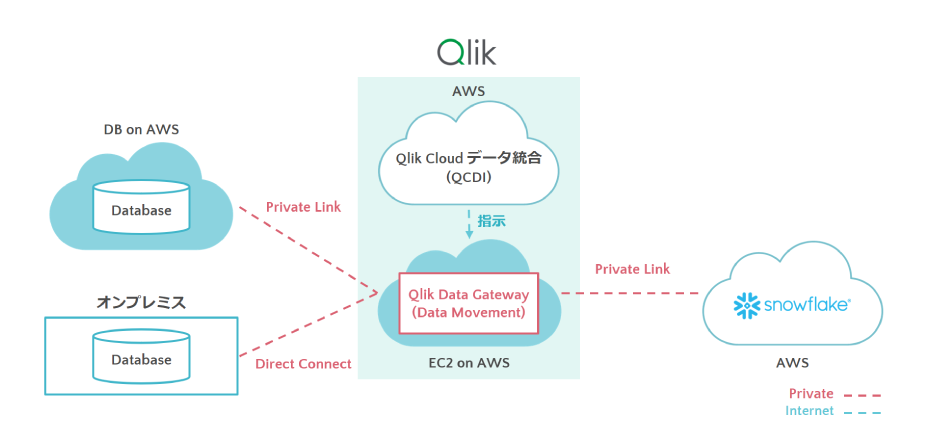
このように、クラウドネイティブなサービスの活用と、強固なセキュリティの両立は可能です。
しかし、これを実装しようとすると、構築の工数もコストもかかります。
クラウドサービスを前提に、自社にとっての最適なセキュリティポリシーを検討するべきだと考えます。
さいごに
このように、Modern Data Stack の実現には、多くのメリットの裏に様々な課題や検討事項があります。
「自社だけで検討するのが難しい」と考える方は、ぜひお気軽にご相談ください。
アシストでは、Modern Data Stack を充分に解釈しながら、そのコンセプトに縛られることなく、すべてのお客様が満足できる「次世代データ活用基盤」を提案しており、以下のようなユースケースを公開しています。
今後も様々なパターンを公開していく予定ですので、ぜひ楽しみにお待ちください。
アシストが考える「次世代データ活用基盤」の構築例
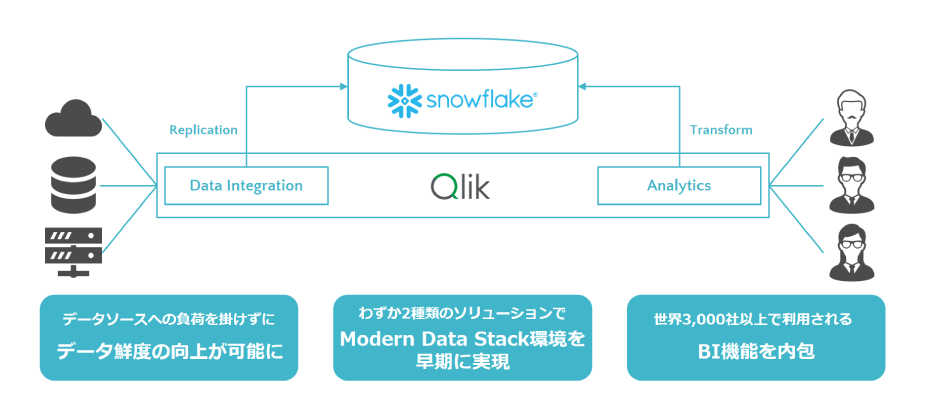
1.日々業務で発生する様々なデータを、すぐにユーザーが活用できるようにしたい
データ活用プロセス全体をカバーする「Qlik Cloud 」× Modern Data Stack の中核「Snowflake 」によって、次世代データ活用基盤を最短期間で構築
|
|
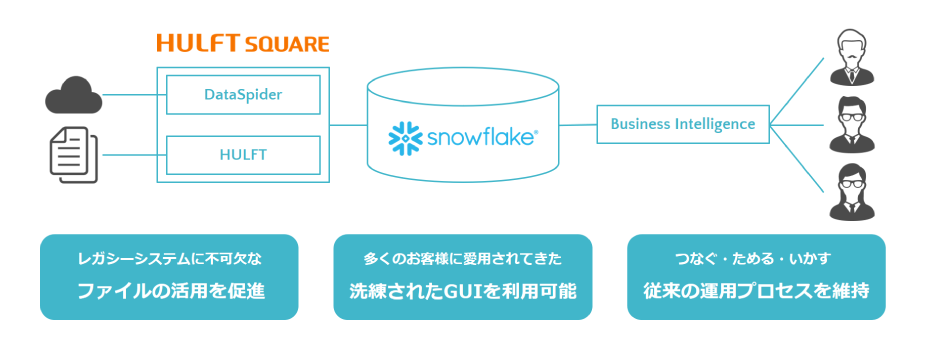
2.既存システム・スキル・運用プロセスを生かしながら、利便性を向上させたい
ファイル転送ツール「HULFT」とデータ連携ツール「DataSpider」が融合した「HULFT Square 」の導入によるレガシーデータスタックの延長線上にあるデータ活用基盤
|
|
参考
|
|
[ 動画 ] 次世代データ活用基盤の勘所を掴む!
|
![[ 動画 ] 次世代データ活用基盤の勘所を掴む!](/pr/west/article/__icsFiles/afieldfile/2024/08/05/202408_POP-UP_column_image9.png)
|
|
[ Webページ ] データパイプラインとは?
|
![[ Webページ ] データパイプラインとは?用途に応じて最速の手法を](/pr/west/article/__icsFiles/afieldfile/2024/08/05/202408_POP-UP_column_image10.png)
本ページの内容やアシスト西日本について何かございましたら、お気軽にお問い合わせください。
