








Glean

Gleanは、全ての従業員がAIの力を活用して、より効率化に生産的に仕事の未来を変革していく「Work AI for all」を標榜しています。Glean Search(横断検索のエンタープライズサーチ)、Glean Assistant(AIアシスタント)、Glean Agents(AIエージェント)で、まったく新しいナレッジディスカバリー体験をご提供します。アシストは、日本初のGleanのパートナーです。
Gleanの機能
Gleanは、企業内のシステム(SaaS)を横断検索して検索結果を生成する「エンタープライズサーチ」のインサイト検索エンジンをベースに、チャットによるAIアシスタント、ナレッジ活用の機能をご利用いただけます。
本ページでは、Gleanの代表的な機能を3つのカテゴリーに分けてご紹介します。



検索
トップページ
企業内の全ての情報にアクセスできる
こちらがGleanのトップページです。トップページでは、知りたいことを素早く検索できると同時に、アクセスするたびに便利で役立つ最新情報を提案してくれます。
GleanはSaaSのクラウドサービスですので、ChromeやEdge、FirefoxなどのWebブラウザーから簡単にアクセスして、業務ポータルとしても使えます。
|
|
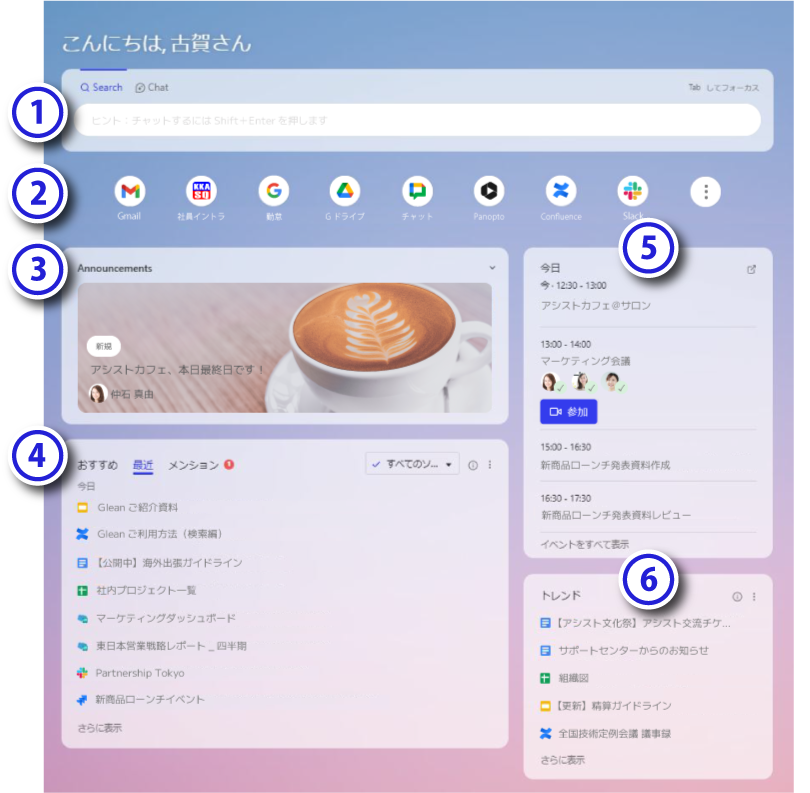
- 最上部の検索ボックスにワードを入力して検索します。
「Search」から「Chat」にそのまま切り替えて、チャットでの対話のやり取りも開始できます。 - よく使うアクセス先へのショートカットを配置できます。
- 従業員へのお知らせをアナウンスとして掲載できます。
- よく使う頻度の高いドキュメントや、自分がメンションされたドキュメントや
アプリケーションが最新の状態で表示されます。 - カレンダーから連携された1日のスケジュールを表示。
この画面からそのままZoomなどのオンライン会議に参加できます。 - 社内でよく閲覧されてトレンドになっている人気コンテンツが表示されます。
検索結果
SaaSを横断検索。クロールした情報を従業員ごとにパーソナライズして表示
Gleanの横断検索では、Microsoft 365やBox、Google Workspace、Slack、Salesforce、ServiceNowなど企業内のデータソースを横断的に検索して瞬時に結果を生成します。
これまでのように、SaaSごとに何度も検索を繰り返す必要はありません。
また、ハッキリ思い出せない検索ワードの不一致によって、必要な情報にたどり着くまでに時間がかかってしまう煩わしさとストレスからも解放されます。
検索結果には、検索した人(従業員)ごとに最適化された情報をAIが生成して一覧に表示しています。
Gleanはこれまでの検索履歴を学習し、さらに、その検索者が所属する組織や、職種、役職などをもとに、同じ立場の人がよく検索したり閲覧している履歴も解析しながら、検索者ごとにパーソナライズした最適な情報にまとめて提供します。
そのため、同じワードの検索であっても、表示される結果は検索した人ごとに、内容も並び順も異なります。
検索者が必要とする情報をGleanがまとめて提案してくれるため、今までなら知り得なかったインサイトに素早く簡単にたどりつくことができます。
|
|
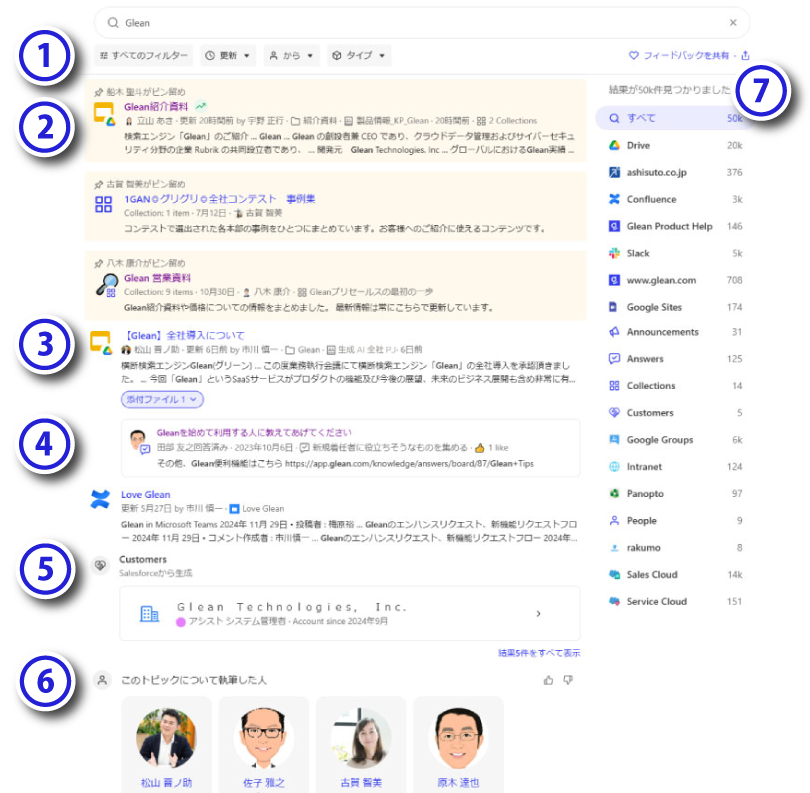
- フィルター検索結果に対して、日付、作成者(発言者)、ファイル形式、コンテンツの場所などの条件で絞り込めます。
- ピン留め特定のワードで検索された際に、検索結果のトップに固定して表示します。表示先は全社のほか、部署を指定した範囲設定も可能です。
-
検索結果検索窓に入力されたワード(クエリ)から、接続しているSaaS内のコンテンツを横断的に検索した結果を表示。表示するコンテンツや表示順は、検索者ごとにパーソナライズされています。
冒頭のアイコンで、どのSaaSにあるコンテンツかがひとめでわかります。 - Answers検索ワードに関連したAnswersが表示されます。(⇒ Answersについてはこちらから)
- 顧客情報検索ワードに関連した顧客情報がある場合は、Salesforceからコンテンツを表示します。
- People検索ワードに関連して詳しい情報を持つ有識者を教えてくれます。
- 検索結果のソース検索ワードでヒットしたコンテンツをSaaSごとに表示。どこにどれだけの情報量があるのかがわかります。
Gleanは、コネクターを介して100以上のアプリケーションとの豊富な接続を確立します。 SaaSなどの各種アプリケーションに加え、APIを通したカスタム接続、外部サイトURLの登録、個人のブラウザー履歴も検索可能です。
<代表的な接続先>
- Box
- Confluence
- Gmail
- Google Calender
- Google Drive
- Google Sites
- Jira
- Notion
- OneDrive
- Outlook
- Panopto
- Salesforce
- ServiceNow
- SharePoint
- Slack
- Tableau
- Teams
- Zendesk
チャット
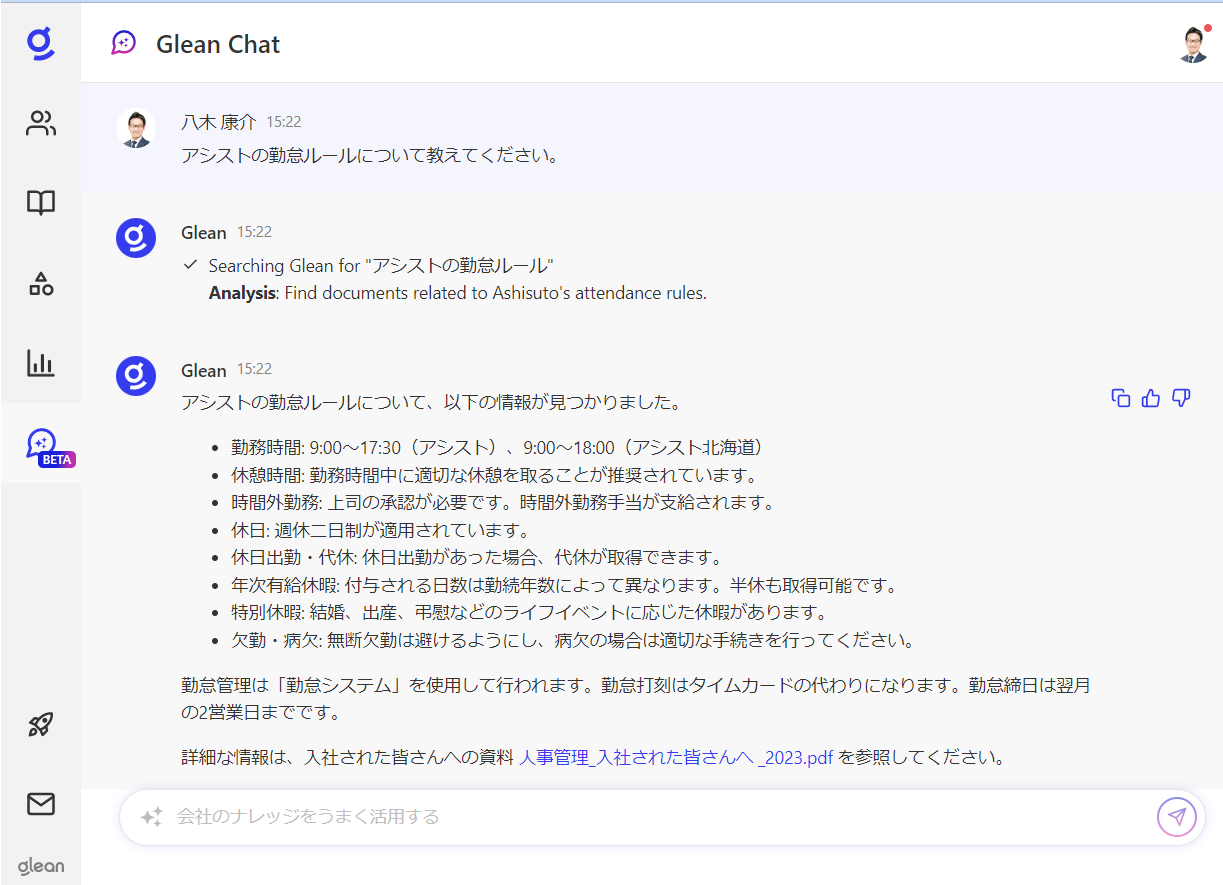
QA、質問への回答
チャットで質問すると回答を生成
チャットで質問すると、社内のデータを横断検索して回答を生成します。
複雑な質問であっても、質問の意図をGleanが読み解き、わかりやすく回答します。
例えば下記のような勤怠ルールについて知りたいときには、総務部のイントラにアクセスしてメニューからたどって情報を探すような従来の調べ方ではなく、Gleanから質問してGleanの中で回答を得て次のアクションを起こせるようになります。
|
|
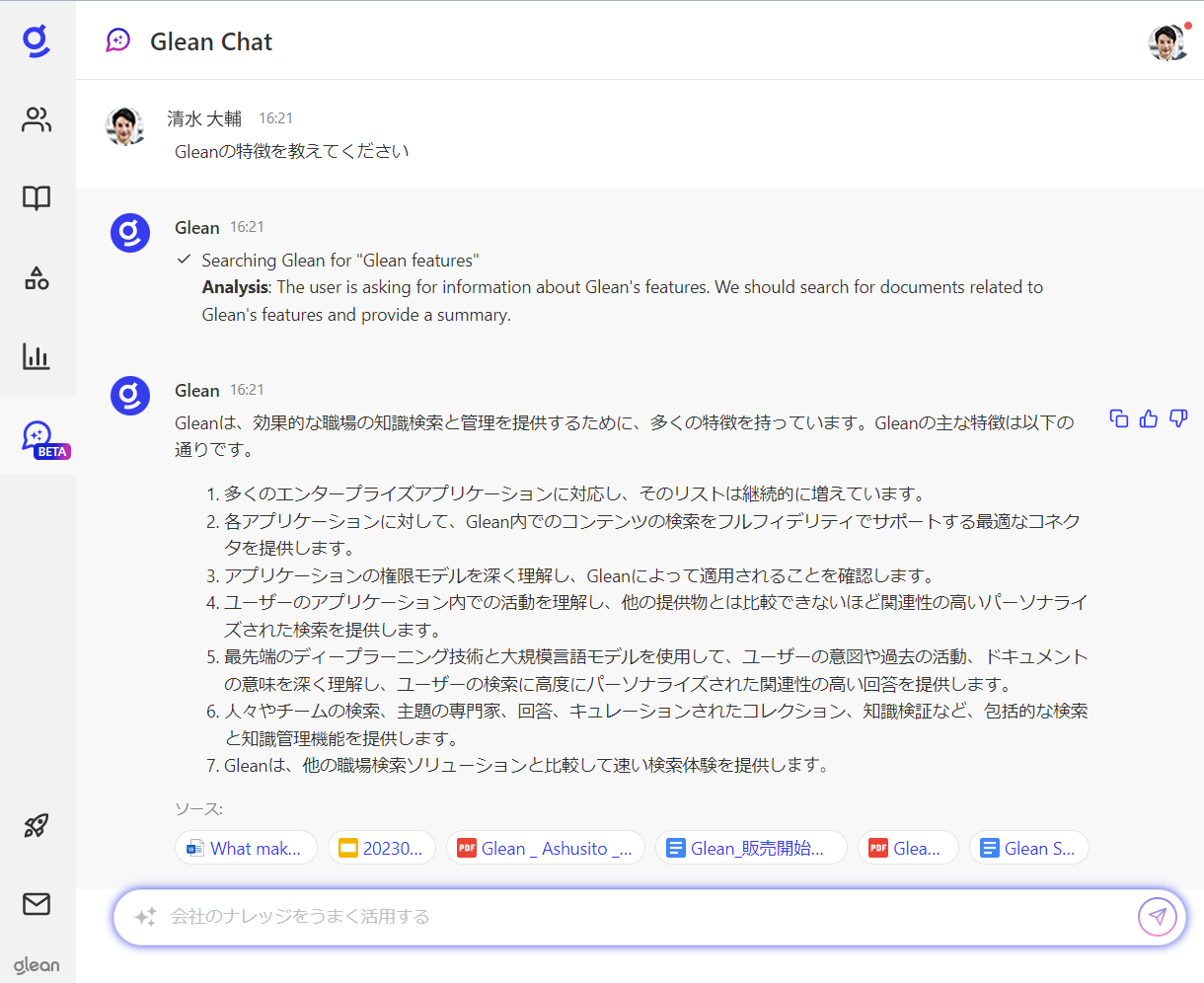
要約、サマリー
チャットで問い合わせると要約を生成
問い合わせに対する回答の生成も可能です。
関連するデータを収集、要約してわかりやすく説明します。
回答結果には、関連したドキュメントやリンクも併せて表示されます。より詳しく調べたいときには、この画面から簡単にアクセスすることができます。
|
|
文章の作成、ライティング
メールや原稿のライティングも即座に
メールや原稿など文章の作成ができるため、短時間で下書きを準備することができます。
顧客向けのメールやプレスリリースの発表原稿、Webサイトのページ本文など、トピックや条件などを指定すると、社外のデータはもちろん、社内のあらゆるデータを踏まえてライティングしてくれます。
|
|
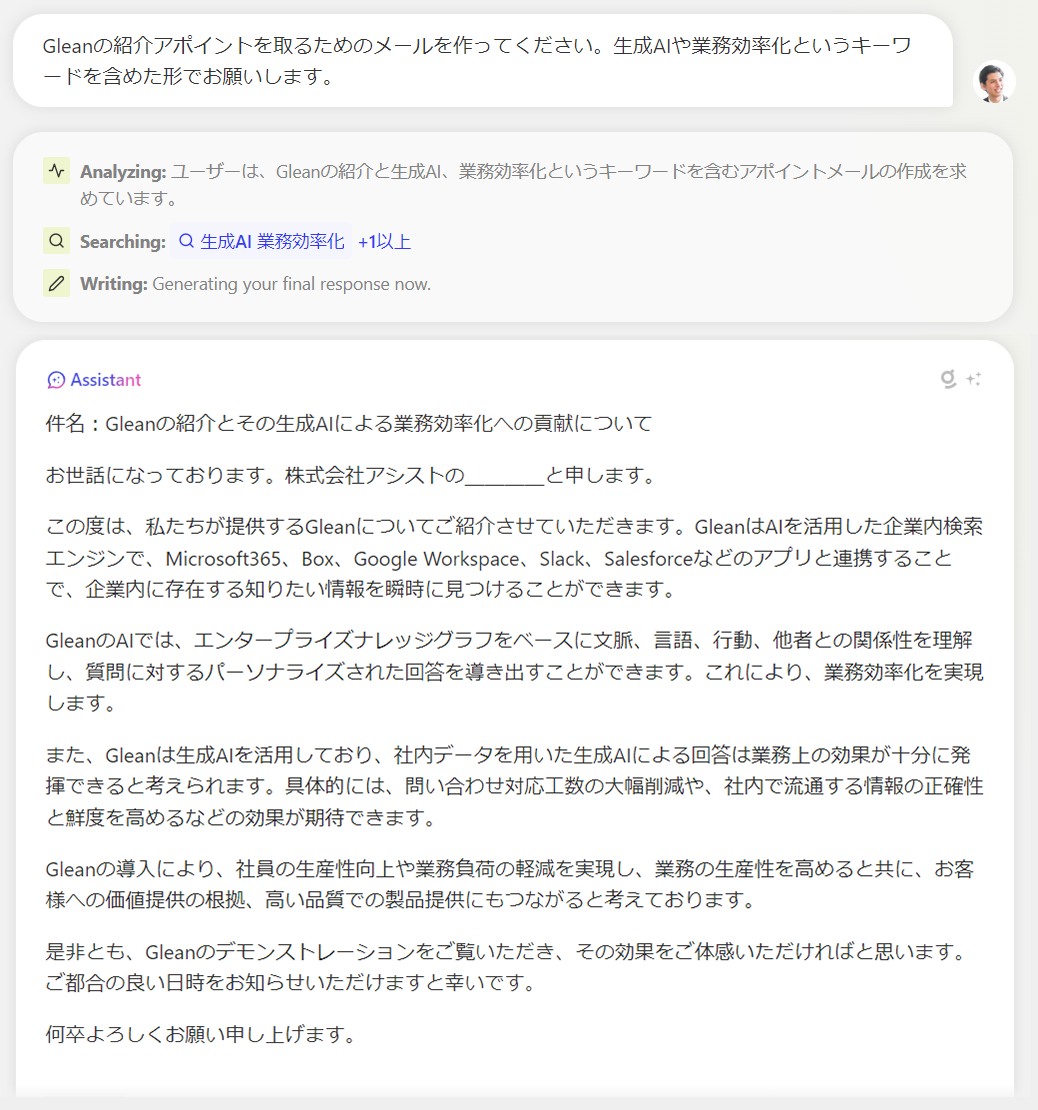
Public Knowledge
パブリックナレッジ、社外の公開情報から回答を生成
Public Knowledgeにモードを切り替えることで、社内の情報からではなく、公開されているパブリックなデータソースをもとに回答を生成します。
パブリックなデータソースは、インターネットに公開されているHTMLをはじめ、静的なコンテンツ(PDF、DOCX、PPTXなど)から情報を取得できます。ページの指定や、ドキュメントを複数アップロードして質問することもできます。
これにより、企業内のデータにアクセスできない場合でも、外部の知識を活用して有用な情報を得られます。
セキュリティとガバナンスの観点からは、このPublic Knowledgeの機能は、内部データの露出リスクを軽減するために、公開された情報のみを使用することができ、URLのセキュリティチェックやWebリスク評価を行って安全なリンクのみを解析します。
GleanのPublic Knowledge機能は、企業内外の情報を統合し、検索者が必要とする情報を迅速かつ安全に提供することができます。
|
|
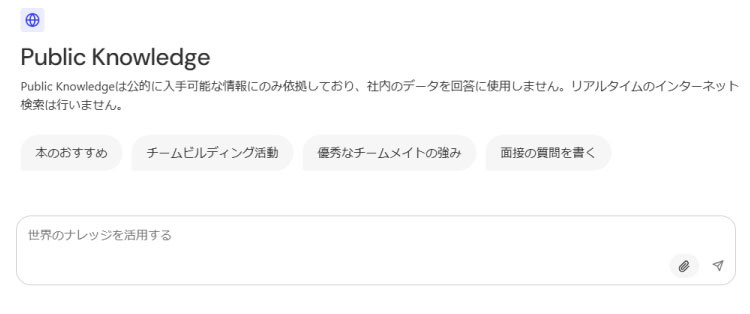
Prompts
プロンプトライブラリ、業務に役立つプロンプトを公開して共有
プロンプトライブラリでは、自分が作成したプロンプトを公開したり、同僚が共有したプロンプトを閲覧・検索して利用することができます。
プロンプトは完成された状態で公開されているため、特定の情報を入力するだけで、事前に定義されたプロンプトを簡単に実行して回答を得られます。
例えば「顧客訪問の準備」のプロンプトでは、フィールドに顧客名を入力して実行するだけで、その顧客について知っておくべき情報が網羅的に生成されます。情報の取得範囲を指定することもでき、このプロンプトでは、Confluence、Googleドライブ、Gmail、Salesforceから、その検索者がそれぞれのSaaSにアクセスできる権限範囲の中から情報を取得し回答が生成されるようになっています。
|
|
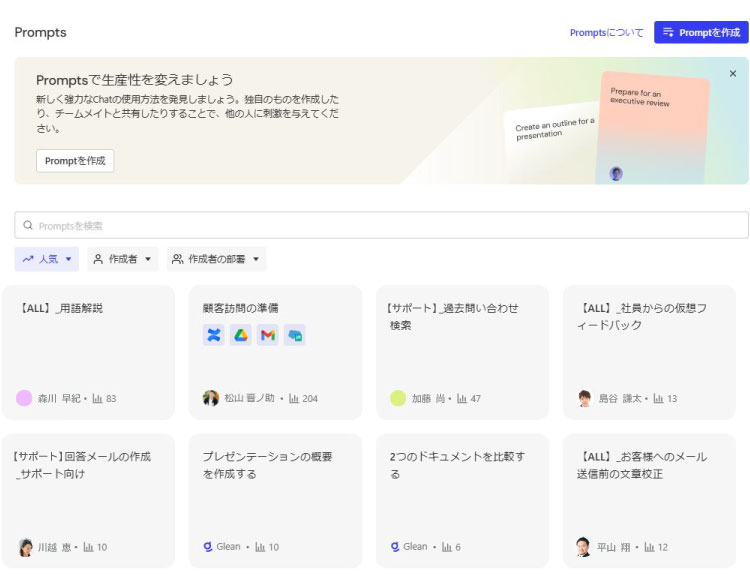
Apps
Appsライブラリ:業務特化のアプリケーションをノーコードで作成して公開
Appsは、特定の業務やニーズに対応するチャット型のアプリケーションです。
各種の業務用途に合わせて、特定分野に限定した情報ソースの参照範囲を指定したり、適切な応答指示などをコーディングすること無く数ステップで簡単に作成できます。
ユーザーの参照権限は踏襲されているため、アプリケーションごとの設定やメンテナンスは不要です。
<利用例>
| 人事や総務などのバックオフィス | 勤怠や精算、備品購入などの質問に特化したApps 社内規定や公式ドキュメントをもとに質問に回答する |
|---|---|
| 研修 | 研修テキストをもとに、演習問題を作成するApps |
| 技術サポート | 特定バージョンのマニュアルをもとに、技術QAを行うApps |
Appsライブラリでは、自分が作成したAppsを公開したり、チームメイトが共有したAppsを閲覧・検索して利用することができます。
|
|
ナレッジ
Collections
コレクション:業務特化のアプリケーションをノーコードで作成して公開
コレクションはリンク集のような使い方ができ、特定のトピックやテーマについて、関連するドキュメントやリンクを簡単にまとめられる方法です。
チームや組織、プロジェクト、業務単位などでコレクションページを作成し、業務でよく使うドキュメントやリンクをキュレーションしておくと、素早くアクセスして着手できるようになります。
例えば、新製品のリリースやイベント開催など短期間で集中的にタスクが発生するケースでの利用や、入社後のオンボーディング、勤怠や精算にまつわるコレクション、チームでよく使うドキュメント集のようなコレクションなどの用途で便利に使うことができます。
|
|
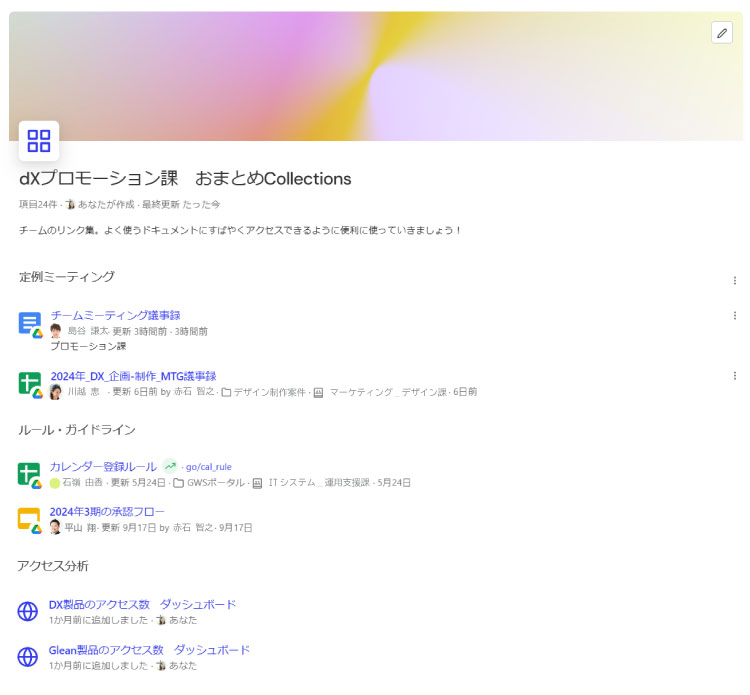
Answers
アンサーは、よくある質問とその回答を事前に登録しておくことができる機能です。
特定のテーマや業務でボードを作り、そのボードに関連するアンサーを登録しておくと、ユーザーが検索した際に適切な回答を迅速に提供することができます。
FAQ形式で回答を示すことができるため、よくある質問をまとめておき閲覧してもらうことで問い合わせを減らし自己解決を促したり、登録された回答は、Gleanの検索結果にも表示されるため、ユーザーは必要な情報をすぐに見つけることができます。
|
|
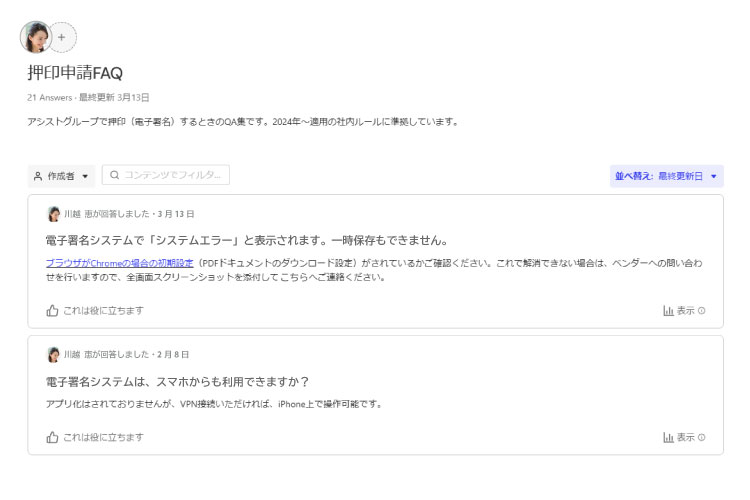
Announcements
アナウンスメントは、Gleanのトップページ(ホーム画面)にお知らせを表示して、重要な情報を周知するための機能です。
掲示板のような使い方で、表示先の範囲を全社、部署、または特定の勤務地単位で指定することができ、期間の指定も可能です。重要な情報を確実に伝えることができるようになります。
|
|
Pins
ピン留めは、重要な情報や頻繁にアクセスするコンテンツを簡単に見つけられるように固定表示できる機能です。
検索ワードに応じて表示を切り替えられ、表示範囲は組織単位や全社を指定できます。
|
|
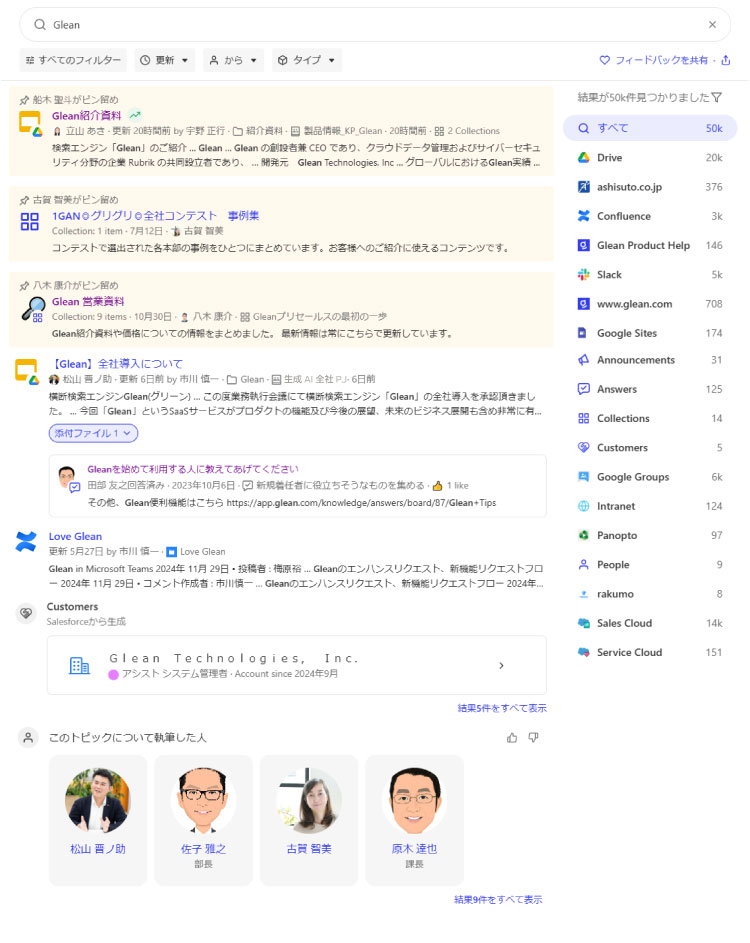
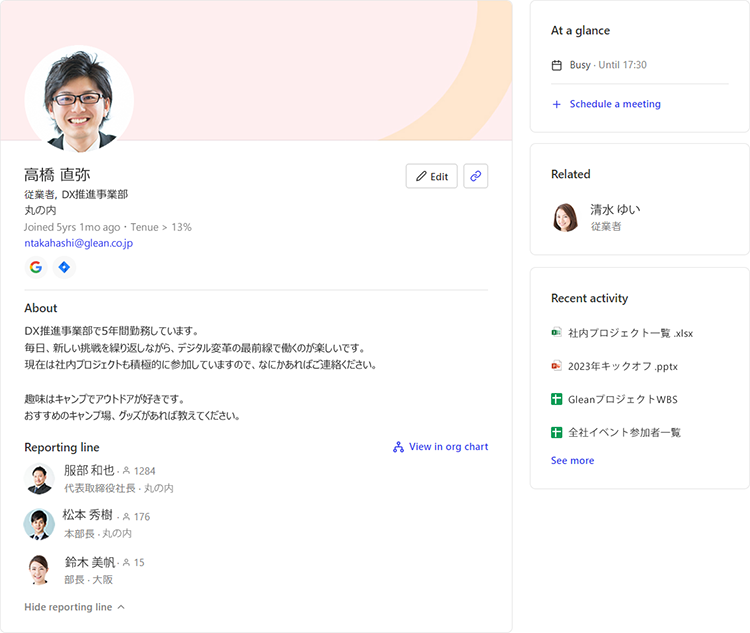
People
詳しい人が分かるKnowWho
検索結果には、それについて詳しい人は誰なのかも表示します。(検索結果画面の右側「People」に表示されます)
その検索に関連したドキュメントを多く作成していたり、発信量の多さなどから、それについて詳しい人をGleanが推定して導き出してくれます。
検索者は「誰が詳しいか(KnowWho)」を知ることができるため、その人に直接コミュニケーションを取って解決を図れるようになります。知識を介して従業員同士のつながりを広げ、社内でのナレッジコラボレーションを実現します。
|
|
Glean資料ライブラリのご案内
|
|
資料ライブラリでは、Gleanについての資料や動画をご覧いただけます。 |

|
|

お問い合わせ
Gleanのご導入を検討されている方、アシストのご提案・ご支援サービスにご興味のある方はこちらからお問い合わせください。
※お問い合わせの前に、「よくあるご質問
」をご確認ください。
情報活用に関するその他の課題
- SAP S/4HANAのデータ活用基盤を短期間で構築する手法とは?
- SaaSをまるっと生成AIで検索!100超のSaaSアプリも瞬時に横断検索して、回答生成できる最強の使い方とは
- データパイプラインとは?用途に応じて最速の手法を
- Boxをまるっと生成AIで検索!Boxとあわせて100超のSaaSアプリも瞬時に横断検索して、回答生成できる最強の使い方とは
- Zoom会議の録画「後」をもっと簡単に!| Panoptoの新しい解決策
- DXや人材育成に欠かせないリスキリングとは? 動画コンテンツが早期育成のカギ
- Zoom会議の録画方法|ミーティングを録画したら保存や共有はどうする?
- YouTubeは企業の動画活用に最適なのか?
- ローコード開発のススメ!ローコード開発ツールやリーンキャンバスについてわかりやすく解説
- 契約書のリーガルチェックをAIで自動化し、法務業務を効率化したい
- RPAも、人と同様にミスをする。
- データマネタイズによる競争力強化とは
- 申込や申請時に多い不備を削減し、受付業務を効率化したい
- 軽減税率対応の今だからこそ、全社共通の税率計算エンジンを
- 入金消込を自動化・効率化し、経理部の生産性を向上させたい
- バックオフィス業務を自動化して生産性を向上したい
- 生命保険 引受業務を最大限に効率化する BRMS
- AIで履歴書やエントリーシートを自動チェックし、採用活動のさらなる迅速化と正当化を実現
- RPA?DXを見据えて業務を自動化し、組織の生産性を高めるために必要なこと
- 資産運用での法令や社内規定の遵守を徹底したい
- コンフィグレータで正確な製品構成を作成
- 料金誤請求リスクをルールベースAIが撲滅
- セルフサービスBIの導入
- BIシステムのリプレース
- 超Excel分析ツールの活用
- RPA+AI連携(インテリジェントオートメーション)で、業務をシームレスに自動化
- セルフサービス型BIツールとビッグデータを組み合わせて情報活用をさらに加速させたい
- 業務レポート作成のスピードアップと脱「属人化」
- Excel(エクセル)とデータベース(db)の連携を完全自動化!
- CRMへのデータ連携
- レガシーシステム~マイグレーションにおける処理性能の維持~
- サイトリニューアルの要件定義の流れは? RFP(提案依頼書)に盛り込む内容を解説
- サイトリニューアルの手順を解説! リニューアルのタイミングや注意点とは
- Salesforceとのデータ連携がよくわかる!
- AWSとのデータ連携がよくわかる!
- SAPとのデータ連携がよくわかる!
- バッチ処理の高速化
- kintoneと他システムのデータ連携(API連携)
- バッチ処理のパフォーマンス改善
- Lotus Notesデータの二次利用
- DB内で実装したバッチ処理の遅延
- ActiveDirectoryと各システムのユーザID統合
- ビッグデータ・プラットフォームに簡単に接続したい
- IoTにおけるデータ連携
- Salesforceにリアルタイムにアクセスしてデータを活用したい
- BRMSツールによるシステム開発で保守性と品質を高める
- デジタルトランスフォーメーションとは?AIによる業務判断の自動化とDXの関係
- 【CMS】Webサイトの改善/課題解決






